light PosgreSQL ORM with JSON model config

Project description
- Installation
- Configuration
- Prepare
- Class
- Model
- Add
- Get
- Save
- All
- Delete
- Filter
- Custom
- Table
- Fields
- Joins
Installation
pip install psycopg2-binary
pip install pgsql-table
Configuration
Import module:
import sql
Set log level to debug to see generated queries
import logging as log
log.basicConfig(level=log.DEBUG)
Configure default database connetion:
sql.db = sql.Db('dbname=postgres user=postgres password=1234 host=127.0.0.1 port=5432')
You can also set default schema for a default model:
sql.Table.schema = 'demo'
That is enough for a setup, but below we describe advanced mechanics of database connection:
Connetion is made before the very first query to database. By default 20 thread safe connection pool is reserved sql.Db('..', size=20). To establish connection manually call sql.db.init(). sql.db.get() gets free database connection from the pull, after finishing a job the connection is returned back to the connection pull by calling sql.db.put(connection).
Alternatively every model can have its own database connection and its own schema, it is achieved by extending sql.Table, the default model class:
import sql
class Users(sql.Table):
db = sql.Db('host=198.168.0.1 dbname=core')
schema = 'site'
name = 'users'
fields = {}
class Transactions(sql.Table):
db = sql.Db('host=198.168.0.2 dbname=reporting')
schema = 'financial'
name = 'transaction'
fields = {}
Prepare
Let us create a demo schema for a small tutorial:
sql.query('DROP SCHEMA IF EXISTS demo CASCADE')
sql.query('CREATE SCHEMA IF NOT EXISTS demo')
We will have two tables: users and groups, users table will reference groups table to showcase some joins
sql.query("""
CREATE TABLE IF NOT EXISTS demo.groups (
id SMALLSERIAL PRIMARY KEY NOT NULL,
name VARCHAR(32)
)""")
sql.query("""
CREATE TABLE IF NOT EXISTS demo.users (
id BIGSERIAL PRIMARY KEY NOT NULL,
username VARCHAR(64) NOT NULL,
fullname VARCHAR(64) NOT NULL,
password CHAR(32) NOT NULL,
status VARCHAR(8) NOT NULL,
group_id SMALLINT REFERENCES demo.groups(id),
created_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW()
)""")
Class
Once we have tables we create classes for representing users and groups table rows as objects:
class Group:
def __init__(self):
self.id = None
self.name = None
class User:
def __init__(self):
self.id = None
self.username = None
self.fullname = None
self.status = None
self.created_at = None
Also defining properties is not required as orm creates object properties on the fly, but having them is much more descriptive.
Model
Let us pause a bit to create a friendly md5 hash function, it might come handy later for hashing passwords:
import hashlib
def md5(plain):
return hashlib.md5(plain.encode()).hexdigest()
Storing passwords in md5 hashs is not recomended in real world scenario, you should use bcrypt instead.
We extend sql.Table for our Groups model. The naming goes like this: Class name in singular [ Group ] and model name is in plural [ Groups ] as Groups model produces Group class objects:
class Groups(sql.Table):
name = 'groups'
type = Group
fields = {
'id': {'type': 'int'},
'name': {}
}
Where type = Group attaches previously created class to a model.
And Users model:
class Users(sql.Table):
name = 'users' # Actual table name
type = User
fields = {
'id': {'type': 'int'},
'username': {}, # Default is string
'fullname': {},
'password': {'encoder': md5}, # md5 function will encode values for this field
'status': {'options': ['active', 'disabled']}, # Only this values are allowed for this field
'group_id': {'type':'int'},
'created_at': {'type': 'date'}
}
joins = {
'group': {'table':Groups, 'field':'group_id'}
}
Add
Create some groups by simply calling Groups.add and passing dict type object, where keys of the object are Groups.fields dict keys:
manager = Groups.add({'name':'Manager'})
customer = Groups.add({'name':'Customer'})
Method will generate and run following query:
WITH "groups" AS (
INSERT INTO "demo"."groups" (name)
VALUES ('Manager')
RETURNING groups.id, groups.name )
SELECT groups.id, groups.name
FROM "groups"
Newly created row is selected in the same query using RETURNING and converted into Group object, manager now holds {'id':1, 'name':'Manager'}
Create users
user = Users.add({
'username': 'john',
'fullname': 'John Doe',
'password': '123',
'status': 'active',
'group_id': manager.id
})
Following query will be generated:
WITH "users" AS (
INSERT INTO "demo"."users" (username, fullname, password, status, group_id)
VALUES ('john', 'John Doe', '202cb962ac59075b964b07152d234b70', 'active', '1')
RETURNING users.id, users.username, users.fullname, users.password, users.status, users.group_id, users.created_at )
SELECT users.id, users.username, users.fullname, users.password, users.status, users.group_id, users.created_at,groups.id, groups.name
FROM "users"
LEFT JOIN "demo"."groups" ON "groups"."id"="users"."group_id"
Let us create a pretty print function
import json
def pprint(object):
print(json.dumps(object, indent=4, default=lambda x: x.__dict__ if hasattr(x, '__dict__') else str(x)))
Actually newly created user is an object of a class User, but pprint will visualise it like a dictionary:
pprint(user)
Outputs:
{
"id": 1,
"username": "john",
"fullname": "John Doe",
"status": "active",
"created_at": "2020-11-14 03:34:46.913425",
"password": "202cb962ac59075b964b07152d234b70",
"group_id": 1,
"group": {
"id": 1,
"name": "Manager"
}
}
Notice that password we input was plain '123' string and in query it is md5 hash thanks to encoder defined to that field 'password':{'encoder': md5}.
Here we add some more users for scientific purposes:
import random
random_string = lambda: ''.join(random.choice('abcdefghijklmnopqrstwxyz') for j in range(random.randrange(3, 9)))
log.getLogger().setLevel(log.INFO)
for i in range(300):
Users.add({
'username': random_string(),
'fullname': random_string().capitalize() + ' ' + random_string().capitalize(),
'group_id': random.choice((manager.id, customer.id)),
'password': '123',
'status': 'active'
})
log.getLogger().setLevel(log.DEBUG)
Get
user = Users.get(1)
Wich will get user by following query and because we defined a join on Groups model, query will contain LEFT JOIN on groups table:
SELECT users.id, users.username, users.fullname, users.password, users.status, users.group_id, users.created_at,groups.id, groups.name
FROM "demo"."users"
LEFT JOIN "demo"."groups" ON "groups"."id"="users"."group_id"
WHERE
"users"."id"='1'
AND 1=1
Let us look inside User object
pprint(user)
Which outputs:
{
"id": 1,
"username": "john",
"fullname": "John Doe",
"status": "active",
"created_at": "2020-11-14 03:34:46.913425",
"password": "202cb962ac59075b964b07152d234b70",
"group_id": 1,
"group": {
"id": 1,
"name": "Manager"
}
}
If you look closer you see that even user.group is an object, actually it is an object of the Group class.
Save
Saving happens via id and dict corresponding fields and values, save returns updated object of the user:
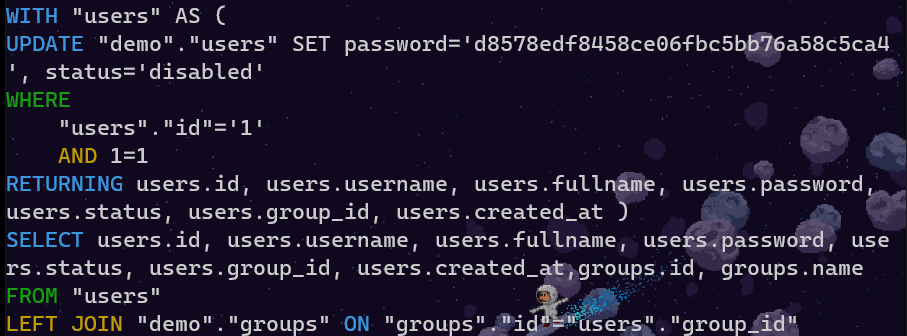
user = Users.save(1, {'status':'disabled', 'password':'qwerty'})
While savingi you pass only fields which you inted to update, at least one field is required.
Generated query:
WITH "users" AS (
UPDATE "demo"."users" SET password='d8578edf8458ce06fbc5bb76a58c5ca4', status='disabled'
WHERE
"users"."id"='1'
AND 1=1
RETURNING users.id, users.username, users.fullname, users.password, users.status, users.group_id, users.created_at )
SELECT users.id, users.username, users.fullname, users.password, users.status, users.group_id, users.created_at,groups.id, groups.name
FROM "users"
LEFT JOIN "demo"."groups" ON "groups"."id"="users"."group_id"
Everything happens in same query: update, select and also join on groups table
user in case of success now contains actually updated object:
pprint(user)
{
"id": 1,
"username": "john",
"fullname": "John Doe",
"status": "disabled",
"created_at": "2020-11-14 03:34:46.913425",
"password": "d8578edf8458ce06fbc5bb76a58c5ca4",
"group_id": 1,
"group": {
"id": 1,
"name": "Manager"
}
}
All
users = Users.all(filter={
'id': {
'from':1,
#'to': 300
},
'status':'active',
'group':{
'id': manager.id
}
},
search={
'username': 'j',
'fullname': 'j'
},
limit=2,
order={'field':'username', 'method':'asc'}
)
Query:
SELECT users.id, users.username, users.fullname, users.password, users.status, users.group_id, users.created_at,groups.id, groups.name
FROM "demo"."users"
LEFT JOIN "demo"."groups" ON "groups"."id"="users"."group_id"
WHERE
(users."username" ILIKE '%j%'
OR users."fullname" ILIKE '%j%')
AND (users."id">='5'
AND users."status"='disabled'
AND groups."id"='2')
ORDER BY users."id" DESC
Difference between filter and search is that search consists with only OR criterias and filter with AND.
pprint(users)
[
{
"id": 122,
"username": "ahdcjq",
"fullname": "Hbf Ngggzmce",
"status": "active",
"created_at": "2020-11-14 04:48:00.857954",
"password": "202cb962ac59075b964b07152d234b70",
"group_id": 1,
"group": {
"id": 1,
"name": "Manager"
}
},
{
"id": 51,
"username": "alabm",
"fullname": "Ipb Ttjkxc",
"status": "active",
"created_at": "2020-11-14 04:48:00.612368",
"password": "202cb962ac59075b964b07152d234b70",
"group_id": 1,
"group": {
"id": 1,
"name": "Manager"
}
}
]
Delete
Users.delete(3)
DELETE
FROM "demo"."users"
WHERE
1=1
AND "users"."id"='3'
Filter
In addition with Table.all, Table.filter has paging and result is object of sql.Result:
result = Users.filter(page=4,
limit=3,
order={'method':'asc'},
filter={'status':'active', 'group':{'id': customer.id}},
search={'username':'j', 'fullname':'j'})
SELECT users.id, users.username, users.fullname, users.password, users.status, users.group_id, users.created_at,groups.id, groups.name, COUNT(*) OVER()
FROM "demo"."users"
LEFT JOIN "demo"."groups" ON "groups"."id"="users"."group_id"
WHERE
(users."username" ILIKE '%j%'
OR users."fullname" ILIKE '%j%')
AND (users."status"='active'
AND groups."id"='2')
ORDER BY users."id" ASC
LIMIT '3' OFFSET '9'
Selecting 3 rows starting from 9th row as we have per page limit=3 from 9-12 will be items for 4th page
pprint(result)
{
"total": 80,
"items": [
{
"id": 42,
"username": "xkeosa",
"fullname": "Hxkqrfz Wxjhbalf",
"status": "active",
"created_at": "2020-11-14 04:50:37.132306",
"password": "202cb962ac59075b964b07152d234b70",
"group_id": 2,
"group": {
"id": 2,
"name": "Customer"
}
},
{
"id": 50,
"username": "lejfe",
"fullname": "Npowa Sllgq",
"status": "active",
"created_at": "2020-11-14 04:50:37.156698",
"password": "202cb962ac59075b964b07152d234b70",
"group_id": 2,
"group": {
"id": 2,
"name": "Customer"
}
},
{
"id": 52,
"username": "pofmeyp",
"fullname": "Xpm Zxfthj",
"status": "active",
"created_at": "2020-11-14 04:50:37.161491",
"password": "202cb962ac59075b964b07152d234b70",
"group_id": 2,
"group": {
"id": 2,
"name": "Customer"
}
}
]
}
Custom
But if you want to create some custom query Model class helps a lot with query templating and converting select result into objects of User:
db = None
try:
db = Users.db.get()
cursor = db.cursor()
cursor.execute(*sql.debug(f"""
SELECT {Users.select()}
FROM {Users}
WHERE
{Users('username')}=%s
AND {Users('password')}=%s
""",
('John', md5('123'))))
if cursor.rowcount > 0:
# Create User object
user = Users.create(cursor.fetchone())
pprint(user)
finally:
Users.db.put(db)
Table
import sql
class Profile(sql.Table):
# Override database connection default is sql.db = sql.Db('...')
db = sql.Db(...)
# Override default schema, default is None i.e. public
schema = 'site'
# Actual table name
name = 'user_profile'
# Primary key of table, default is 'id'
id = 'user_id'
# Definition of table fields
fields = {}
# Definition of table joins
joins = {}
Fields
Field types are: string(default), int, float, bool, date and json
Field type is specified by 'type': 'int'
Common field options are:
import sql
Table fields(sql.Table)
fields = {
'name': {
'type': 'int',
'array': True,
'options': [1, 2, 3, 4, 5], # Only this values are accepted anything else causes exception
'field': 'actual_table_field_name', # default is same as field key
'encoder': lambda x: x * 2, # Encoder is called right before insert or update value after validation
'decoder': lambda x: x / 2, # Decoder is called after select,
'select': True, # Default is True
'insert': True, # Default is True
'update': True, # Default is True
'null': False, # Allow None values in inserts and updates and cast them into null
}
}
If 'null' is True then None values are transfered as null, by default None value fields are ignored in inserts and updates as 'null' is False.
Json field requires keys setting:
import sql
class Table(sql.Table):
fields = {
'title': {
'type': 'json',
'keys': ['en', 'ka', 'ru'] # This keys are used for ordering by json field
}
}
# This is how table is ordered with json field key
Table.filter(order={'field':'title.en'})
Joins
import sql
class Table1Class:
def __init__(self):
self.id = None
class Table2Class:
def __init__(self):
self.id = None
self.table1_id = None # This just contains table1_id
self.table1 = None # This will contain Table1Class object
class Table1Model(sql.Table):
id = 'id'
type = Table1Class
fields = {
'id': {'type': 'int'}
}
class Table2Model(sql.Table):
type = Table2Class
fields = {
'id': {'type': 'int'}
'table1_id': {'type': 'int'}
}
joins: {
'table1': {'table': Table1Model, 'field': 'table1_id'}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pgsql-table-0.5.tar.gz.
File metadata
- Download URL: pgsql-table-0.5.tar.gz
- Upload date:
- Size: 12.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.1.0 requests-toolbelt/0.9.1 tqdm/4.42.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
805fb9bc149b09697d434e2faf25e2fac73aaf8167dd15ee9b7f0290897ff61d
|
|
| MD5 |
ba40231a2eba6271fa4c74d117fc38ba
|
|
| BLAKE2b-256 |
012ee3964caf929e0f1365d0e02b11a5fa458de58b9b5ce1e1914e767fbe1470
|
File details
Details for the file pgsql_table-0.5-py2.py3-none-any.whl.
File metadata
- Download URL: pgsql_table-0.5-py2.py3-none-any.whl
- Upload date:
- Size: 12.7 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.1.0 requests-toolbelt/0.9.1 tqdm/4.42.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f68b07bb24e05e30afe2525bf070c0d642e2c87830318d845c58ff015e4d0e9f
|
|
| MD5 |
5a16ed322d122db1cb857a5ace45ab6e
|
|
| BLAKE2b-256 |
894e72ea0c0ea398a5ad1d88ce69203e369c2c3c8ec4b44c8d9c60011cac02af
|







