A python package that allows for the easy creation of LSTM text prediction datasets

Project description

Predictionary
A python package that allows for the easy creation of LSTM text prediction datasets. With just a few lines of code, you can begin training your network on PDFs, .txt files, and UTF-8 hosted raw text online!
🚩 Table of contents
Install
The easiest way to install this package is to simply use pip
pip install predictionary
You could also just as easily clone this repo.
Import
The following lines import all classes and methods from the Predictionary package.
from predictionary.source import load_raw_text
from predictionary.vata import process_text, word_to_int, int_to_word, make_data, make_sentences, encode_sentences
from predictionary.visualize import make_prevelence_dict, plot_top
Let's go through the features, one method at a time.
Source
-
load_raw_text
The Source class has only one method, "load_raw_text." This method serves to pull in the raw text data from the web, PDFs, or local text files. It can also merge the data, or return a list of separated data.
Arguments
- URL(s) - The first argument to pass is a list of the URLs or paths of the file(s) you want to pull from
- methods - This variable corresponds to the type of your source, for example "web" means the first value passed will be a list of URL(s), "text" will be passed local .txt file paths, and "pdf" will be passed the path(s) of local .pdf files.
- merge_data - The final variable to set is merge_data, if set if "True" or left un-instantiated, if will merge all the sources in the list passed and return a single string at the end. If set to "False", if will return a list of length len(URL(s)), with each source's data
Note Be sure to enter the correct identifier in the "method" variable when using "load_raw_text."
The web value allows us to pull data from hosted .txt files such as the ones of project gutenberg.
text = load_raw_text(["https://www.gutenberg.org/files/76/76-0.txt", "https://www.gutenberg.org/files/6130/6130-0.txt"], method="web", merge_data=True)In the example above, we're grabbing data from 2 books hosted on project gutenburg, and telling the package to merge the data from both books. This command will return a single string with our data in it to be processed. If we instead used "merge_data=False", we would be returned a list of 2 such strings that we must then process individually.
This source method allows users to pull in data from their local .txt files.
text = load_raw_text([r'C:\Users\Chuggy\Documents\hello.txt', r'C:\Users\Chuggy\Documents\hello1.txt'], method="text", merge_data=False)In this example we're pulling from two local files, "hello.txt", and "hello1.txt." We're also telling the package to return a 2 element list of the 2 files' data by specifying "merge_data=False."
The final source method allows users to pull data straight from PDFs.
text = load_raw_text([r'C:\Users\Chuggy\Downloads\flashboys.pdf'], method="pdf")Here we are using the default values for merging, so the files would have been merged if we had specified 2 different files, however we only have one here so we're fine. As always, we specify the input method as "pdf", and in this case are returned a string containing the raw text from our source.
Data
-
process_text
This method is the main text "cleaner" of the package. It will take in the raw text data returned by the "Source" class and turn it into either characters or words that have been cleaned (read 'separated') of their punctuation.
Arguments
- text - The first argument to pass is the raw text string that was returned from the "Source" class.
- split_by_words - This argument will determine if the package splits up the text by words or by characters.
- keep_spaces - The final argument in this method determines if the input data should contain spaces, or simply the words / chars.
-
split_by_words = True
Example Usage:
fully_processed_text = process_text(text, split_by_words=True)Returns:
['the', ' ', 'project', ' ', 'gutenberg', ' ', 'ebook', ' ', 'of', ' ', 'adventures', ' ', 'of', ' ', 'huckleberry', ...]The above example is one where we split the raw text from the source into words.
-
split_by_words = False
Example Usage:
fully_processed_text = process_text(text, split_by_words=False)Returns:
['t', 'h', 'e', ' ', 'p', 'r', 'o', 'j', 'e', 'c', 't', ' ', 'g', 'u', 't', 'e', 'n', ...]In this example we split the raw text by characters.
-
split_by_words = True, keep_spaces=False
Example Usage:
fully_processed_text = process_text(text, split_by_words=False)Returns:
['the', 'project', 'gutenberg', 'ebook', 'of', 'adventures', 'of', 'huckleberry', ...]In this example we wanted just the words with no spaces.
-
word_to_int
This method serves to create a dictionary for the word_to_int process necessary for our data to flow into an LSTM architecture.
Arguments
- fully_processed_text - Takes in the fully processed text returned by the process_text method.
Example Usage:
word_to_int_dictionary = word_to_int(fully_processed_text)Returns:
{'': 0, '\r': 1, '\n': 2, ' ': 3, '!': 4, '#': 5, '$': 6, '%': 7, ...} -
int_to_word
This method serves to create an inverse dictionary from the word_to_int method for turning the argmax of the model's one-hot array outputs back into chars/words.
Arguments
- word_to_int_dictionary - Takes in the word_to_int_dictionary from the word_to_int method and reverses it.
Example Usage:
int_to_word_dictionary = int_to_word(word_to_int_dictionary)Returns:
{0: '', 1: '\r', 2: '\n', 3: ' ', 4: '!', 5: '#', 6: '$', 7: '%', ...} -
make_data
This method is the main workhorse for this Data class. It serves to take in the processed text from the process text method and turn it into fully trainable LSTM text prediction datasets.
Arguments
- fully_processed_text - Pass in the fully processed text from the process_text method.
- int_to_word_dictionary - Pass in the int_to_word_dictionary from the int_to_word dictionary creating method.
- sequence_length - The length of chars/words you want each training example to be.
- X_one_hot - A boolean value to determine if you want your training sequences to be passed to your network in the form of ints or one-hot-arrays.
- Y_one_hot - A boolean value to determine if you want your target data to be passed to your network in the form of ints or one-hot-arrays.
- split_train_test - A Boolean that if set to True, the method will pass back data split into X_train, Y_train, X_test, Y_test form, OR if set to False, will pass back data in the X, Y form.
- test_train_split_ratio - A float value that allows the user to set the ratio of testing data to training data.
- save_locally - A boolean value that if set to True, will save created arrays in .npy format locally.
Example Usage
X_train, X_test, y_train, y_test = make_data(fully_processed_text, int_to_word_dictionary, sequence_length=68, X_one_hot=True, split_train_test=True, test_train_split_ratio=0.33, save_locally=False)Returns:
What it Actually Returns: X_train, X_test, y_train, y_test **The Features of What it Returns***: Number of Train Examples: 385072 Number of Test Examples: 189663 X_train.shape: (385072, 69, 60) X_train[0]: [[0. 0. 0. ... 0. 0. 0.] [0. 0. 0. ... 0. 0. 0.] [0. 0. 0. ... 0. 0. 0.] ... [0. 0. 0. ... 0. 0. 0.] [0. 0. 0. ... 0. 0. 0.] [0. 0. 0. ... 0. 0. 0.]] y_train.shape: (385072, 60) y_train[0]: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]In the above example we created our data to contain 68 chars/words per sequence, be one-hot encoded, have a 33% test to train data ration, and not save to our local machine.
Example Usage
X, y = make_data(fully_processed_text, int_to_word_dictionary, sequence_length=69, X_one_hot=False, split_train_test=False, save_locally=True))Returns:
What it Actually Returns: X, y **The Features of What it Returns***: Number of Train Examples: 574735 Number of Test Examples: 0 X.shape: (574735, 69, 1) X[0]: [[53] [41] [38] [ 3] [49] [51] [48] [43] [38] . . . ] y_train.shape: (574735, 1) y_train[0]: [128]In the above example we created our data to contain 69 chars/words per sequence, be NOT one-hot encoded, for Y NOT to be one-hot encoded, NOT be split into test and train datasets, and to be saved to our local machine.
-
make_sentences
This method was a bit of an afterthought in this package, and was included upon the request of a friend. It splits the fully_processed_text into sentences by identifying splitter locations through chars like [. ! ?]
Arguments
- fully_processed_text - Takes in the fully processed text returned by the process_text method.
Example Usage
train sentences = make_sentences(fully_processed_text)Returns:
[' ', 'i', ' ', 'n', 'e', 'v', 'e', 'r', ' ', 's', 'e', 'e', ' ', 's', 'u', 'c', 'h', ' ', 'a', ' ', 's', 'o', 'n', '.'] -
encode_sentences
This method is just an encoder for the make_sentences method. Turning them into integer representations of each word, using the int_to_word_dictionary.
Arguments
- fully_processed_text - Takes in the fully processed text returned by the process_text method.
- int_to_word_dictionary - Takes in the int_to_word_dictionary returned by the int_to_word method.
Example Usage
encoded = encode_sentences(sentences, int_to_word_dictionary)Returns:
[3, 42, 3, 47, 38, 55, 38, 51, 3, 52, 38, 38, 3, 52, 54, 36, 41, 3, 34, 3, 52, 48, 47, 15]Note, these final two methods in the Data class leave it up to the user to create target data, as there are many different ways to train on sentence data using LSTMs.
Visualize
-
make_prevelence_dict
This is a quick method that takes in all the chars/words in the fully processed text, and returns a dictionary based on prevalence sorted in descending order. This is a great tool for visualizing what your data looks like and catching possible overfitting causes.
Arguments
- fully_processed_text - Takes in the fully processed text returned by the process_text method.
Example Usage
prevelence_dictionary = make_prevelence_dict(fully_processed_text)Returns:
[(' ', 104548), ('e', 49605), ('t', 42825), ('o', 37018), ('a', 36947), ('n', 33119), ('i', 28636), ('h', 26660), ('s', 25503), ('d', 23906), ('r', 20554), ('l', 17637), ('u', 14114), ('w', 13419), ('g', 10906), ...] -
plot_top
Now that we have our sort prevalence dictionary, we can make a simple bar chart to visualize the dictionary better.
Arguments
- number - Takes in a number for the top 'n' chars/words you want to display.
- prevelence_dictionary - Takes in the prevelence_dictionary from the make_prevelence_dict method.
Example Usage
plot_top(10, prevelence_dictionary)Returns:
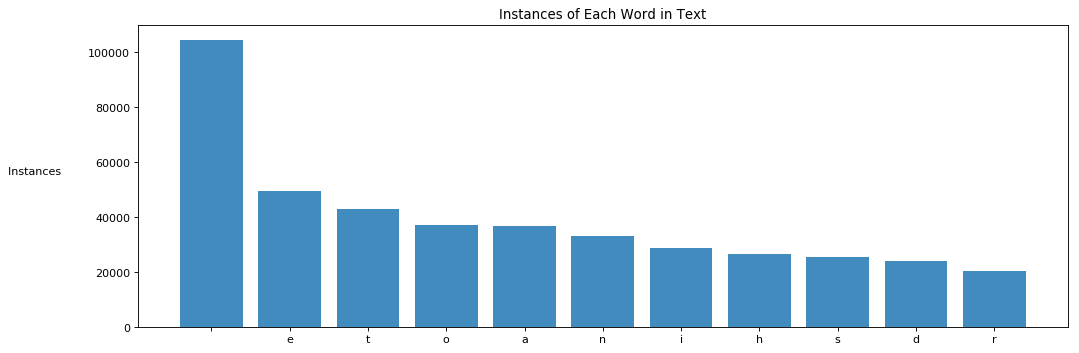
Results
For the following example, I used Predictionary to pull data from project gutenberg on 5 books. Moby Dick, Alice in Wonderland, Huckleberry Finn, The Strange Case of Dr. Jekyll and Mr. Hyde, and the Iliad. These books totaled over 3,000,000 sequence examples for the network to learn. I used a 2 layer LSTM with over 200,000 weights and the following architecture...
Model: "model_3"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_4 (InputLayer) (None, 50, 1) 0
__________________________________________________________________________________________________
permute_4 (Permute) (None, 1, 50) 0 input_4[0][0]
__________________________________________________________________________________________________
dense_9 (Dense) (None, 1, 50) 2550 permute_4[0][0]
__________________________________________________________________________________________________
attention_prob (Permute) (None, 50, 1) 0 dense_9[0][0]
__________________________________________________________________________________________________
multiply_4 (Multiply) (None, 50, 1) 0 input_4[0][0]
attention_prob[0][0]
__________________________________________________________________________________________________
lstm_7 (LSTM) (None, 50, 128) 66560 multiply_4[0][0]
__________________________________________________________________________________________________
dropout_7 (Dropout) (None, 50, 128) 0 lstm_7[0][0]
__________________________________________________________________________________________________
lstm_8 (LSTM) (None, 128) 131584 dropout_7[0][0]
__________________________________________________________________________________________________
dropout_8 (Dropout) (None, 128) 0 lstm_8[0][0]
__________________________________________________________________________________________________
dense_10 (Dense) (None, 100) 12900 dropout_8[0][0]
__________________________________________________________________________________________________
dense_11 (Dense) (None, 70) 7070 dense_10[0][0]
==================================================================================================
Total params: 220,664
Trainable params: 220,664
Non-trainable params: 0
This network was EXTREMELY slow to train on my machine so I capped the number of epochs to about 35, which came out to around 40 hours.
Here are a few input seeds, and the computer's predictions...
Input:
"The old woman talked surgeon's astronomy in the back country, and by j..."
Output:
"...ove the soul the last the milking of the contrast in the coursers he dropped it out the new charms"
Input:
"The old woman talked surgeon's astronomy in the back country, and by j..."
Output:
"...ove without paused great achilles lies and i show one murmer all brightly enough"
As you can see, not great or coherent by any stretch of the imagination, but not bad for a model that only sees 50 characters at a time and has >3M training examples.
📜 License
MIT License
Copyright (c) 2019 Oliver Mathias
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file predictionary-0.1.5.tar.gz.
File metadata
- Download URL: predictionary-0.1.5.tar.gz
- Upload date:
- Size: 17.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.6.0 requests-toolbelt/0.9.1 tqdm/4.36.1 CPython/3.7.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
69c18f66476def66dc8b49acdeaf56006cb2e1c0ef0fd743361a0cdfd4eeec1d
|
|
| MD5 |
4bd33075f21da39ea18a0aec94614dd0
|
|
| BLAKE2b-256 |
653da25cae544564cb219e442c95dbacb181e33b114ccace6d9b92567ee8e2cd
|







