Preprocessing for ML models made easy.

Project description
Prep-ML
What is Prep-ML?
prep-ml is an open-source pre-processing library aimed at simplifying the data processing steps and streamlining the transformation techniques before feeding it to your choice of machine learning algorithm.
Why Prep-ML?
Production grade machine learning is quite different from the standard notebook building. Notebook building is aimed at fast development, interactive code, and visual feedback system. While the scripts aim to cater models to large groups of audience or companies.
For eg, consider one of the key features of your model is DATE_OF_BIRTH, in real-time, due to various database schemas, the feature could be available in any of its synonyms (say, DOB, BIRTH_DATE). This is where prep-ml tries to fill in, like a heavily inspired from ETL tools and other design patterns.
Installation
$ pip install prep-ml
Documentation
This is the schema currently supported by the library. This can take python dict or JSON string.
{
"FEATURE_NAME": {
"required": bool,
"encoding": str,
"alias": str,
"imputation": str,
"derived_eq": str
}
}
Schema Definitions:
required: bool
accepted values: True, False
determines if the feature is required for the model.
- If required is set to False, the FEATURE_NAME is discarded for further processing.
encoding: str
accepted values: label, ohe
performs the given encoding strategy on the FEATURE_NAME.
- If encoding is set to "label", LabelEncoding or OrdinalEncoding is performed on the FEATURE_NAME
- If encoding is set to "ohe", OneHotEncoding is performed on the FEATURE_NAME
alias: str
accepted values: any string
this is a synonym or alias for the given FEATURE_NAME.
- For eg, If alias is set to "FEATURE_OTHER_NAME", the alias name will be mapped to the FEATURE_NAME
imputation: str
accepted values: mean, median, most_frequent
performs the given imputation strategy on the FEATURE_NAME. This is a wrapper of SimpleImputer.
- If "mean", then replace missing values using the mean for the FEATURE_NAME. Can only be used with numeric data.
- If "median", then replace missing values using the median for the FEATURE_NAME. Can only be used with numeric data.
- If "most_frequent", then replace missing using the most frequent value for the FEATURE_NAME. Can be used with strings or numeric data. If there is more than one such value, only the smallest is returned.
derived_eq: str
accepted values: eval equation as a string
evaluated the given equation and then assigns the response to FEATURE_NAME. The reference to dataframe should be df
- For eg consider the above feature DOB, If derived_eq is set to "pd.to_datetime(df.DOB, format='%m/%d/%Y')", the expression will be evaluated and assigned to FEATURE_NAME. Note that, df is reference to the provided input df.
Methods:
from_dict(mapper, dataframe) -- reads the dict and processes the input dataframe.
from_json(json_mapper, dataframe) -- reads the json and processes the input dataframe.
get_data() -- fetches the processed data.
Usage Example:
This is the input data
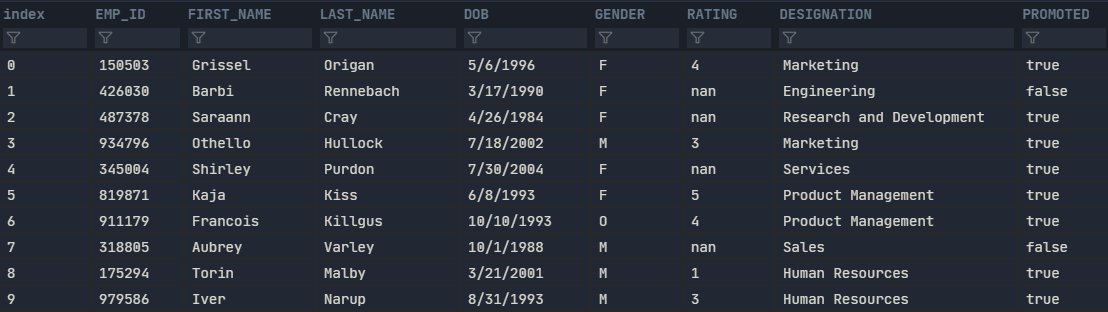
Data Explanation:
This is randomly generated data for the purposes of demo. All references are assumptions.
This is a company employee data. We have various features, which are self explanatory.
Ideally, we would want to remove the NAMES, as they are uniques and serve no purpose in model. Transform DOB to say a derived feature called AGE. Encode, GENDER, DESIGNATION and PROMOTED. Impute RATING.
So, on using the driver code.
from prep_ml.pre_processor import Prep
import pandas as pd
prep_ob = {
"EMPLOYEE_ID": {
"alias": "EMP_ID",
"required": True
},
"FIRST_NAME": {
"required": False,
},
"LAST_NAME": {
"required": False,
},
"AGE": {
"required": True,
"alias": "DOB",
"derived_eq": "(pd.Timestamp('now') - pd.to_datetime(df.AGE, format='%m/%d/%Y')).astype('<m8[Y]')"
},
"GENDER": {
"required": True,
"encoding": 'ohe'
},
"RATING": {
"required": True,
"imputation": 'most_frequent'
},
"DESIGNATION": {
"required": True,
"encoding": 'label'
},
"PROMOTED": {
"required": True,
"encoding": 'label'
}
}
df = pd.read_csv('tests/MOCK_DATA.csv')
p = Prep.from_dict(prep_ob, df)
rdf = p.get_data()
print(rdf.columns.to_list())
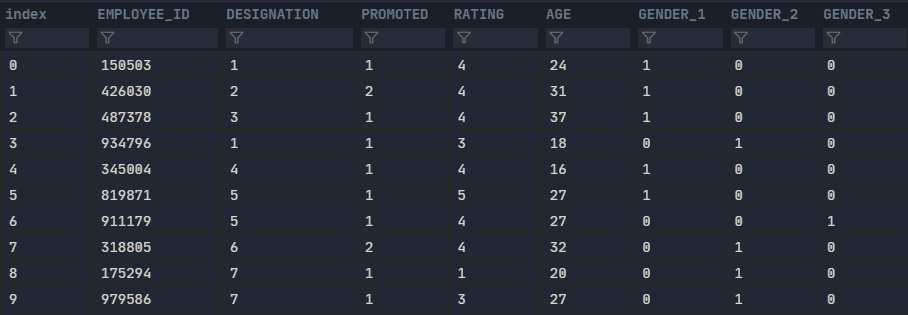
Output
['EMPLOYEE_ID', 'DESIGNATION', 'PROMOTED', 'RATING', 'AGE', 'GENDER_1', 'GENDER_2', 'GENDER_3']
The output in dataviewer is as follows.
Future Development Roadmap
- Performance improvements.
- Add support for more imputation and encoding strategies.
- Support for feature scaling.
- Support for multiple schemas.
- Support for multiple input sources.
- Support for enforcing column types.
- Feasibility for model training.
Changelog
2nd May, 2021 :: v0.1.0:
- This is a very early dev version. This further needs development and code optimization.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file prep-ml-0.1.1.tar.gz.
File metadata
- Download URL: prep-ml-0.1.1.tar.gz
- Upload date:
- Size: 6.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.1.6 CPython/3.7.6 Windows/10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
99ae1348c537caac7899862df24fc2b73affccc1c785be9cd40d1913d10d1824
|
|
| MD5 |
6ce2677a27ca68e0b0b14887b4a2d1ee
|
|
| BLAKE2b-256 |
6a84b4fc5829ce77578981e1a206c575b963b5873097e3ca55026ea8552c38f3
|
File details
Details for the file prep_ml-0.1.1-py3-none-any.whl.
File metadata
- Download URL: prep_ml-0.1.1-py3-none-any.whl
- Upload date:
- Size: 5.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.1.6 CPython/3.7.6 Windows/10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c7533cf02124f4e20d768ed1b755b9b5e51d25afbaef13d9ca1ca1a826b2e151
|
|
| MD5 |
0f34af63da9a0b7ec1ac8f6b9903d6b5
|
|
| BLAKE2b-256 |
9a33c3c6c20e8f21cf2f354c8c06abd4e587f00f9890624efebdb6e0bb273efe
|







