Scrape and download from Piccoma Japan and France.

Project description
Pyccoma




Directly download smartoon, manga, and novels from Piccoma Japan and Piccoma France.
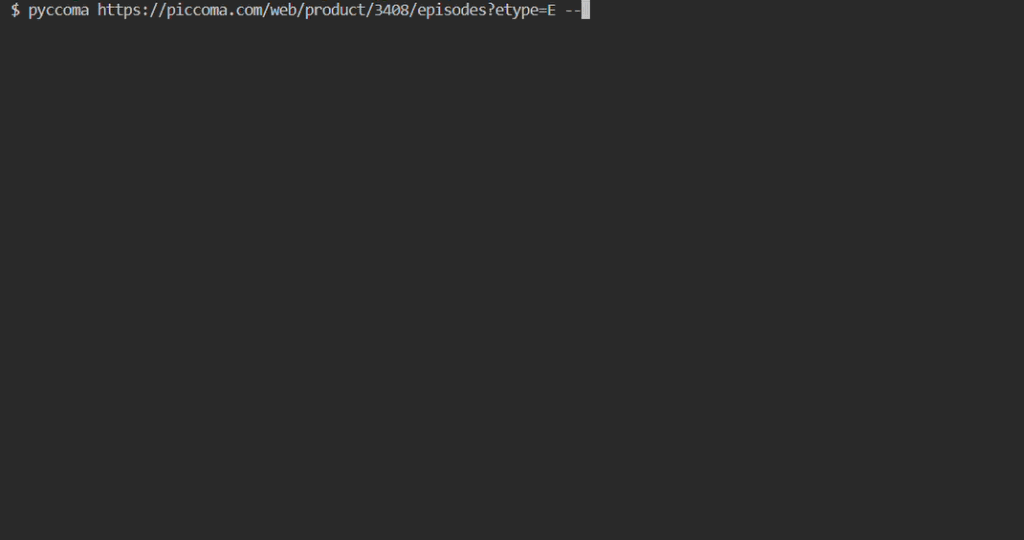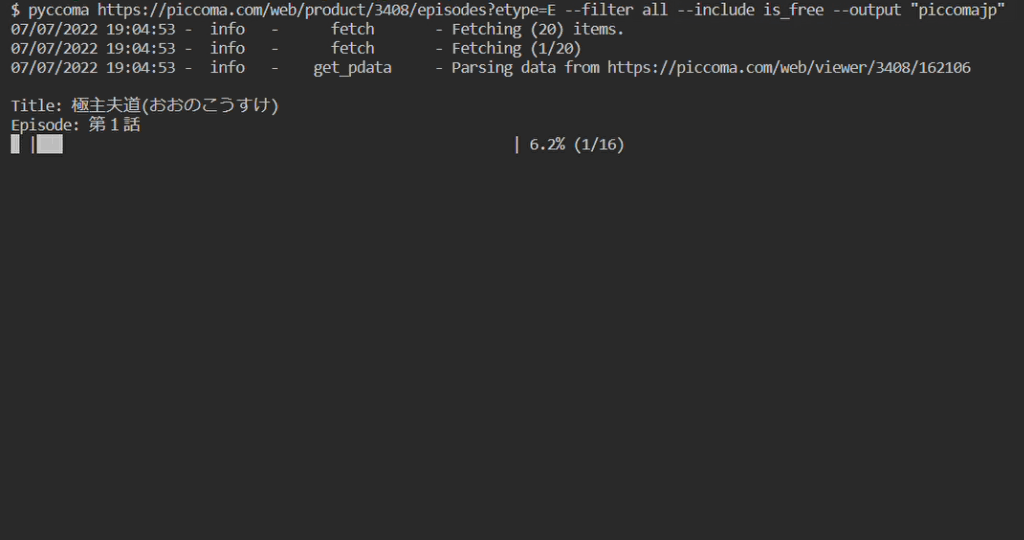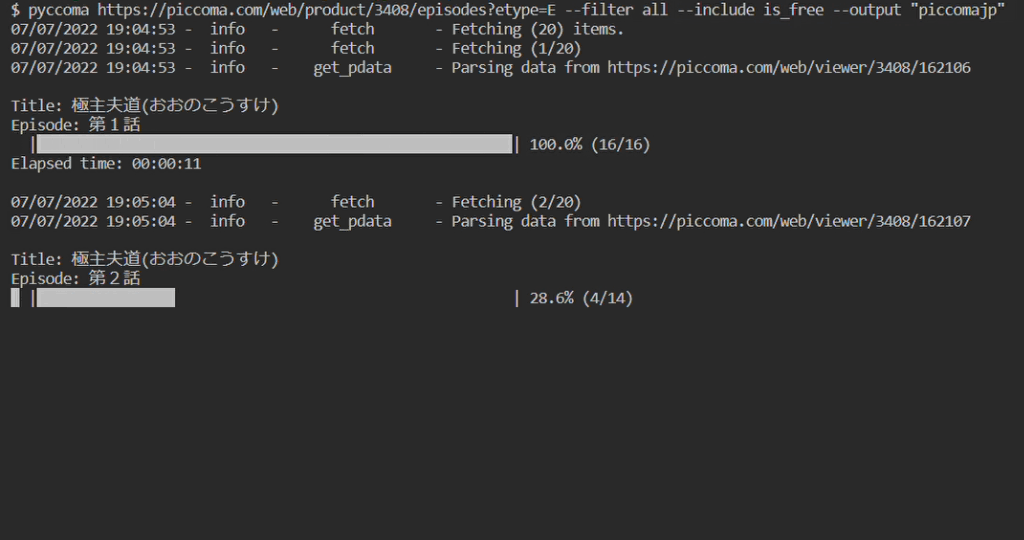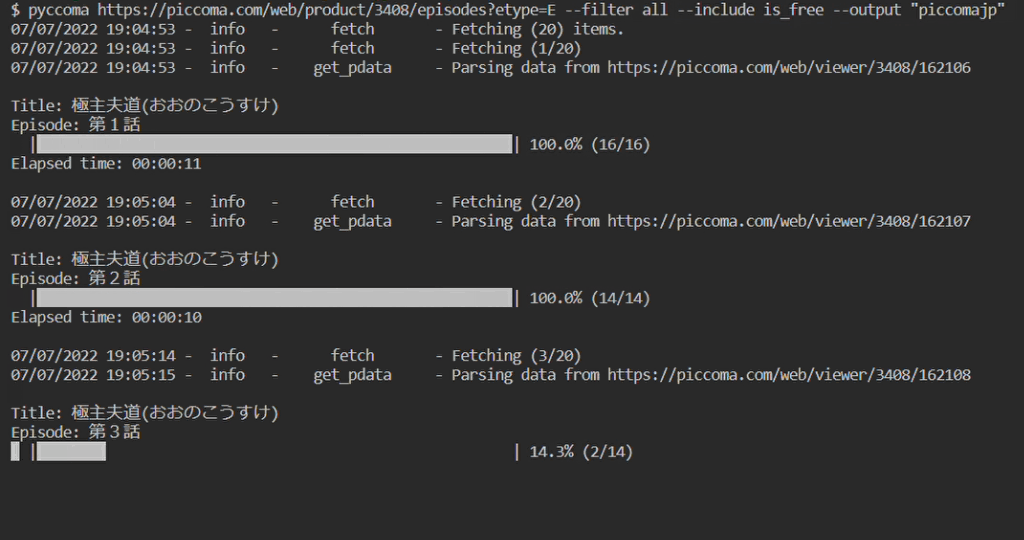
Prerequisites
- Python 3.8+
Install
$ pip install pyccoma
Getting Started
Using the command-line utility
To download a single episode, simply use:
$ pyccoma https://piccoma.com/web/viewer/60171/1575237
You can also pass multiple links (separated by whitespace) to download in one go, then use the --archive option to output to a cbz archive.
$ pyccoma https://piccoma.com/web/viewer/60171/1575237 https://piccoma.com/web/viewer/8195/1185884 --archive
Use the option --region to switch between Piccoma Japan (default) and Piccoma France.
$ pyccoma https://piccoma.com/fr/viewer/49/2946 --region fr
Access purchased episodes from your library by logging in using the --email option.
$ pyccoma purchase --region fr --filter all --include is_purchased --email foo@bar.com
$ pyccoma purchase --region jp --filter all --include is_purchased --email foo@bar.com
Read more about the available CLI options on the next section below. You can also see more examples here on how to aggregate and batch download using the command-line utility.
Using Python shell
Import the Pyccoma class according to their region.
| Module | Description |
|---|---|
pyccoma.jp |
Piccoma Japan |
pyccoma.fr |
Piccoma France |
Create a Pyccoma instance and use fetch to scrape and download images from a viewer page.
>>> from pyccoma.jp import Pyccoma
>>> jp = Pyccoma()
>>> jp.fetch('https://piccoma.com/web/viewer/8195/1185884')
Title: ひげを剃る。そして女子高生を拾う。(しめさば ぶーた 足立いまる)
Episode: 第1話 失恋と女子高生 (1)
|███████████████████████████████████████████████████████████| 100.0% (14/14)
Elapsed time: 00:00:17
>>> from pyccoma.fr import Pyccoma
>>> fr = Pyccoma()
>>> fr.fetch('https://piccoma.com/fr/viewer/49/2944')
Title: Roxana (BAEK JI-YEON Juniljus Kin)
Episode: #1 Il est mon seul espoir de survie
|███████████████████████████████████████████████████████████| 100.0% (80/80)
Elapsed time: 00:00:47
You can use login to have access to rental or paywalled episodes from your own library.
>>> jp.login(email, password)
>>> jp.fetch('https://piccoma.com/web/viewer/s/4995/1217972', 'output_dir')
Title: かぐや様は告らせたい~天才たちの恋愛頭脳戦~(赤坂アカ)
Episode: 第135話
|███████████████████████████████████████████████████████████| 100.0% (20/20)
Elapsed time: 00:00:23
Options
Required
| Option | Description | Examples |
|---|---|---|
| url | Must be a valid url | https://piccoma.com/web/product/4995/episodes?etype=V, https://piccoma.com/web/product/12482/episodes?etype=E, https://piccoma.com/web/viewer/12482/631201, https://piccoma.com/fr/product/volume/109, https://piccoma.com/fr/product/episode/231, bookmark, history, purchase |
Locale
| Option | Description | Examples |
|---|---|---|
| --region | Select which service to use | Jp (Piccoma Japan), Fr (Piccoma France) |
Optional
| Option | Description | Examples |
|---|---|---|
| -o, --output | Local directory to save downloaded images | D:/piccoma/ (absolute path), /piccoma/download/ (relative path) |
| -f, --format | Image format | jpeg, jpg, gif, bmp, png (default) |
| -p, --pad | Pad page numbers with leading zeroes | 0 (default) |
| --archive | Download as cbz archive | |
| --omit-author | Omit author names from titles |
Retry
| Option | Description | Examples |
|---|---|---|
| --retry-count | Number of download retry attempts when error occurred | 3 (default) |
| --retry-interval | Delay between each retry attempt (in seconds) | 1 (default) |
Login
| Option | Description | Examples |
|---|---|---|
| Your registered email address; this does not support OAuth authentication | foo@bar.com |
Filter
| Option | Description | Examples |
|---|---|---|
| --etype | Preferred episode type to scrape manga, smartoon, and novel when scraping history, bookmark, purchase; takes in three arguments, the first one for manga, the second for smartoon, and the last one for novel |
volume to scrape for volumes, episode to scrape for episodes |
| --filter | Filter to use when scraping episodes from a product page or your library | min, max, all, or custom by defining --range. Use min to scrape for the first item, max for the last item, all to scrape all items, and custom to scrape for a specific index range |
| --range | Range to use when scraping episodes; takes in two arguments, start and end; will always override --filter to parse custom, if omitted or otherwise | 0 10 will scrape the first up to the tenth episode |
| --include | Status arguments to include when parsing a library or product; can parse in | and & operators as conditionals, see use cases below |
is_purchased, is_free, is_zero_plus, is_already_read, is_read_for_free, is_wait_until_free |
| --exclude | Status arguments to exclude when parsing a library or product; can parse in | and & operators as conditionals, see use cases below |
is_purchased, is_free, is_zero_plus, is_already_read, is_read_for_free, is_wait_until_free |
Logging
| Option | Description | Examples |
|---|---|---|
| -l, --loglevel | Set the log message threshold | debug, info (default), warning, error, none |
Examples
Use the --include and --exclude options in the command-line utility to narrow down which items are included in an aggregation.
| Argument | Description |
|---|---|
| is_free | Free-to-access volumes/episodes |
| is_wait_until_free | Episodes that can be accessed by waiting/using free pass |
| is_read_for_free | Episodes that are accessed using free pass |
| is_purchased | Purchased volumes/episodes |
| is_zero_plus | Free-to-access episodes |
| is_already_read | Items that have been accessed before; formatted as grayed-out rows |
Aggregating and downloading in batch
- Downloading all free episodes in a single product page:
$ pyccoma https://piccoma.com/web/product/67171/episodes?etype=E --filter all --include is_free
- Downloading all free episodes across multiple products:
$ pyccoma https://piccoma.com/web/product/5523/episodes?etype=E https://piccoma.com/web/product/23019/episodes?etype=E --filter all --include is_free
- Downloading all first episodes across multiple products:
$ pyccoma https://piccoma.com/web/product/6575/episodes?etype=E https://piccoma.com/web/product/41993/episodes?etype=E --filter min
- Downloading using custom with range:
$ pyccoma https://piccoma.com/web/product/16070/episodes?etype=E --filter custom --range 1 5
Disclaimer
Pyccoma was made for the sole purpose of helping users download media from Piccoma for offline consumption. This is for private use only, do not use this tool to promote piracy.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyccoma-0.7.2.tar.gz.
File metadata
- Download URL: pyccoma-0.7.2.tar.gz
- Upload date:
- Size: 22.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9ffbec192d19a7c11b2e3beaa38a6e6728f493708ade61569e0de31d4e6c0be2
|
|
| MD5 |
0a192fc737ce4ff14c3b8e2a16d3282f
|
|
| BLAKE2b-256 |
c4c6199745611c403179bee2884c185d36bd57403feb0a32dd3d7ecce5d6ed3c
|
File details
Details for the file pyccoma-0.7.2-py2.py3-none-any.whl.
File metadata
- Download URL: pyccoma-0.7.2-py2.py3-none-any.whl
- Upload date:
- Size: 23.4 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d773f1d21cbec7563d5a8d078480a4e39cf1a17fb9f1f6b6684f965df877fa9f
|
|
| MD5 |
c7b45a47b838003a508db00756529f38
|
|
| BLAKE2b-256 |
dc974909739619f9302f7f62454d478118bbb0a2e39bd49e50d447845e344ad8
|







