A framework for research code

Project description
pyfra
The Python Framework for Research Applications.


Design Philosophy
Research code has some of the fastest shifting requirements of any type of code. It's nearly impossible to plan ahead of time the proper abstractions, because it is exceedingly likely that in the course of the project what you originally thought was your main focus suddenly no longer is. Further, research code (especially in ML) often involves big and complicated pipelines, typically involving many different machines, which are either run by hand or using shell scripts that are far more complicated than any shell script ever should be.
Therefore, the objective of pyfra is to make it as fast and low-friction as possible to write research code involving complex pipelines over many machines. This entails making it as easy as possible to implement a research idea in reality, at the cost of fine-grained control and the long-term maintainability of the system. In other words, pyfra expects that code will either be rapidly obsoleted by newer code, or rewritten using some other framework once it is no longer a research project and requirements have settled down.
As such, high quality interface design is a top priority of pyfra. The ultimate goal is to make interfaces that feel extremely natural, such that it is intuitively obvious what any piece of pyfra code should do, without requiring consultation of the docs. The core pyfra abstractions should be optimized, as much as possible, for naturalness; it should be easy to do the things that are frequently needed, but if making it so would require a sacrifice in generality, the abstraction should be decomposed into a maximally-general core and an application-specific layer on top. As is it expected that pyfra-based code is short lived, when trading off between API stability and cleaner/more intuitive interfaces, pyfra will attempt to choose the latter. That being said, core pyfra should become more and more stable as time progressese.
The pyfra.contrib package is intended for code that is built on top of pyfra and useful in conjunction with pyfra, but has fewer stability guarantees than core pyfra. Especially useful and well designed functions in contrib may be promoted to core pyfra.
Pyfra is in its very early stages of development. The interface may change rapidly and without warning.
Features:
- Extremely elegant shell integration—run commands on any server seamlessly. All the best parts of bash and python combined
- Handle files on remote servers with a pathlib-like interface the same way you would local files (WIP, partially implemented)
- Automated remote environment setup, so you never have to worry about provisioning machines by hand again
- Idempotent resumable data and training pipelines with no cognitive overhead
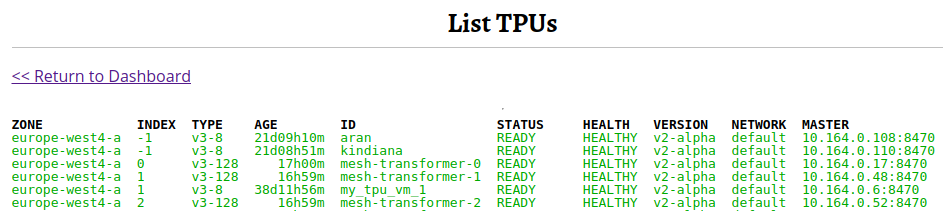
- Spin up an internal webserver complete with a permissions system using only a few lines of code
- (Coming soon) High level API for experiment management/scheduling and resource provisioning
Want to dive in? See the documentation.
Example code
(This example obviously doesn't run as-is, it's just an illustrative example)
from pyfra import *
rem1 = Remote("user@example.com")
rem2 = Remote("goose@8.8.8.8")
# env creates an environment object, which behaves very similarly to a Remote (in fact Env inherits from Remote),
# but comes with a fresh python environment in a newly created directory (optionally initialized from a git repo)
# also, anything you run in an env will resume where it left off, with semantics similar to dockerfiles.
env1 = rem1.env("tokenization")
env2 = rem2.env("training", "https://github.com/some/repo")
# path creates a RemotePath object, which behaves similar to a pathlib Path.
raw_data = local.path("training_data.txt")
tokenized_data = env2.path("tokenized_data")
# tokenize
copy("https://goose.com/files/tokenize_script.py", env1.path("tokenize.py")) # copy can copy from local/remote/url to local/remote
env1.sh(f"python tokenize.py --input {raw_data} --output {tokenized_data}") # implicitly copy files just by using the path object in an f-string
# start training run
env2.path("config.json").jwrite({...})
env2.sh("python train.py --input tokenized_data --config config.json")
Installation
pip3 install pyfra
Webserver screenshots
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyfra-0.3.1.tar.gz.
File metadata
- Download URL: pyfra-0.3.1.tar.gz
- Upload date:
- Size: 515.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e32947bb632778c64cd74899f02ed34eafd1f217a6f0d2fde60adfe0471906ca
|
|
| MD5 |
1e4b7b7e3958c29bd26e8be223ae8118
|
|
| BLAKE2b-256 |
03783e1b6eba791ff0a759566d22f9e7778663e18978368677699a041af9adf1
|
File details
Details for the file pyfra-0.3.1-py3-none-any.whl.
File metadata
- Download URL: pyfra-0.3.1-py3-none-any.whl
- Upload date:
- Size: 528.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7ceebfb2e64425fca0b9fb6a308d670c8c97ea0a564c7ef7ac8c22306c77496f
|
|
| MD5 |
f95e75e672f6874a29add3ef3b258348
|
|
| BLAKE2b-256 |
1cf31814f8716972479538d1ceb3b5e1f4826291592b7a5785abe10592da9950
|







