Access geospatial web services that offer hydrological data
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description


Package |
Description |
|---|---|
Navigate and subset NHDPlus (MR and HR) using web services |
|
Access topographic data through National Map’s 3DEP web service |
|
Access NWIS, NID, WQP, eHydro, NLCD, CAMELS, and SSEBop databases |
|
Access daily, monthly, and annual climate data via Daymet |
|
Access daily climate data via GridMET |
|
Access hourly NLDAS-2 data via web services |
|
A collection of tools for computing hydrological signatures |
|
High-level API for asynchronous requests with persistent caching |
|
Send queries to any ArcGIS RESTful-, WMS-, and WFS-based services |
|
Utilities for manipulating geospatial, (Geo)JSON, and (Geo)TIFF data |
PyGeoHydro: Retrieve Geospatial Hydrology Data









Features
PyGeoHydro (formerly named hydrodata) is a part of HyRiver software stack that is designed to aid in hydroclimate analysis through web services. This package provides access to some public web services that offer geospatial hydrology data. It has three main modules: pygeohydro, plot, and helpers.
PyGeoHydro supports the following datasets:
gNATSGO for US soil properties.
SoilGrids for seamless global soil properties.
Derived Soil Properties for soil porosity, available water capacity, and field capacity across the US.
NWIS for daily mean streamflow observations (returned as a pandas.DataFrame or xarray.Dataset with station attributes),
SensorThings API for accessing real-time data of USGS sensors.
CAMELS for accessing streamflow observations (1980-2014) and basin-level attributes of 671 stations within CONUS.
Water Quality Portal for accessing current and historical water quality data from more than 1.5 million sites across the US,
NID for accessing the National Inventory of Dams web service,
HCDN 2009 for identifying sites where human activity affects the natural flow of the watercourse,
NLCD 2021 for land cover/land use, imperviousness descriptor, and canopy data. You can get data using both geometries and coordinates.
WBD for accessing Hydrologic Unit (HU) polygon boundaries within the US (all HUC levels).
SSEBop for daily actual evapotranspiration, for both single pixel and gridded data.
Irrigation Withdrawals for estimated monthly water use for irrigation by 12-digit hydrologic unit in the CONUS for 2015
STN for access USGS Short-Term Network (STN)
eHydro for accessing USACE Hydrographic Surveys that includes topobathymetry data
NFHL for accessing FEMA’s National Flood Hazard Layer (NFHL) data.
Also, it includes several other functions:
interactive_map: Interactive map for exploring NWIS stations within a bounding box.
cover_statistics: Categorical statistics of land use/land cover data.
overland_roughness: Estimate overland roughness from land use/land cover data.
streamflow_fillna: Fill missing daily streamflow values with day-of-year averages. Streamflow observations must be at least for 10-year long.
The plot module includes two main functions:
signatures: Hydrologic signature graphs.
cover_legends: Official NLCD land cover legends for plotting a land cover dataset.
descriptor_legends: Color map and legends for plotting an imperviousness descriptor dataset.
The helpers module includes:
nlcd_helper: A roughness coefficients lookup table for each land cover and imperviousness descriptor type which is useful for overland flow routing among other applications.
nwis_error: A dataframe for finding information about NWIS requests’ errors.
You can find some example notebooks here.
Moreover, under the hood, PyGeoHydro uses PyGeoOGC and AsyncRetriever packages for making requests in parallel and storing responses in chunks. This improves the reliability and speed of data retrieval significantly.
You can control the request/response caching behavior and verbosity of the package by setting the following environment variables:
HYRIVER_CACHE_NAME: Path to the caching SQLite database for asynchronous HTTP requests. It defaults to ./cache/aiohttp_cache.sqlite
HYRIVER_CACHE_NAME_HTTP: Path to the caching SQLite database for HTTP requests. It defaults to ./cache/http_cache.sqlite
HYRIVER_CACHE_EXPIRE: Expiration time for cached requests in seconds. It defaults to one week.
HYRIVER_CACHE_DISABLE: Disable reading/writing from/to the cache. The default is false.
HYRIVER_SSL_CERT: Path to a SSL certificate file.
For example, in your code before making any requests you can do:
import os
os.environ["HYRIVER_CACHE_NAME"] = "path/to/aiohttp_cache.sqlite"
os.environ["HYRIVER_CACHE_NAME_HTTP"] = "path/to/http_cache.sqlite"
os.environ["HYRIVER_CACHE_EXPIRE"] = "3600"
os.environ["HYRIVER_CACHE_DISABLE"] = "true"
os.environ["HYRIVER_SSL_CERT"] = "path/to/cert.pem"You can also try using PyGeoHydro without installing it on your system by clicking on the binder badge. A Jupyter Lab instance with the HyRiver stack pre-installed will be launched in your web browser, and you can start coding!
Moreover, requests for additional functionalities can be submitted via issue tracker.
Citation
If you use any of HyRiver packages in your research, we appreciate citations:
@article{Chegini_2021,
author = {Chegini, Taher and Li, Hong-Yi and Leung, L. Ruby},
doi = {10.21105/joss.03175},
journal = {Journal of Open Source Software},
month = {10},
number = {66},
pages = {1--3},
title = {{HyRiver: Hydroclimate Data Retriever}},
volume = {6},
year = {2021}
}Installation
You can install PyGeoHydro using pip after installing libgdal on your system (for example, in Ubuntu run sudo apt install libgdal-dev). Moreover, PyGeoHydro has an optional dependency for using persistent caching, requests-cache. We highly recommend installing this package as it can significantly speed up send/receive queries. You don’t have to change anything in your code, since PyGeoHydro under-the-hood looks for requests-cache and if available, it will automatically use persistent caching:
$ pip install pygeohydroAlternatively, PyGeoHydro can be installed from the conda-forge repository using Conda:
$ conda install -c conda-forge pygeohydroQuick start
We can obtain river topobathymetry data using the EHydro class. We can subset the dataset either using a geometry or a bounding box, based on their ID, or SQL query:
from pygeohydro import EHydro
ehydro = EHydro("points")
topobathy = ehydro.bygeom((-122.53, 45.57, -122.52, 45.59))We can explore the available NWIS stations within a bounding box using interactive_map function. It returns an interactive map and by clicking on a station some of the most important properties of stations are shown.
import pygeohydro as gh
bbox = (-69.5, 45, -69, 45.5)
gh.interactive_map(bbox)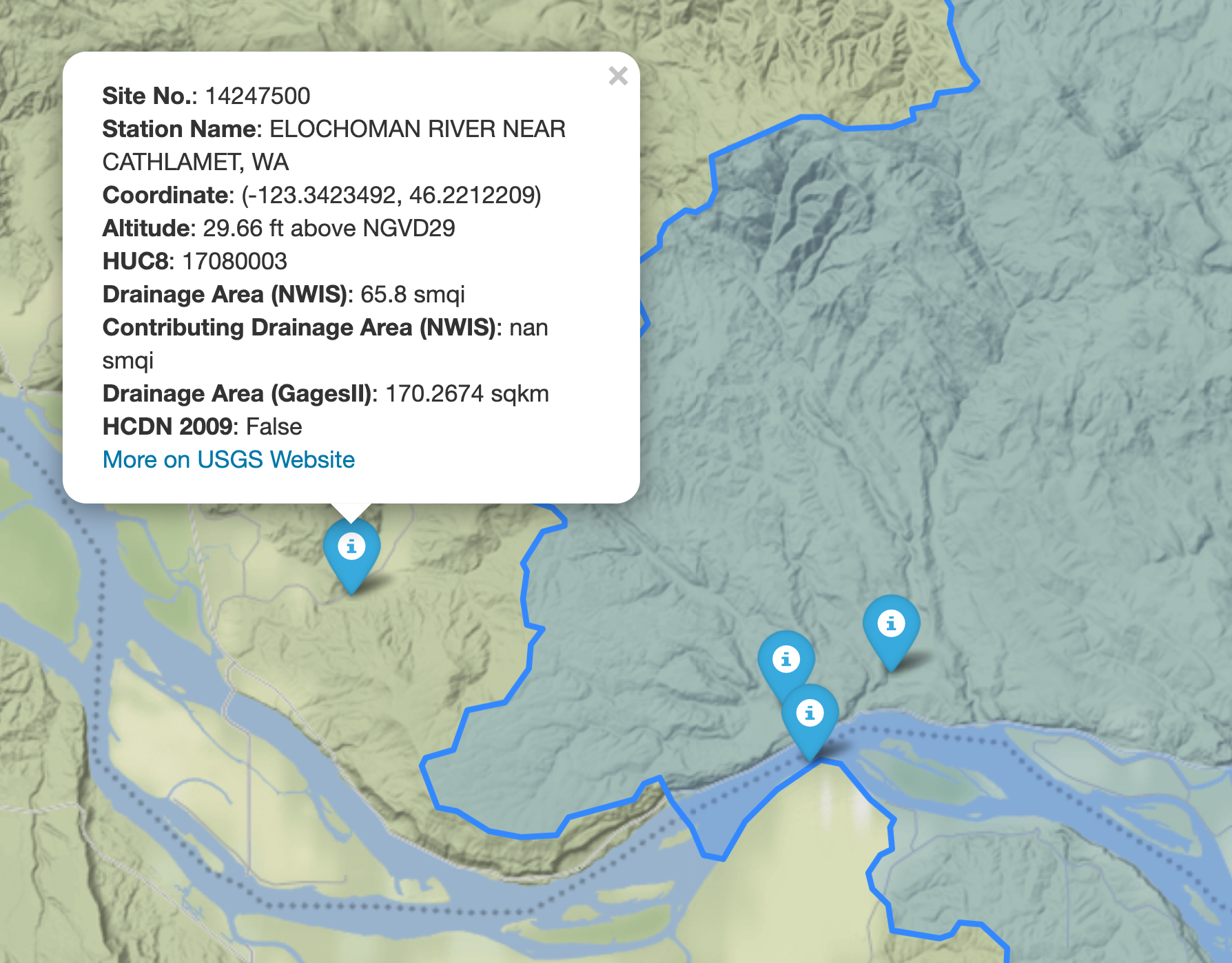
We can select all the stations within this boundary box that have daily mean streamflow data from 2000-01-01 to 2010-12-31:
from pygeohydro import NWIS
nwis = NWIS()
query = {
"bBox": ",".join(f"{b:.06f}" for b in bbox),
"hasDataTypeCd": "dv",
"outputDataTypeCd": "dv",
}
info_box = nwis.get_info(query)
dates = ("2000-01-01", "2010-12-31")
stations = info_box[
(info_box.begin_date <= dates[0]) & (info_box.end_date >= dates[1])
].site_no.tolist()Then, we can get the daily streamflow data in mm/day (by default the values are in cms) and plot them:
from pygeohydro import plot
qobs = nwis.get_streamflow(stations, dates, mmd=True)
plot.signatures(qobs)By default, get_streamflow returns a pandas.DataFrame that has a attrs method containing metadata for all the stations. You can access it like so qobs.attrs. Moreover, we can get the same data as xarray.Dataset as follows:
qobs_ds = nwis.get_streamflow(stations, dates, to_xarray=True)This xarray.Dataset has two dimensions: time and station_id. It has 10 variables including discharge with two dimensions while other variables that are station attitudes are one dimensional.
We can also get instantaneous streamflow data using get_streamflow. This method assumes that the input dates are in UTC time zone and returns the data in UTC time zone as well.
date = ("2005-01-01 12:00", "2005-01-12 15:00")
qobs = nwis.get_streamflow("01646500", date, freq="iv")We can query USGS stations of type “stream” in Arizona using SensorThings API as follows:
odata = {
"filter": "properties/monitoringLocationType eq 'Stream' and properties/stateFIPS eq 'US:04'",
}
df = sensor.query_byodata(odata)Irrigation withdrawals data can be obtained as follows:
irr = gh.irrigation_withdrawals()We can get the CAMELS dataset as a geopandas.GeoDataFrame that includes geometry and basin-level attributes of 671 natural watersheds within CONUS and their streamflow observations between 1980-2014 as a xarray.Dataset, like so:
attrs, qobs = gh.get_camels()The WaterQuality has a number of convenience methods to retrieve data from the web service. Since there are many parameter combinations that can be used to retrieve data, a general method is also provided to retrieve data from any of the valid endpoints. You can use get_json to retrieve stations info as a geopandas.GeoDataFrame or get_csv to retrieve stations data as a pandas.DataFrame. You can construct a dictionary of the parameters and pass it to one of these functions. For more information on the parameters, please consult the Water Quality Data documentation. For example, let’s find all the stations within a bounding box that have Caffeine data:
from pynhd import WaterQuality
bbox = (-92.8, 44.2, -88.9, 46.0)
kwds = {"characteristicName": "Caffeine"}
wq = WaterQuality()
stations = wq.station_bybbox(bbox, kwds)Or the same criterion but within a 30-mile radius of a point:
stations = wq.station_bydistance(-92.8, 44.2, 30, kwds)Then we can get the data for all these stations the data like this:
sids = stations.MonitoringLocationIdentifier.tolist()
caff = wq.data_bystation(sids, kwds)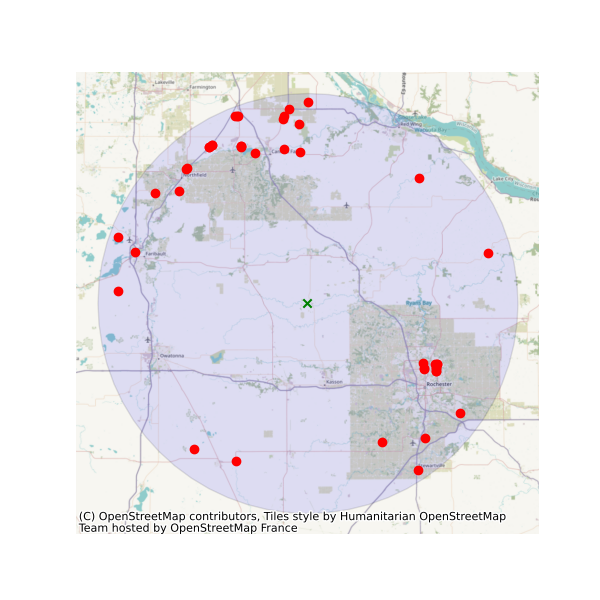
Moreover, we can get land use/land cove data using nlcd_bygeom or nlcd_bycoods functions, percentages of land cover types using cover_statistics, and overland roughness using overland_roughness. The nlcd_bycoords function returns a geopandas.GeoDataFrame with the NLCD layers as columns and input coordinates as the geometry column. Moreover, the nlcd_bygeom function accepts both a single geometry or a geopandas.GeoDataFrame as the input.
from pynhd import NLDI
basins = NLDI().get_basins(["01031450", "01318500", "01031510"])
lulc = gh.nlcd_bygeom(basins, 100, years={"cover": [2016, 2019]})
stats = gh.cover_statistics(lulc["01318500"].cover_2016)
roughness = gh.overland_roughness(lulc["01318500"].cover_2019)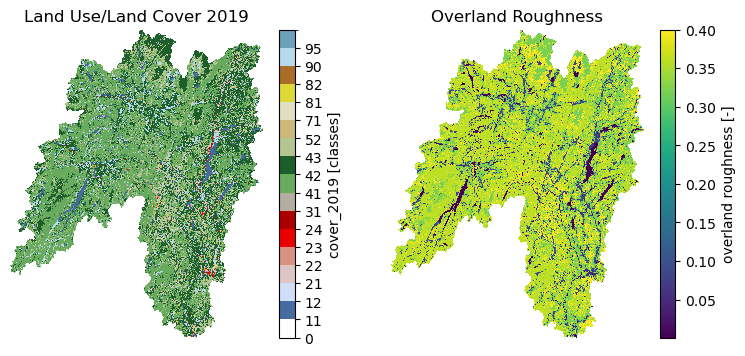
Next, let’s use ssebopeta_bygeom to get actual ET data for a basin. Note that there’s a ssebopeta_bycoords function that returns an ETA time series for a single coordinate.
geometry = NLDI().get_basins("01315500").geometry[0]
eta = gh.ssebopeta_bygeom(geometry, dates=("2005-10-01", "2005-10-05"))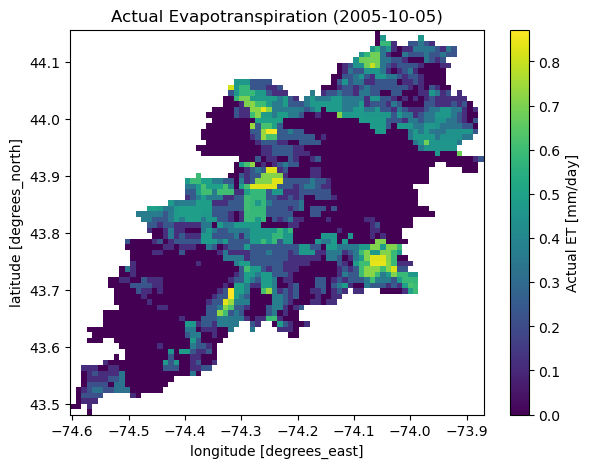
Additionally, we can pull all the US dams data using NID. Let’s get dams that are within this bounding box and have a maximum storage larger than 200 acre-feet.
nid = NID()
dams = nid.get_bygeom((-65.77, 43.07, -69.31, 45.45), 4326)
dams = nid.inventory_byid(dams.id.to_list())
dams = dams[dams.maxStorage > 200]We can get also all dams within CONUS with maximum storage larger than 2500 acre-feet:
conus_geom = gh.get_us_states("contiguous")
dam_list = nid.get_byfilter([{"maxStorage": ["[2500 +inf]"]}])
dams = nid.inventory_byid(dam_list[0].id.to_list(), stage_nid=True)
conus_dams = dams[dams.stateKey.isin(conus_geom.STUSPS)].reset_index(drop=True)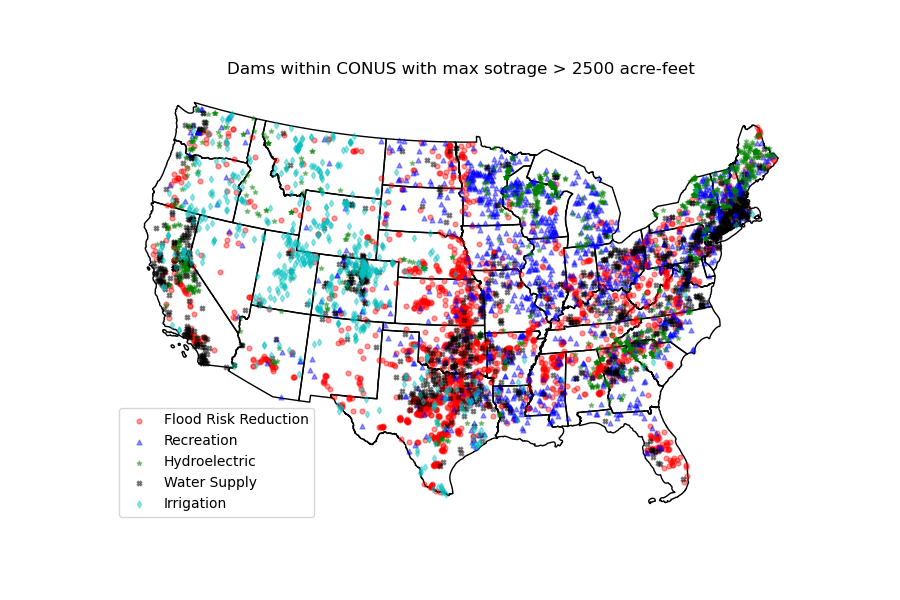
The WBD class allows us to get Hydrologic Unit (HU) polygon boundaries. Let’s get the two Hudson HUC4s:
from pygeohydro import WBD
wbd = WBD("huc4")
hudson = wbd.byids("huc4", ["0202", "0203"])The NFHL class allows us to retrieve FEMA’s National Flood Hazard Layer (NFHL) data. Let’s get the cross-section data for a small region in Vermont:
from pygeohydro import NFHL
nfhl = NFHL("NFHL", "cross-sections")
gdf_xs = nfhl.bygeom((-73.42, 43.28, -72.9, 43.52), geo_crs=4269)Contributing
Contributions are very welcomed. Please read CONTRIBUTING.rst file for instructions.
Credits
This package was created based on the audreyr/cookiecutter-pypackage project template.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pygeohydro-0.19.4.tar.gz.
File metadata
- Download URL: pygeohydro-0.19.4.tar.gz
- Upload date:
- Size: 85.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
264941166c118b33714b0b54809d42bad8fec1d7999923f1ccb8c9f12782e19e
|
|
| MD5 |
10d9633ece5bffce4230e9b3e1d15b4a
|
|
| BLAKE2b-256 |
0ac2274fffa9189bda5eadcac3adcb67dcadfd4c350a55e7e527870aa44130a5
|
Provenance
The following attestation bundles were made for pygeohydro-0.19.4.tar.gz:
Publisher:
release.yml on hyriver/pygeohydro
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pygeohydro-0.19.4.tar.gz -
Subject digest:
264941166c118b33714b0b54809d42bad8fec1d7999923f1ccb8c9f12782e19e - Sigstore transparency entry: 219451670
- Sigstore integration time:
-
Permalink:
hyriver/pygeohydro@b6d0205aa211b2c1cea9be874c8ee2010ad12a82 -
Branch / Tag:
refs/tags/v0.19.4 - Owner: https://github.com/hyriver
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@b6d0205aa211b2c1cea9be874c8ee2010ad12a82 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file pygeohydro-0.19.4-py3-none-any.whl.
File metadata
- Download URL: pygeohydro-0.19.4-py3-none-any.whl
- Upload date:
- Size: 61.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a850e77152f1c16b2c7d2fb7fb82a75fd536cb37180fe86d8ec9bdec9e9ba6f3
|
|
| MD5 |
cd980552a6385a866a7115a14d94df9c
|
|
| BLAKE2b-256 |
091ab8ed3e2dcdbf101b16751e5702440db09604d4f6c4066e79dbcd8be55857
|
Provenance
The following attestation bundles were made for pygeohydro-0.19.4-py3-none-any.whl:
Publisher:
release.yml on hyriver/pygeohydro
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pygeohydro-0.19.4-py3-none-any.whl -
Subject digest:
a850e77152f1c16b2c7d2fb7fb82a75fd536cb37180fe86d8ec9bdec9e9ba6f3 - Sigstore transparency entry: 219451671
- Sigstore integration time:
-
Permalink:
hyriver/pygeohydro@b6d0205aa211b2c1cea9be874c8ee2010ad12a82 -
Branch / Tag:
refs/tags/v0.19.4 - Owner: https://github.com/hyriver
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@b6d0205aa211b2c1cea9be874c8ee2010ad12a82 -
Trigger Event:
workflow_dispatch
-
Statement type:







