package to manage connection swarms for your network workloads

Project description
pynetwork
High performance socket swarms for network workloads
Important Updates:
Due to some name conflict in pypi, i had to change the name of the library from "pynet" to "pynetwork"
Abstract
pynet package is designed to help write scripts/projects that rely on interprocess communication over a network with minimal-to-no knowledge of sockets. Furthermore these data transfer/steaming can be done in a swarm fashion, meaning multiple or swarm of persitant tcp connections that serve a single objective to deliver high performance. Following objectives can be achieved using this package:
- Write subroutines/functions that can stream data over to your client using callbacks (No need of polling)
- Write subroutines/functions that can send batches of data over to your client
- Send data to your subroutines/function over network
- Send files to & from server using swarm of connections for higher transfer rates
Installation
I've added this package to pypi package index,so now you can install it using pip:
pip install pynetwork
Prelude
As a fun project, i wanted a raspberry pi based RC car that can be controlled over wi-fi. On the receiver end, a combination of different deep neural network architectures that can consume the data from raspberry pi like camera feed ( to a CNN model), feed from various sensors e.g proximity, speed encoder etc ( to a RNN) & then can subsequently control it. But one of the keys problems that i faced while implementing it, was how to transfer all of this data back & forth between my laptop & pi in real time with low latency. This gave me an idea write a simple JSON based networking code that could transfer custom python objects back & forth, but that was not enough because i was dealing multiple data feeds & managing these multiple tcp connections was getting difficult. After some useless searches on github, i decided to buckle up and write down a networking library from scratch that could manage swarm of connections & also could help stream the data from python subroutines (These subroutines were pythonian generators that could endlessly read & stream the individual sensor data). Apart from subroutines based streaming, I also wanted to add batch fashioned suboutine data transfer (As you may have realized lot of these ideas sound similar to Keras generators that are used for feeding data to a machine learning model ). After a month of after-office coding & testing, I am finally releasing v2 of pynetwork. This version should not only be suitable for IOT but can be used for any network workload.
Before jumping on to some use cases, below is some nomenclatures & components that you should be aware before using it:
Gateway <--> Controller
There are 4 main components involved namely: Gateway, Controller, Handler & a Client. Gateway acts as a small server which listens
to requests made by Controller on a specified port. Gateway & Controller share a Many-to-Many relationship (One Gateway can respond
to multiple Controllers & one Controller can connect to multiple Gateways). Gateway-controller themselves do not perform any workload
operation (like data/file transfer) but instead they are responsible spawning & managing a swarm\s of tcp connections to handle
your workloads. Whenever a controller requests to a Gateway, Gateway spawns a Handler & sends an acknowledge to the Controller
then in response, Controller creates a Client for that Handler. So 1 request results in spawning of a pair of "Handler <-> Client".
A handler & a client work in tandem to handle your custom workload. To improve speed of your operation, you can spawn multiple pairs
of Handler & client. Each handler spwned at the Gateway runs on a independent thread (this is where the performance boost comes
from) & these handler threads are then managed by the Gateway. The number of possible Handlers<->Clients that can be spawned depends
the size of Handler pool (Basically a custom thread pool). By default the pool size is 5 but you can increase it to any number
depending on your hardware.
The swarm architecture looks something like this
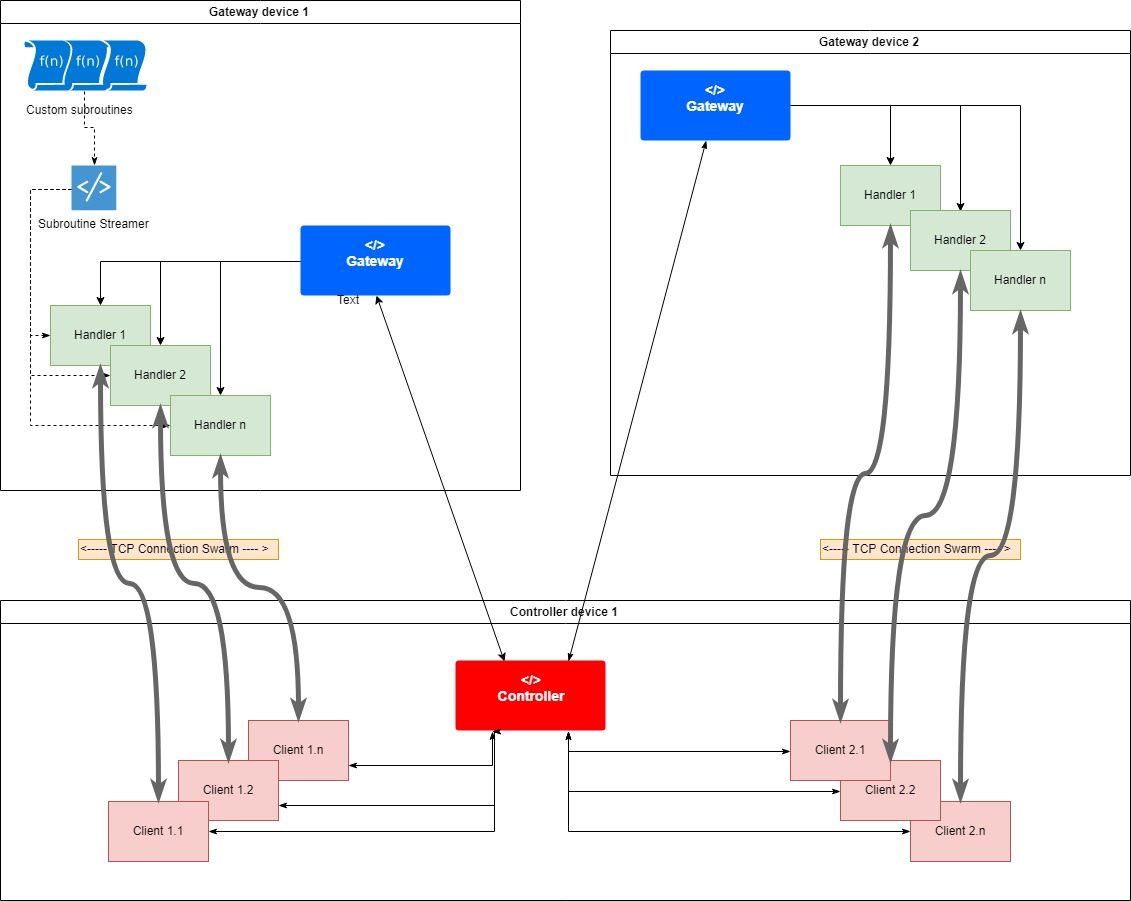
Using Gateway on Host device
gw = pynet.Gateway(port = 1857) # Define port on which gateway will listen to controller requests.
#Then register your subroutines (Either generators/ non-generators)
gw.add_subroutine('mount_usage', get_usage_percentage)
gw.add_subroutine('remove_logs', remove_logs)
#Its not necessary to add your subroutines before the gateway starts listening..
gw.start(blocking = True) #start listening to controller
#When blocking is True, then gateway will block the main thread (Similar to App.mainloop() in wxpython), untill it is closed
#by controller, If you are sure that this main thread wont run to an end, then you can set it too false or add your custom
#logic to keep this main thread alive.
Using Gateway on Client device
controller = pynet.Controller(gateway_ip = 'GATEWAY_IP', port = 1857, download_dir = 'mydir', verbose = True)
#create a controller
client1 = controller.get_client()
#When you call get_client, the controller requests for a dedicated handler with the Gateway, if the gateway 'Handler pool'
#is not full then you'll get a client instance else controller will raise an error for overflowing the pool.
#Once connected, do your stuff..
client1.ping('Hello there..')
#Once you are done, you can either close the dedicated handler for your client of the gateway itself.
client1.close_handler() #/ or client1.close_gateway() at which the gw.start(blocking = True) will stop blocking
Handler <--> Client
An individual pair of handler-client offer various options of data transfers:
-
Receive data stream from a handler subroutine
You can write python generator function that endlessly yield data (byte array) and register/add them to Gateway. Once added to Gateway, these subroutines are passed to any newly spawned handler. A client can then ask handler to stream data from this generator subroutine until it raises a StopIteration exception or returns None. Examples of such streaming could be: a. Streaming multiple sensor data b. Streaming key-presses to a key-logger over the network The data which is streamed from a generator is of byte array type data, along with this byte array data, function also needs to return an "id" (or idetity). This id can be perticualy useful when your using a swarm of connections to stream the data, because if the same function is being used my multiple handlers then there is no gaurantee of the same order in which the data was returned by the function would be preserved on the received end. In this case, you can use this id to re-arrange your data if needed.
Steps to follow to use this functionality:
a. write a python 'generator' function that yeilds byte array data The return signature expected from this function is a 'python set' with 2 elements '(ident, buffer)' where ident is an integer which represents an index for this chunk from your steam & buffer is an byte array (which is data to be streamed).
import pynetwork.backend2 as bk
def your_function_name(arg1, arg2,.., **kwargs): #parameters are optional
index =1
while condition:
pass
obj = your_logic_to_generate_data() #lets your data is a custom python obj
#if its an object, then you can use your own custom json encode/decoder
obj_str = your_json_encoder( obj)
yield (index, bk.str_to_bytes(obj_to_str))
b. you can use any of the byte conversion methods from backend2 module of the package. You can convert int, str, or JSON str, or objects (with default valued constructor) to byte array
c. The streaming will terminate when the generator raises an 'StopIteration' error or ident<0 or buffer is 'None' d. you can also terminate streaming from client side by returning 'False' in your streaming callback (User requested stream abort)
e. If streaming ends (without User requested stream abort) then client calls 'eos_callback'
f. You can also pass positional arguments & kwargs to this generator when you start the stream. (Package serializes your args & kwargs and then these params get deserialized at gateway where the function is executed with same params)
-
Receive data batch from a handler subroutine
If you need the data on transactional basis without the need of steams, you can opt for batch subroutines. These are simple python function (which doesn't need to be written as a generator) that return byte data (with unique id for that batch), then handler would steam this data across to client.
-
Send batch of data to handler subroutine
You can also send data to a subroutine whcih is registered with Gateway. This data is available as parameter called buffer in your function's kwargs input. This is additional byte array input, apart from the usual arguments & kwargs that you can pass to your subroutine. After the execution of subroutine, handler expects an integer return that is transferred back to the client as an output.
Steps to follow to use this functionality:
a. Write a function (with whatever positional/ kwargs you want) & regirster it with gateway package expects that this function would return an int which is then beamed back to client, however this int return is optiional. In case if you dont return anything, on the client side your script will receive 0.
def your_function_name(arg1, arg2,.., **kwargs):
result = 2
pass
return result #return your integer result if required
c. You can also pass positional arguments & kwargs to this generator when you start the stream. (Package serializes your args & kwargs and then these params get deserialized at gateway where the function is executed with same params)
-
Download files from Gateway to client device (from folder name & regex or fullpath to files)
No need of description here apart from the fact that, you can speed up file transfer by distributing the load across multiple connections. One important thing to note here is that, the speed improvement would be negligible if the files are less numerous & are large in size in which case your bandwidth would be the limiting factor. but in case of numerous & small sized files, you might see a conisderable improvement.(So swarm could be perticaularly useful if you are transferring log files from you application where file count is usually high & size of each log is limted to few hundered MBs) I would soon upload few stats to support above argument
-
Send files to Gateway (files are downloaded to relative said folder)
Same as above, except the direction is opposite.
-
Ping Handler to check the connection
Could be useful to test the connection.
Below are some of the use case tutorials using pynet with increasing complexity:
Tutorial 1: Conditional File Backup that uses batch data transfer
Consider a scenario where you have a limited storage on a VM node or a server and would like to to move older files from this device to your local machine when the storage usage crosses 20% (starting from the older files). This objective can be achieve as below:
On Gateway side
import pynetwork as pynet
import pynetwork.backend2 as bk
import struct
import shutil
import os
def get_usage_percentage(request_id:int, **kwargs):
'''
Logic to calculate mount/overall hdd usage
'''
total, used, free = shutil.disk_usage("\\")
usage_per = used/ total
bk.safe_print('usage', usage_per) # safe_print make sure that output from multiple client/handler threads to console do not mix-up
b = struct.pack('f', usage_per) #convert the data bytes that needs to be sent back
return b
def remove_logs(dirpath:str, **kwargs):
files = [os.path.join(dirpath,f) for f in os.listdir(dirpath)]
for f in files: #iterate over files delete each one
os.remove(f)
bk.safe_print(len(files),' files deleted')
return bk.int_to_bytes(len(files))
if __name__ == '__main__':
gw = pynet.Gateway(1857) #start gateway at port 1857
gw.add_subroutine('mount_usage', get_usage_percentage)
gw.add_subroutine('remove_logs', remove_logs)
#add above two subroutines with a key, that client can pass to request execution
gw.start(blocking = True) #start listening to controller
On Controller side
import pynetwork as pynet
import pynetwork.backend2 as bk
import struct
if __name__ == '__main__':
controller = pynet.Controller(gateway_ip = '', port = 1857, download_dir = 'mydir', verbose = True)
client1 = controller.get_client()
client1.ping('Hello there..')
b = client1.get_subroutine_batch(name ='mount_usage',arguments=[123,])
usage = struct.unpack('f', b)[0]
bk.safe_print('mount usage:', usage)
if usage > 0.2:
bk.safe_print('downloading files..')
client1.get_files_from_gateway(folder = 'D:\logs', regex = '.+RFIN703235761L') #using regex, u can filter files within a folder
#in this case, we are only downloading log file belonging to tensorflow as a test
count_bytes = client1.get_subroutine_batch(name ='remove_logs',arguments=['D:\logs',])
bk.safe_print(bk.bytes_to_int(count_bytes),' files deleted')
else:
pass
client1.close_handler() #close handler so the handler pool at gateway will remain empty for others
#additionally you can also stop Gatway by: client1.close_gateway()
Additionaly, you can also add logic in 'remove_logs' function to remove files before a specific date & so on. Since you can integrate any custom logic in your python subroutine, the possibilities are endless.
Few things to be considered while writing a subroutine for receiving batch data (Handler -> Client):
a. Function can have arguments & kwargs as an input, here arguments represent positional arguments (Against the usual python convetion) sorry for this mess, i will change the name in next release b. The function need to return the data in byte format. So function can either one of the methoeds available in backed to convert int, str to byes (I would add support float soon, but meanwhile you can use struct package). Furthermore, if you want to return a custom class then you use your own custom encode to serialize object to JSON string & then using backed to convert this string to bytes, then on the controller side do the opposite. If you want to use the object serialization which available in backend then you can add your class to the "Handshakes file" to use in-built serializtion, but it is important that you have primitive data-types in your class & have default values assigned to all the input parameters in init method of your class. I will make some change in serialization to give more freedom for class defination in next release
Few things to be considered while writing a subroutine for transmitting batch data (Client -> Handler):
a. Function can have arguments & kwargs as an input, here arguments represent positional arguments (Against the usual python convetion) b. The function need to return the integer result in byte format which will be beamed back to client as a result
Tutorial 2: Raspberry-Pi control over wifi (uses both streaming & batch data transfer)
Work in progress.. Will post in 1-2 days!


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pynetwork-2.4.tar.gz.
File metadata
- Download URL: pynetwork-2.4.tar.gz
- Upload date:
- Size: 18.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/3.5.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ac99f4031256cef8d65635db5ec8bdbb61ce7b7f12ceaf4232d46e577d21b1ce
|
|
| MD5 |
69c910ef683d1818853c758aa9cf8b58
|
|
| BLAKE2b-256 |
abc7c72c770ef03162e3d1fe3e65d5b0419eb98b8efe2042e0c5c349a09a1527
|
File details
Details for the file pynetwork-2.4-py3-none-any.whl.
File metadata
- Download URL: pynetwork-2.4-py3-none-any.whl
- Upload date:
- Size: 24.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/3.5.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
41a9fa75a8af0742c962066ad7c1c60a9c1272ad6fee45b1641271dbd81876ff
|
|
| MD5 |
5f041c0646dad4b27395d02503b6cd13
|
|
| BLAKE2b-256 |
5585b9e56734e411220b431d0dbd137fdc9cf1478f4d6d991b32e1cd9b9d6e99
|







