A Python library for anomaly detection across tabular, time series, graph, text, image, and audio data. 61 detectors, benchmark-backed ADEngine orchestration, and an agentic workflow for AI agents.

Project description
PyOD 3: Agentic Anomaly Detection At Scale











PyOD is agent-ready. Claude Code and Codex can use the od-expert skill to drive ADEngine investigations, while MCP-compatible agents can query PyOD’s detector knowledge and planning tools. The classic fit/predict API stays unchanged.
PyOD 3 is the most comprehensive Python library for anomaly detection. Four pillars:
Pillar |
What it means |
|---|---|
Multi-Modal |
61 detectors across tabular, time series, graph, text, image, and audio data, one API |
Full Lifecycle |
From raw data to explained anomalies and next-step guidance in a single call |
Agentic |
od-expert turns natural-language requests into ADEngine workflows; MCP exposes structured tools for other agents |
Most Used |
46+ million downloads; benchmark-backed routing (ADBench, TSB-AD, BOND, NLP-ADBench) |
Install
Core library (required for every activation path):
pip install pyodThen pick the activation path that matches your agent stack:
# 1. Claude Code / Claude Desktop / Codex — enables the od-expert skill
pyod install skill # Claude Code / Desktop: user-global (~/.claude/skills/)
pyod install skill --project # Codex: project-local (./skills/, Codex has no user-global dir)
# 2. Any MCP-compatible LLM — requires the optional mcp extra
pip install pyod[mcp]
pyod mcp serve # alias for `python -m pyod.mcp_server`
# 3. Pure Python — no extra step
# from pyod.utils.ad_engine import ADEngineRun pyod info at any time to see version, detector counts, and the install state of each activation path. pyod info also detects which agent stack you have installed (~/.claude/ for Claude Code, ~/.codex/ for Codex) and recommends the right install command.
For conda, source install, dependency details, and troubleshooting, see the full installation guide. The legacy pyod-install-skill command from v3.0.0 still works as an alias for pyod install skill.
Outlier Detection with 5 Lines of Code (pip install pyod):
from pyod.models.iforest import IForest
clf = IForest()
clf.fit(X_train)
y_train_scores = clf.decision_scores_ # training anomaly scores
y_test_scores = clf.decision_function(X_test) # test anomaly scoresThree ways to use PyOD:
Layer |
Name |
When to use |
Entry point |
|---|---|---|---|
1 |
Classic API |
You know which detector you want |
|
2 |
ADEngine |
You want PyOD to choose, compare, and assess automatically |
|
3 |
Agentic Investigation |
You want an AI agent to drive OD through natural conversation |
Layers 2 and 3 are powered by ADEngine, PyOD’s lifecycle orchestration core. The full multi-turn Layer 3 investigation flow is available through the od-expert skill for Claude Code and Codex. The MCP server (python -m pyod.mcp_server) exposes ten stateless tools for MCP-compatible LLMs, spanning knowledge queries (list_detectors, explain_detector, compare_detectors, get_benchmarks), planning (profile_data, plan_detection, build_detector), and detection (run_detection, analyze_results, explain_findings); stateful investigate / iterate MCP tools are deferred.
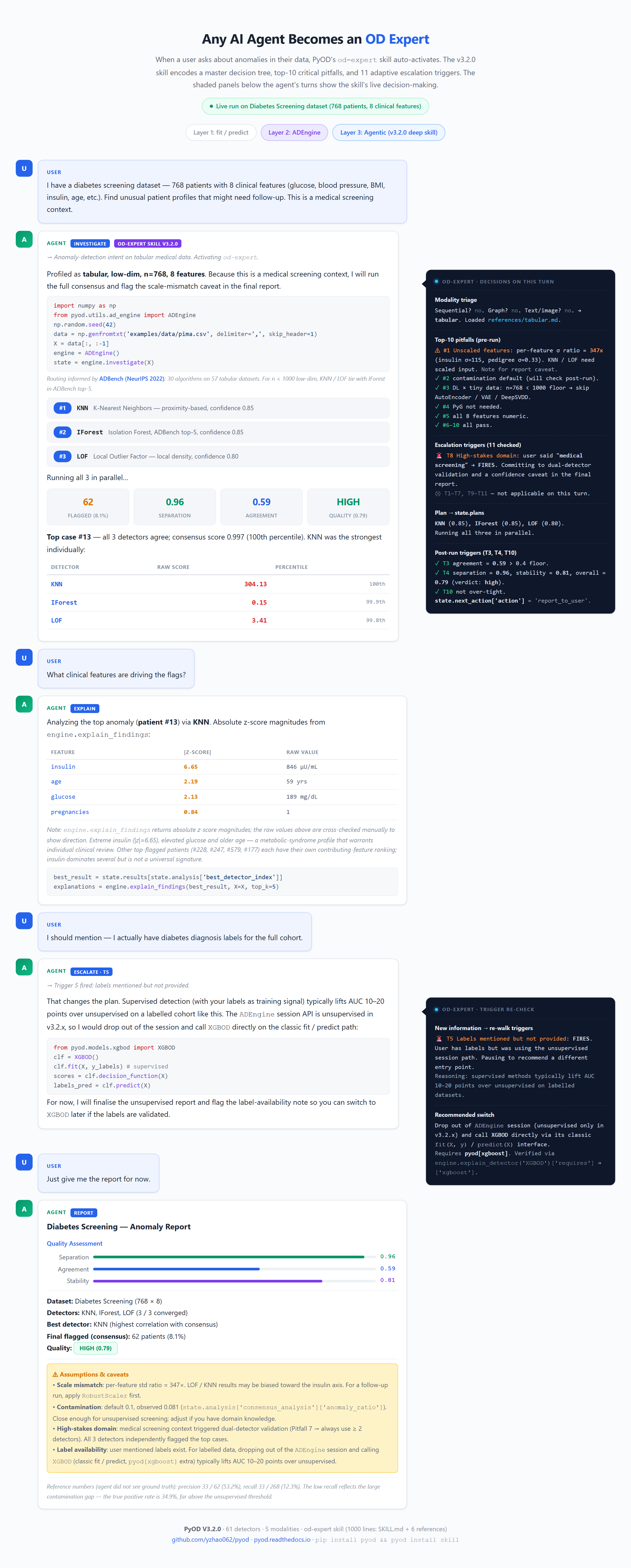
The figure above shows a real 5-turn agentic conversation on the UCI Cardiotocography dataset. See the full walkthrough, runnable agentic example, or interactive HTML demo.
PyOD Ecosystem & Resources: NLP-ADBench (NLP anomaly detection) | TODS (time-series) | PyGOD (graph) | ADBench (benchmark) | AD-LLM (LLM-based AD) [50] | Resources
About PyOD
PyOD, established in 2017, is the longest-running and most widely used Python library for anomaly detection. With 46+ million downloads, it serves both academic research (featured in Analytics Vidhya, KDnuggets, and Towards Data Science) and commercial products.
V3 extends the library with ADEngine (lifecycle orchestration) and the od-expert skill (agentic workflow), while keeping the classic fit/predict API fully backward-compatible. V3 is built on SUOD [55] for fast parallel training and numba JIT for per-model speedups.
Impact & Recognition:
Area |
Examples |
|---|---|
Space & science |
European Space Agency OPS-SAT spacecraft telemetry benchmark (Nature Scientific Data, 2025) uses PyOD for all 30 algorithms. |
Enterprise deployment |
Walmart (1M+ daily pricing updates, KDD 2019), Databricks (Kakapo framework integrating PyOD with MLflow/Hyperopt; insider-threat detection solution), IQVIA (123K+ pharmacy claims), Altair AI Studio, Ericsson (patent WO2023166515A1). |
Books |
Outlier Detection in Python (Brett Kennedy, Manning); Handbook of Anomaly Detection with Python (Chris Kuo, Columbia); Finding Ghosts in Your Data (Kevin Feasel, Apress). |
Courses |
DataCamp Anomaly Detection in Python (19M+ platform learners), Manning liveProject, O’Reilly video edition, multiple Udemy courses. |
Podcasts |
|
International |
Tutorials in 5 non-English languages: Chinese (CSDN, Zhihu, 搜狐, 机器之心, aidoczh.com full doc translation), Japanese, Korean, German, Spanish. |
See the full impact page on Read the Docs for the complete list of citations, enterprise deployments, patents, and media coverage.
Citing PyOD:
If you use PyOD in a scientific publication, we would appreciate citations to the following paper(s):
PyOD 2: A Python Library for Outlier Detection with LLM-powered Model Selection is available as a preprint. If you use PyOD in a scientific publication, we would appreciate citations to the following paper:
@inproceedings{chen2025pyod,
title={Pyod 2: A python library for outlier detection with llm-powered model selection},
author={Chen, Sihan and Qian, Zhuangzhuang and Siu, Wingchun and Hu, Xingcan and Li, Jiaqi and Li, Shawn and Qin, Yuehan and Yang, Tiankai and Xiao, Zhuo and Ye, Wanghao and others},
booktitle={Companion Proceedings of the ACM on Web Conference 2025},
pages={2807--2810},
year={2025}
}
PyOD paper is published in Journal of Machine Learning Research (JMLR) (MLOSS track).:
@article{zhao2019pyod,
author = {Zhao, Yue and Nasrullah, Zain and Li, Zheng},
title = {PyOD: A Python Toolbox for Scalable Outlier Detection},
journal = {Journal of Machine Learning Research},
year = {2019},
volume = {20},
number = {96},
pages = {1-7},
url = {http://jmlr.org/papers/v20/19-011.html}
}
or:
Zhao, Y., Nasrullah, Z. and Li, Z., 2019. PyOD: A Python Toolbox for Scalable Outlier Detection. Journal of machine learning research (JMLR), 20(96), pp.1-7.
For a broader perspective on anomaly detection, see our NeurIPS papers on ADBench [17] and ADGym.
Table of Contents:
Implemented Algorithms (Tabular, Time Series, Graph, Embedding)
Additional Topics (Model Save/Load, SUOD, Thresholding)
API Cheatsheet & Reference
The full API Reference is split by modality at PyOD Documentation: Tabular, Time Series, Graph, Embedding, ADEngine, Utilities. Below is a quick cheatsheet for all detectors:
fit(X): Fit the detector. The parameter y is ignored in unsupervised methods.
decision_function(X): Predict raw anomaly scores for X using the fitted detector.
predict(X): Determine whether a sample is an outlier or not as binary labels using the fitted detector.
predict_proba(X): Estimate the probability of a sample being an outlier using the fitted detector.
predict_confidence(X): Assess the model’s confidence on a per-sample basis (applicable in predict and predict_proba) [38].
predict_with_rejection(X): Allow the detector to reject (i.e., abstain from making) highly uncertain predictions (output = -2) [39].
Key Attributes of a fitted model:
decision_scores_: Outlier scores of the training data. Higher scores typically indicate more abnormal behavior. Outliers usually have higher scores.
labels_: Binary labels of the training data, where 0 indicates inliers and 1 indicates outliers/anomalies.
Benchmarks
ADBench [17]: 30 algorithms on 57 tabular datasets. See comparison.
NLP-ADBench: 19 methods on 8 text datasets. Two-step (embedding + detector) beats end-to-end.
TSB-AD [70]: 40 algorithms on 1070 time series datasets (NeurIPS 2024).
BOND [71]: 14 graph anomaly detection algorithms on 14 datasets (NeurIPS 2022).
Additional Topics
Model Save & Load: Use joblib or pickle for saving and loading PyOD models. See example.
Fast Train with SUOD: Accelerate training and prediction with the SUOD framework [55]. See example.
Thresholding Outlier Scores: Data-driven approaches for setting contamination levels via PyThresh.
Implemented Algorithms
PyOD is organized into two functional groups: (i) Detection Algorithms, with dedicated subsections for tabular, time series, graph, and audio data (EmbeddingOD inside the tabular table adds text and image support via foundation model encoders); and (ii) Utility Functions for data generation, evaluation, and lifecycle orchestration.
(i-a) Tabular & Multi-Modal Detection Algorithms :
Type |
Abbr |
Algorithm |
Year |
Ref |
|---|---|---|---|---|
Probabilistic |
ECOD |
Unsupervised Outlier Detection Using Empirical Cumulative Distribution Functions (example) |
2022 |
|
Probabilistic |
ABOD |
Angle-Based Outlier Detection (example) |
2008 |
|
Probabilistic |
FastABOD |
Fast Angle-Based Outlier Detection using approximation (example) |
2008 |
|
Probabilistic |
COPOD |
COPOD: Copula-Based Outlier Detection (example) |
2020 |
|
Probabilistic |
MAD |
Median Absolute Deviation (MAD) (example) |
1993 |
|
Probabilistic |
SOS |
Stochastic Outlier Selection (example) |
2012 |
|
Probabilistic |
QMCD |
Quasi-Monte Carlo Discrepancy outlier detection (example) |
2001 |
|
Probabilistic |
KDE |
Outlier Detection with Kernel Density Functions (example) |
2007 |
|
Probabilistic |
Sampling |
Rapid distance-based outlier detection via sampling (example) |
2013 |
|
Probabilistic |
GMM |
Probabilistic Mixture Modeling for Outlier Analysis (example) |
[1] [Ch.2] |
|
Linear Model |
PCA |
Principal Component Analysis (sum of weighted projected distances to eigenvector hyperplanes) (example) |
2003 |
|
Linear Model |
KPCA |
Kernel Principal Component Analysis (example) |
2007 |
|
Linear Model |
MCD |
Minimum Covariance Determinant (Mahalanobis distances as outlier scores) (example) |
1999 |
|
Linear Model |
CD |
Cook’s distance for outlier detection (example) |
1977 |
|
Linear Model |
OCSVM |
One-Class Support Vector Machines (example) |
2001 |
|
Linear Model |
LMDD |
Deviation-based Outlier Detection (LMDD) (example) |
1996 |
|
Proximity-Based |
LOF |
Local Outlier Factor (example) |
2000 |
|
Proximity-Based |
COF |
Connectivity-Based Outlier Factor (example) |
2002 |
|
Proximity-Based |
(Incr.) COF |
Memory Efficient Connectivity-Based Outlier Factor (slower, reduced storage) (example) |
2002 |
|
Proximity-Based |
CBLOF |
Clustering-Based Local Outlier Factor (example) |
2003 |
|
Proximity-Based |
LOCI |
LOCI: Fast outlier detection via local correlation integral (example) |
2003 |
|
Proximity-Based |
HBOS |
Histogram-based Outlier Score (example) |
2012 |
|
Proximity-Based |
HDBSCAN |
Density-based clustering via hierarchical density estimates (example) |
2013 |
|
Proximity-Based |
kNN |
k Nearest Neighbors (distance to k-th neighbor as outlier score) (example) |
2000 |
|
Proximity-Based |
AvgKNN |
Average kNN (average distance to k neighbors as outlier score) (example) |
2002 |
|
Proximity-Based |
MedKNN |
Median kNN (median distance to k neighbors as outlier score) (example) |
2002 |
|
Proximity-Based |
SOD |
Subspace Outlier Detection (example) |
2009 |
|
Proximity-Based |
ROD |
Rotation-based Outlier Detection (example) |
2020 |
|
Outlier Ensembles |
IForest |
Isolation Forest (example) |
2008 |
|
Outlier Ensembles |
INNE |
Isolation-based Anomaly Detection via Nearest-Neighbor Ensembles (example) |
2018 |
|
Outlier Ensembles |
DIF |
Deep Isolation Forest for Anomaly Detection (example) |
2023 |
|
Outlier Ensembles |
FB |
Feature Bagging (example) |
2005 |
|
Outlier Ensembles |
LSCP |
LSCP: Locally Selective Combination of Parallel Outlier Ensembles (example) |
2019 |
|
Outlier Ensembles |
XGBOD |
Extreme Boosting Based Outlier Detection (Supervised) (example) |
2018 |
|
Outlier Ensembles |
LODA |
Lightweight On-line Detector of Anomalies (example) |
2016 |
|
Outlier Ensembles |
SUOD |
SUOD: Accelerating Large-scale Unsupervised Heterogeneous OD (Acceleration) (example) |
2021 |
|
Neural Networks |
AutoEncoder |
Fully connected AutoEncoder (reconstruction error as outlier score) (example) |
[1] [Ch.3] |
|
Neural Networks |
VAE |
Variational AutoEncoder (reconstruction error as outlier score) (example) |
2013 |
|
Neural Networks |
Beta-VAE |
Variational AutoEncoder with customized loss (gamma and capacity) (example) |
2018 |
|
Neural Networks |
SO_GAAL |
Single-Objective Generative Adversarial Active Learning (example) |
2019 |
|
Neural Networks |
MO_GAAL |
Multiple-Objective Generative Adversarial Active Learning (example) |
2019 |
|
Neural Networks |
DeepSVDD |
Deep One-Class Classification (example) |
2018 |
|
Neural Networks |
AnoGAN |
Anomaly Detection with Generative Adversarial Networks |
2017 |
|
Neural Networks |
ALAD |
Adversarially learned anomaly detection (example) |
2018 |
|
Neural Networks |
AE1SVM |
Autoencoder-based One-class Support Vector Machine (example) |
2019 |
|
Neural Networks |
DevNet |
Deep Anomaly Detection with Deviation Networks (example) |
2019 |
|
Graph-based |
R-Graph |
Outlier detection by R-graph (example) |
2017 |
|
Graph-based |
LUNAR |
LUNAR: Unifying Local OD Methods via Graph Neural Networks (example) |
2022 |
|
Embedding-based |
EmbeddingOD |
Multi-modal anomaly detection via foundation model embeddings, text, image, and audio (example) |
2025 |
Ensemble methods (IForest, INNE, DIF, FB, LSCP, LODA, SUOD, XGBOD) are included in the table above. Score combination functions (average, maximization, AOM, MOA, median, majority vote) are in pyod.models.combination. See API docs for details.
(i-b) Time Series Anomaly Detection :
All time series detectors use the same fit/predict/decision_function API as tabular detectors, with one exception: MatrixProfile is transductive (train-only; use decision_scores_ and labels_ after fit(), no out-of-sample predict).
Input format: numpy array of shape (n_timestamps,) for univariate or (n_timestamps, n_channels) for multivariate. Each row is one timestep; columns are channels/features. Pandas DataFrames and lists are auto-converted. Output: decision_scores_ of shape (n_timestamps,) with one anomaly score per timestep.
Time series detection in 3 lines:
from pyod.models.ts_kshape import KShape # or any TS detector
clf = KShape(window_size=20)
clf.fit(X_train) # shape (n_timestamps,) or (n_timestamps, n_channels)
scores = clf.decision_scores_ # per-timestamp anomaly scoresAlgorithm rankings from TSB-AD benchmark [70] (NeurIPS 2024, 1070 datasets):
Type |
Abbr |
Algorithm |
Year |
Ref |
|---|---|---|---|---|
Windowed Bridge |
TimeSeriesOD |
Any PyOD detector on sliding windows (example) |
2026 |
|
Subsequence |
MatrixProfile |
Matrix Profile via STOMP, transductive (example) |
2016 |
|
Frequency |
SpectralResidual |
Spectral Residual: FFT-based saliency (example) |
2019 |
|
Clustering |
KShape |
k-Shape clustering (#2 in TSB-AD) (example) |
2015 |
|
Streaming |
SAND |
Streaming with drift adaptation, experimental (example) |
2021 |
|
Deep Learning |
LSTMAD |
LSTM prediction error + Mahalanobis scoring |
2015 |
|
Deep Learning |
AnomalyTransformer |
Transformer with association discrepancy (experimental) |
2022 |
(i-c) Graph Anomaly Detection (pip install pyod[graph]):
All graph detectors are transductive in v1: use decision_scores_ and labels_ after fit(). No out-of-sample predict. Input: PyG Data object with x (node features) and edge_index (COO edges). SCAN works without features.
Graph detection in 3 lines (pip install pyod[graph]):
from pyod.models.pyg_dominant import DOMINANT
clf = DOMINANT(hidden_dim=64, epochs=100)
clf.fit(data) # PyG Data object
scores = clf.decision_scores_ # per-node anomaly scoresAlgorithm rankings from BOND benchmark [71] (NeurIPS 2022, 14 datasets):
Type |
Abbr |
Algorithm |
Year |
Ref |
|---|---|---|---|---|
GCN Autoencoder |
DOMINANT |
GCN AE, structure + attribute reconstruction (#1 BOND deep) (dominant example) |
2019 |
|
Contrastive |
CoLA |
Contrastive self-supervised, local neighbor context (#2 BOND deep) (cola example) |
2022 |
|
Contrastive+AE |
CONAD |
Contrastive with anomalous-view injection + dual reconstruction (conad example) |
2022 |
|
Attention AE |
AnomalyDAE |
GAT structure encoder + MLP attribute encoder (anomalydae example) |
2020 |
|
Motif AE |
GUIDE |
Dual GCN AE on original + triangle-motif adjacency (guide example) |
2021 |
|
Matrix Factor. |
Radar |
Residual analysis via matrix factorization (radar example) |
2017 |
|
Matrix Factor. |
ANOMALOUS |
Joint MF with Laplacian regularization (anomalous example) |
2018 |
|
Structural |
SCAN |
Structural clustering, no features needed (scan example) |
2007 |
(i-d) Audio Anomaly Detection (pip install pyod[audio]):
Audio clips use the same fit/decision_function API. Two paths are available: a lightweight embed-then-detect path (EmbeddingOD.for_audio() turns each clip into a 74-dimensional handcrafted acoustic vector and runs any classical detector), and a dedicated deep detector (AudioAE, a log-mel reconstruction autoencoder). Inputs are file paths, waveform arrays, or (waveform, sample_rate) tuples. Output: one anomaly score per clip.
Audio detection in 3 lines (pip install pyod[audio]):
from pyod.models.embedding import EmbeddingOD
clf = EmbeddingOD.for_audio('balanced') # 74-dim handcrafted features + KNN
clf.fit(train_clips) # list of file paths or waveform arrays
scores = clf.decision_scores_ # per-clip anomaly scoresType |
Abbr |
Algorithm |
Year |
Ref |
|---|---|---|---|---|
Embed then Detect |
EmbeddingOD |
for_audio(): 74-dim MFCC, chroma, and spectral features with any detector |
2026 |
|
Deep AE |
AudioAE |
Log-mel reconstruction autoencoder (DCASE 2020 Task 2 baseline) |
2020 |
(ii) Utility Functions:
Type |
Name |
Function |
|---|---|---|
Data |
generate_data |
Synthesized data generation; normal data from multivariate Gaussian, outliers from uniform distribution |
Data |
generate_data_clusters |
Synthesized data generation in clusters for more complex patterns |
Evaluation |
evaluate_print |
Print ROC-AUC and Precision @ Rank n for a detector |
Evaluation |
precision_n_scores |
Calculate Precision @ Rank n |
Utility |
get_label_n |
Turn raw outlier scores into binary labels by assigning 1 to the top n scores |
Stat |
wpearsonr |
Calculate the weighted Pearson correlation of two samples |
Encoding |
resolve_encoder |
Resolve an encoder from a string name, BaseEncoder instance, or callable |
Encoding |
SentenceTransformerEncoder |
Encode text via sentence-transformers models (e.g., MiniLM, mpnet) |
Encoding |
OpenAIEncoder |
Encode text via OpenAI Embeddings API (text-embedding-3-small/large) |
Encoding |
HuggingFaceEncoder |
Encode text or images via HuggingFace transformers (BERT, DINOv2, CLIP) |
Quick Start for Outlier Detection
PyOD has been well acknowledged by the machine learning community with a few featured posts and tutorials.
Analytics Vidhya: An Awesome Tutorial to Learn Outlier Detection in Python using PyOD Library
KDnuggets: Intuitive Visualization of Outlier Detection Methods, An Overview of Outlier Detection Methods from PyOD
Towards Data Science: Anomaly Detection for Dummies
“examples/knn_example.py” demonstrates the basic API of using kNN detector. It is noted that the API across all other algorithms are consistent/similar.
More detailed instructions for running examples can be found in examples directory.
Initialize a kNN detector, fit the model, and make the prediction.
from pyod.models.knn import KNN # kNN detector # train kNN detector clf_name = 'KNN' clf = KNN() clf.fit(X_train) # get the prediction label and outlier scores of the training data y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers) y_train_scores = clf.decision_scores_ # raw outlier scores # get the prediction on the test data y_test_pred = clf.predict(X_test) # outlier labels (0 or 1) y_test_scores = clf.decision_function(X_test) # outlier scores # it is possible to get the prediction confidence as well y_test_pred, y_test_pred_confidence = clf.predict(X_test, return_confidence=True) # outlier labels (0 or 1) and confidence in the range of [0,1]Evaluate the prediction by ROC and Precision @ Rank n (p@n).
from pyod.utils.data import evaluate_print # evaluate and print the results print("\nOn Training Data:") evaluate_print(clf_name, y_train, y_train_scores) print("\nOn Test Data:") evaluate_print(clf_name, y_test, y_test_scores)See a sample output & visualization.
On Training Data: KNN ROC:1.0, precision @ rank n:1.0 On Test Data: KNN ROC:0.9989, precision @ rank n:0.9visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False)
Acknowledgments
This material is based upon work supported by the National Science Foundation under Award No. 2346158 for “NSF POSE: Phase II: OpenAD: An Integrated Open-Source Ecosystem for Anomaly Detection.” The award lists the University of Illinois Chicago as the lead organization and Illinois Institute of Technology, Lehigh University, and the University of Southern California as sub-awardee organizations.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Reference
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyod-3.6.2.tar.gz.
File metadata
- Download URL: pyod-3.6.2.tar.gz
- Upload date:
- Size: 347.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b6c660a0878bfab357d617ef72ea3d79cf695ed7545fa326b7ae2b520acfab83
|
|
| MD5 |
a78cbbc714e6b61eb196a082c11c5378
|
|
| BLAKE2b-256 |
e7fae4cdc9ff3c64ff5cd8bc3a98fe0bbd9890a5cc98fa448069d594227668e2
|
File details
Details for the file pyod-3.6.2-py3-none-any.whl.
File metadata
- Download URL: pyod-3.6.2-py3-none-any.whl
- Upload date:
- Size: 412.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
029e1558d7120df4aab457cbf9acadbd7de95ed3fa9b14d43c5e45ca53530561
|
|
| MD5 |
9d4a7f09aef647a1fc765d151355aa70
|
|
| BLAKE2b-256 |
5e6e48111e0e8756f24dca0e255971734ea18a4905b0e0b66c0452452e3563d5
|







