A python package to help facilitate the collection and analysis of education-related datasets.

Project description
pypeds 
This is a python package aiming to analyze IPEDS and other education datasets using the data science tools available within python. Dare I say, enrollment science tools?
WARNING: This is a very young project with exploration around the API and the toolkits included.
Install and Test Notes
Installation of pypeds is as simple as pip install pypeds.
It is highly recommended that you leverage the use of environments when coding in python; at least that is my opinion anyway. I prefer to use conda for my environment management. Assuming that you have conda setup properly, this could be as simple as:
conda create -n pypeds python=3.6
conda activate pypeds
pip install pypeds
Alternatively, if you want to use the development version of this package, you can review this Google Colab Notebook which provides an installation overview to install from this repository. You can replicate this process anytime you want code/analyze data using Google's fantastic notebook coding environment.
Last but not least, it's worth stating that you could just as easily install pypeds via collab with:
!pip install pypeds
Basic Usage
The years argument is based on the survey year shown on the IPEDS website. When the datasets are built, this package adds both the survey year and the fall year (of the academic year) to the datasets. For example, the survey SFA (Student Financial Aid) for the survey year 2017 is reporting on data for the 1617 academic year, so I include fall_year with a value of 2016 in this case.
Below is a simple session to get the last 2 years of the directory information surveys:
from pypeds import ipeds
# generate a list of survey years -- this must be a python list
# YEARS = list(range(2014, 2018, 1)) ## another way to create a range of years
YEARS = [2019,2020]
# instantiate the survey of interest
hd = ipeds.HD(years=YEARS)
# extract, or download the surveys
hd.extract()
# load the surveys as an explicit pandas dataframe in your session
df = hd.load()
# confirm that we have the data we expected
df.survey_year.value_counts()
2019.0 6559
2020.0 6440
This package aims to be a go-to resource for those of us who analyze data in higher education, and perhaps more specifically, enrollment management. As such, I have chosen an API scheme that hopefully will make your transition to python easier, especially as you transition into machine learning with scikit-learn. The use of classes and methods is heavily inspired by that toolkit.
Moreover, this package attempts to remove the friction of data prep as much as possible. For that reason, and also borrowing from the tidyverse use of verbs for data munging, the API is built around the idea of ETL (Extract, Transform, Load) as well as common Exploratory Data Analysis (EDA) concepts. Below is an outline of the tools
- Instantiate the survey of interest with
ipeds.IC()oripeds.HD(). The years argument defaults to the current survey (2017) year but can setup with a list of years. For example,ipeds.HD(years=[2016,2017])as well. - Next, we
.extractthe data, which collects 1 or more years of full survey datasets from IPEDS and keeps the data within our survey object. - Optionally, you can
.transformthe data. This will supply functionality to modify the survey data by filtering rows, selecting columns, or deriving new columns using commonly accepted logic in order to establish standard definitions. Again, the aim is to make things easier. - Lastly,
.loadpulls out the survey datasets as a pandas dataframe, at which point you can analyze, visualize the survey dataset using the full suite of data analytics tools found within python.
This package is under heavy development and as noted at the top, is subject to breaking changes within the API. However, beyond the ETL verbs, this package will also include various methods for exploration, competitive benchmarking, and data visualization. While all of this work can be done by the analyst after the .load method, the aim is facilitate learning and insight by extracting away the "how" for basic and common questions in the enrollment management space.
Surveys currently supported:
- HD: Directory Info [HD]
- IC: Institutional Characteristics, which also merges on the ADM survey which started in 2014 [IC]
- SFA: Student Financial Aid [SFA]
- EF_C: Residence and Migration of First-Time Freshmen [EFC]
- EF_D: Total entering class, retention rates, and student-to-faculty ratio [EFD]
- IC_AY: Charges for Academic Year Programs [ICAY]
- C_A: Awards/degrees conferred by program (6-digit CIP code), award level, race/ethnicity, and gender [C_A]
- OM: Award and enrollment data at four, six and eight years of entering degree/certificate-seeking undergraduate cohorts [OM]
- FF1: Finance, Public institutions - GASB [FF1]
- FF2: Private not-for-profit institutions or Public institutions using FASB [FF2]
The class names are in the brackets. For example, the EF_C survey can be instantiated using ipeds.EFC().
Additional datasets
This package will also periodically add datasets that one might use when studying and analyzing data in higher education and enrollment management.
Most notably, once importing the datasets module, pypeds attempts to provide simple access to core education-related datasets. For example:
wichefor data, and projections, of high school graduates in the US by state.- In addition to above, there are other datasets to help with mapping code and geographies for easier reporting and visualization.
For example, let's play around with the WICHE projections below.
WICHE High School Projections
For example, you might want to look at the WICHE projections for High School Graduates. The data are currently included in this package via the datasets module.
# import the datasets module
from pypeds import datasets
# extract the wiche dataset
wiche = datasets.wiche()
# first few rows
wiche.head(1).T
0
stabbr _M
schoolyear 2000-01
raceethnicity American Indian/Alaska Native
gradelevel Grade 1
schoolsector Public Schools
projection Reported/Actual
students 5106
statename Midwest
region_wiche Midwest
region_census_division NaN
region_census NaN
You will notice that the data are not wide, but long. This is by design, and it allows us to reshape and aggregate as desired.
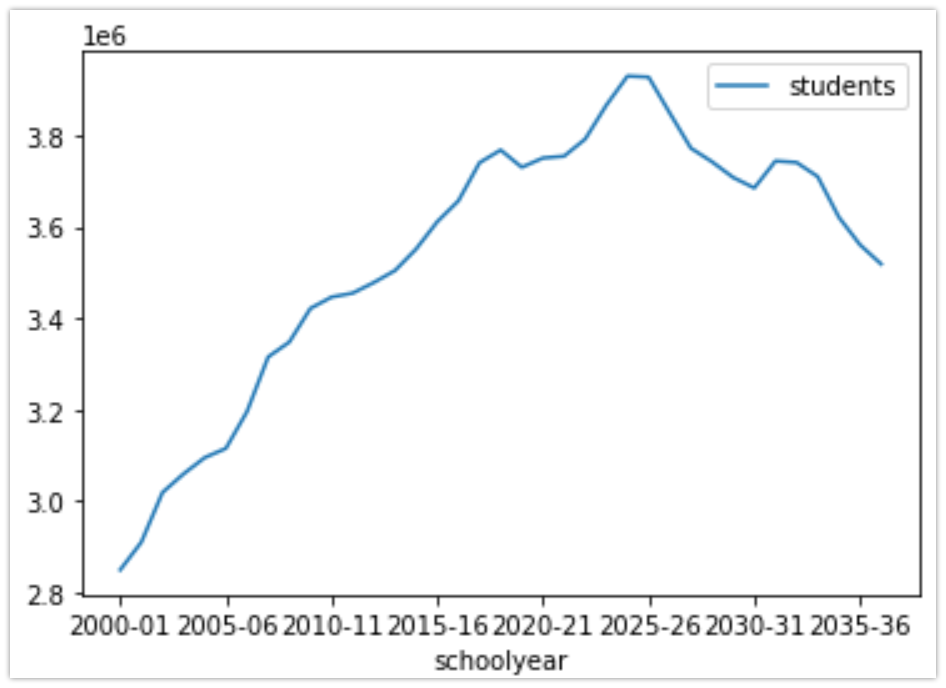
For example, plot the actual and projected (the projection column) total high school graduates (gradelevel and raceethnicity columns) in the dataset.
# isolate total grads, but still for each state and year
all_grads = wiche.loc[(wiche.gradelevel=='Graduates') & (wiche.raceethnicity=='Total') & (wiche.statename == 'United States') & (wiche.schoolsector == 'Grand Total Public & Private'), : ]
# you will notice that we have to filter the dataset to get total US high school grads, but it highlights the resolution of the data!
# generate the line plot
all_grads.plot(x="schoolyear", y="students", kind="line")
Future work
- include tooling to help analysts connect to Salesforce or Data Warehouses/Databases
- submit via pypeds
- additional higher education datasets
- Pull in Wikipedia links and pageview trends
Notes
- It appears that the mission statement data is not part of the full surveys, but is included in the MS Access version. Obviously it's less than ideal that the data collected is not included within the full file option, which this package highly leverages.
Resources:
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pypeds-2023.820.tar.gz.
File metadata
- Download URL: pypeds-2023.820.tar.gz
- Upload date:
- Size: 107.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.21.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
db98cc13927c7dc90a987585ad146cd5d0992988e7118ae0f306703883199e66
|
|
| MD5 |
4a656247ec4b2825b1c9347391cfa7a8
|
|
| BLAKE2b-256 |
bcb88af9469110461fc6a1b728974b01c2c8755f74c4230793532bf6048b8af5
|
File details
Details for the file pypeds-2023.820-py3-none-any.whl.
File metadata
- Download URL: pypeds-2023.820-py3-none-any.whl
- Upload date:
- Size: 29.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.21.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c9312965d007f69806e1dc3bad200c467e2747a82b4794fd1ab28fe57abe1055
|
|
| MD5 |
79a348bb49bcad9e9fa4d1c3dc7064bb
|
|
| BLAKE2b-256 |
2325c5d68b00b6eaa67e08055a3f29adaf54000dfb06f9acb16da9ef6d0f9fbb
|







