Python library which implements Successive Halving and Classification algorithm

Project description
PySHAC : A Python Library for Sequential Halving and Classification Algorithm







PySHAC is a python library to use the Sequential Halving and Classification algorithm from the paper Parallel Architecture and Hyperparameter Search via Successive Halving and Classification with ease.
Note : This library is not affiliated with Google.
Documentation
Stable build documentation can be found at PySHAC Documentation.
It contains a User Guide, as well as explanation of the different engines that can be used with PySHAC.
| Topic | Link |
|---|---|
| Installation | http://titu1994.github.io/pyshac/install/ |
| User Guide | http://titu1994.github.io/pyshac/guide/ |
| Managed Engines | http://titu1994.github.io/pyshac/managed/ |
| Custom Hyper Parameters | http://titu1994.github.io/pyshac/custom-hyper-parameters/ |
| Serial Evaluation | http://titu1994.github.io/pyshac/serial-execution/ |
| External Dataset Training | http://titu1994.github.io/pyshac/external-dataset-training/ |
| Callbacks | http://titu1994.github.io/pyshac/callbacks/ |
Installation
This library is available for Python 2.7 and 3.4+ via pip for Windows, MacOSX and Linux.
pip install pyshac
To install the master branch of this library :
git clone https://github.com/titu1994/pyshac.git
cd pyshac
pip install .
or pip install .[tests] # to also include dependencies necessary for testing
To install the requirements before installing the library :
pip install -r "requirements.txt"
To build the docs, additional packages must be installed :
pip install -r "doc_requirements.txt"
Getting started with PySHAC
First, build the set of hyper parameters. The three main HyperParameter classes are :
- DiscreteHyperParameter
- UniformContinuousHyperParameter
- NormalContinuousHyperParameter
There are also 3 additional hyper parameters, which are useful when a parameter needs to be sampled multiple times for each evaluation :
- MultiDiscreteHyperParameter
- MultiUniformContinuousHyperParameter
- MultiNormalContinuousHyperParameter
These multi parameters have an additional argument sample_count which can be used to sample multiple times
per step.
Note: The values will be concatenated linearly, so each multi parameter will have a list of values
returned in the resultant OrderedDict. If you wish to flatten the entire search space, you can
use pyshac.flatten_parameters on this OrderedDict.
import pyshac
# Discrete parameters
dice_rolls = pyshac.DiscreteHyperParameter('dice', values=[1, 2, 3, 4, 5, 6])
coin_flip = pyshac.DiscreteHyperParameter('coin', values=[0, 1])
# Continuous Parameters
classifier_threshold = pyshac.UniformContinuousHyperParameter('threshold', min_value=0.0, max_value=1.0)
noise = pyshac.NormalContinuousHyperParameter('noise', mean=0.0, std=1.0)
Setup the engine
When setting up the SHAC engine, we need to define a few important parameters which will be used by the engine :
- Hyper Parameter list: A list of parameters that have been declared. This will constitute the search space.
- Total budget: The number of evaluations that will occur.
- Number of batches: The number of samples per batch of evaluation.
- Objective: String value which can be either
maxormin. Defines whether the objective should be maximised or minimised. - Maximum number of classifiers: As it suggests, decides the upper limit of how many classifiers can be trained. This is optional, and usually not required to specify.
import numpy as np
import pyshac
# define the parameters
param_x = pyshac.UniformContinuousHyperParameter('x', -5.0, 5.0)
param_y = pyshac.UniformContinuousHyperParameter('y', -2.0, 2.0)
parameters = [param_x, param_y]
# define the total budget as 100 evaluations
total_budget = 100 # 100 evaluations at maximum
# define the number of batches
num_batches = 10 # 10 samples per batch
# define the objective
objective = 'min' # minimize the squared loss
shac = pyshac.SHAC(parameters, total_budget, num_batches, objective)
Training the classifiers
To train a classifier, the user must define an Evaluation function. This is a user defined function, that accepts 2 or more inputs as defined by the engine, and returns a python floating point value.
The Evaluation Function receives at least 2 inputs :
- Worker ID: Integer id that can be left alone when executing only on CPU or used to determine the iteration number in the current epoch of evaluation.
- Parameter OrderedDict: An OrderedDict which contains the (name, value) pairs of the Parameters passed to the engine.
- Since it is an ordered dict, if only the values are required,
list(parameters.values())can be used to get the list of values in the same order as when the Parameters were declared to the engine. - These are the values of the sampled hyper parameters which have passed through the current cascade of models.
- Since it is an ordered dict, if only the values are required,
An example of a defined evaluation function :
# define the evaluation function
def squared_error_loss(id, parameters):
x = parameters['x']
y = parameters['y']
y_sample = 2 * x - y
# assume best values of x and y and 2 and 0 respectively
y_true = 4.
return np.square(y_sample - y_true)
A single call to shac.fit() will begin training the classifiers.
There are a few cases to consider:
- There can be cases where the search space is not large enough to train the maximum number of classifier (usually 18).
- There may be instances where we want to allow some relaxations of the constraint that the next batch must pass through all of the previous classifiers. This allows classifiers to train on the same search space repeatedly rather than divide the search space.
In these cases, we can utilize a few additional parameters to allow the training behaviour to better adapt to these circumstances. These parameters are :
- skip_cv_checks: As it suggests, if the number of samples per batch is too small, it is preferable to skip the cross validation check, as most classifiers will not pass them.
- early_stop: Determines whether training should halt as soon as an epoch of failed learning occurs. This is useful when evaluations are very costly.
- relax_checks: This will instead relax the constrain of having the sample pass through all classifiers to having the classifier past through most of the classifiers. In doing so, more samples can be obtained for the same search space.
# `early stopping` default is False, and it is preferred not to use it when using `relax checks`
shac.fit(squared_error_loss, skip_cv_checks=True, early_stop=False, relax_checks=True)
Sampling the best hyper parameters
Once the models have been trained by the engine, it is as simple as calling predict() to sample multiple samples or batches of parameters.
Samples can be obtained in a per instance or per batch (or even a combination) using the two parameters - num_samples and num_batches.
# sample a single instance of hyper parameters
parameter_samples = shac.predict() # Gets 1 sample.
# sample multiple instances of hyper parameters
parameter_samples = shac.predict(10) # Gets 10 samples.
# sample a batch of hyper parameters
parameter_samples = shac.predict(num_batches=5) # samples 5 batches, each containing 10 samples.
# sample multiple batches and a few additional instances of hyper parameters
parameter_samples = shac.predict(5, 5) # samples 5 batches (each containing 10 samples) and an additional 5 samples.
Examples
Examples based on the Branin and Hartmann6 problems can be found in the Examples folder.
An example of how to use the TensorflowSHAC engine is provided in the example foldes as well.
Comparison scripts of basic optimization, Branin and Hartmann6 using Tensorflow Eager 1.8 are provided in the respective folders.
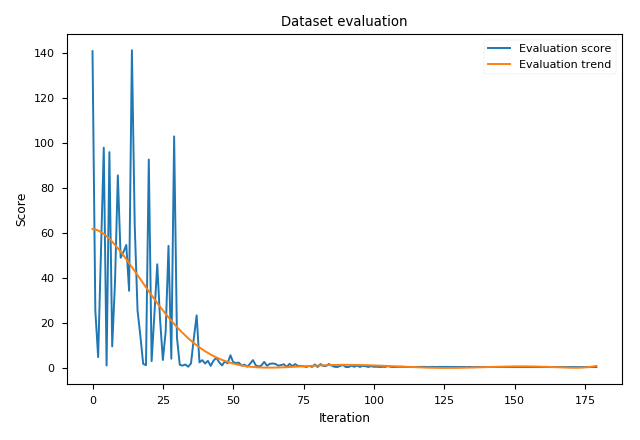
Evaluation of Branin
Brannin to close to the true optima as described in the paper.
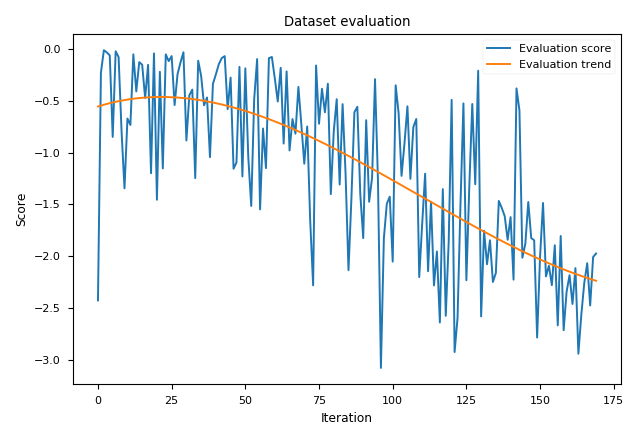
Evaluation of Hardmann 6
Hartmann 6 was a much harder dataset, and results are worse than Random Search 2x and the one from the paper. Perhaps it was due to a bad run, and may be fixed with larger budget for training.
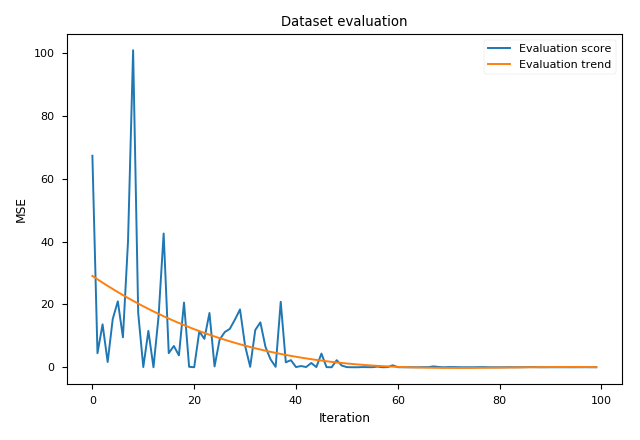
Evaluation of Simple Optimization Objective
The task is to sample two parameters x and y, such that z = 2 * x - y and we want z to approach the value of 4. We utilize MSE
as the metric between z and the optimal value.
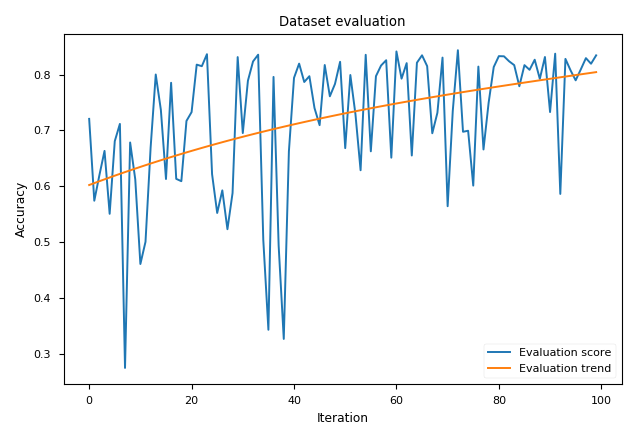
Evaluation of Hyper Parameter Optimization
The task is to sample hyper parameters which provide high accuracy values using TensorflowSHAC engine.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyshac-0.3.5.1-py2.py3-none-any.whl.
File metadata
- Download URL: pyshac-0.3.5.1-py2.py3-none-any.whl
- Upload date:
- Size: 43.2 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.3.2 requests/2.19.1 setuptools/39.1.0 requests-toolbelt/0.8.0 tqdm/4.28.1 CPython/3.5.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f47243e997292cd92f874b51270776d160d8ade296b2ebf34a8cbfde312afdf2
|
|
| MD5 |
27cc07aa3a1ce86a497bafd52ad71ab5
|
|
| BLAKE2b-256 |
e17b57e371d89d07cecd1961febcaf83396ac369156ebf8f674bab7f1d2fcbf5
|







