Automated Stereo Algorithm Evaluation

Project description
PyStereoAlgEval
Python Stereo Algorithm Evaluator - Das Python basierte Stereo-Algorithus-Evaluations Toolkit ist eine einfache Lösung zur automatisierten Evaluation von Stereo Algorithmen. Dabei kommt ein intelligentes Verfahren des Templatings von Konsolenaufrufen zum Einsatz. Die erzeugten Disparitätsbilder werden automatisch mittels mehrerer konfigurierbarer Qualitätsmetriken ausgewertet und die Resultate in eine praktische CSV-Datei geschrieben. PyStereoAlgEval ermöglicht auch die Visualisierung aller erhobenen Daten in verschiedenen Ausprägungen.
Vorraussetzungen
Benötigte Software
Die Vorraussetzung für das Verwenden der Bibliothek ist eine Python 3 Installation, wobei empfohlen wird, ein Anaconda oder VirtualEnv Environment zu verwenden.
Des Weiteren müssen neben der Python Installation folgende Pakete zusätzlich installiert sein.
Die Funktionsfähigkeit von PyStereoAlgEval ist mit den genannten Versionen verifiziert.
- Python: 3.6.6
- OpenCV: 3.4.2
- Matplotlib: 2.2.3
- NumPy: 1.15.3
- Pandas: 0.23.4
- SciPy: 1.1.0
- Scikit-Image: 0.14.1
Installation
Das Paket kann sich durch folgenden Befehl über die Python eigene Paketverwaltung pip installieren, der in der Regel in der Python Installation enthalten ist.
pip install pystereoalgeval
Falls ein Anaconda oder VirtualEnv Environment aufgesetzt worden ist, sollte dieses vor Ausführen des Befehls aktiviert werden.
Datensatz
Ein Beispiel-Datensatz, der verwendet werden kann ist der Datensatz der Version von 2006 von Middlebury Stereo Vision.
Zum Durchführen des automatisierten Auswerteverfahrens wird ein geeigneter Datensatz benötigt, der bestimmte Vorraussetzungen erfüllen muss. Die Ordnerstruktur des Datensatzes muss folgendermaßen aufgebaut sein:
. # Oberverzeichnis zu definieren in "dataset_dir"
├── ...
├── TestSet1 # Ordner des Testdatensatzes
│ ├── imgl.png # Linkes Stereo-Bild
│ ├── imgr.png # Rechtes Stereo-Bild
│ └── ground_truth.png # Disparitätsbild der Grundwahrheit
├── TestSet2 # Nächster Testbildsatz
│ ├── imgl.png
│ ├── imgr.png
│ └── ground_truth.png
├── ...
Zu beachten ist, dass die einzelnen Bilderpaare mit Grundwahrheit sich in einem eigenen Ordner befinden.
Der konkrete Dateiname der Testbilder lässt sich in der später beschriebenen Konfigurationsdatei anpassen.
Es ist, um eine Auswertung des erzeugten Disparitätsbildes zu ermöglichen, darauf zu achten, dass die Abmessungen der drei Bilder für jeden Ordner einheitlich sind.
Die Intensitätswerte des Bildes mit der Grundwahrheit, entsprechen im Zahlenwert den Disparitäten zwischen den Stereobildern.
Sollte eine Reskalierung der Testbilder stattgefunden haben, können zur Auswertung die Intensitätswerte der Grundwahrheit mit einem Faktor versehen werden.
Dieser Faktor kann in der Konfigurationsdatei angepasst werden.
Wichtig:
Invalide Disparitätswerte oder Bildpunkte, für die keine Grundwahrheit existiert, sind mit dem Wert 0 zu belegen.
Es können alle 8-Bit Bilder verwendet, werden deren Format von OpenCV gelesen werden kann (u. A. .png, .jpg, .tiff; siehe Doku). Wobei verlustbehaftete Bildformate, wie z.B. JPEG, möglichst nicht verwendet werden sollten. Des Weiteren sollte darauf geachtet werden, dass die verwendeten Testdaten kein größeres Disparitätsintervall als 255 Bildpunkte erfordern. Grund dafür ist, dass eine Unterstützung von berechneten Disparitätsbildern mit einer größeren Bittiefe als 8, derzeit nicht verfügbar ist.
Verwendbare Stereo Algorithmen
Es lassen sich alle Stereo Algorithmen verwenden, die von der Kommandozeile gestartet werden können.
Grundvorraussetzung für den Kommandozeilenaufruf ist die Möglichkeit, dass die Berechnungsparameter durch den Konsolenbefehl an den Algorithmus übergeben werden können.
Die Verwendung eines Bash-Skripts kann hierfür ggf. eine Hilfestellung sein.
In der aktuellen Version des Programms muss der Pfad des Ausgangsbildes statisch sein. Eine variable Bestimmung des Pfades pro Testbildpaar ist in zukünfigten Versionen geplant.
Erste Schritte
Wenn alle beschrieben Vorraussetzungen erfüllt wurden, kann die Auswertung beginnen.
Zuerst muss die Klasse AlgorithmEvaluator aus der Bibliothek PyStereoAlgEval in der Python Umgebung importiert werden.
Das ist entweder in der Python Konsole oder einem Skript möglich.
Nach dem Import sollte ein Objekt erstellt werden, mit dem ab sofort gearbeitet werden kann.
from pystereoalgeval import AlgorithmEvaluator
a = AlgorithmEvaluator()
Es besteht hier die Möglichkeit, bei der Initialisierung direkt einige Parameter zu definieren. z.B. kann direkt der Pfad zur selbst erstellten Konfigurationsdatei übergeben werden.
a = AlgorithmEvaluator(config_path='/path/to/config.ini')
Alternativ kann diese auch später erneut eingelesen werden, was die bestehende Konfiguration des Objektes überschreibt.
a.read_config('/path/to/config.ini')
Bei einer vollständig erzeugten Konfigurationsdatei, kann nun ein Testdurchlauf gestartet werden.
Zuvor muss jedoch zwingend ein vollständiges und valides Template definiert werden.
Für genauere Informationen siehe Template.
Für das Beispiel, dass bei einer konstanten maximalen Disparität, die Auswirkungen unterschiedlicher Fenstergrößen untersucht werden sollen, können die Einstellungen folgendermaßen definiert sein:
a.set_constant(name="disparity_range", value=64)
a.set_iterator(name="window_size", steps=[7,9,11])
a.set_execution_template("$imgL$ $imgR$ $out$ $window_size$ $method$$disparity_range$")
a.update_config()
a.run()
Mit dem Befehl set_constant(name=const_name, value=const_value) lässt sich eine Konstante definieren, deren Wert in den gleichnamigen Tag innerhalb des Templates eingesetzt wird.
Eine Definition mittels dieser Funktion ist nicht zwingend notwendig, da sich die Konstante direkt in das Template schreiben lässt.
Jedoch wird auf diese Weise in der resultierenden CSV-Datei eine Spalte für den Wert angelegt, was im Nachinein zur weiteren Verwendung sinnvoll ein kann.
Der Befehl set_iterator(name=iter_name, steps=inter_steps) definiert eine Laufvariable, für die der Algorithmus jeweils pro Testbildsatz ausgeführt wird.
Wie auch bei den Konstanten wird für die sog. Iteratoren eine eigene Spalte in der CSV-Datei angelegt.
Es besteht die Möglichkeit, mehrere Iteratoren zu definieren, in dem der gleiche Befehl mit unterschiedlichem name-Parameter erneut aufgerufen wird.
Das Programm erstellt dann alle möglichen Permutationen der Iteratorenwerte und führt den Algorithmus somit für alle möglichen Kombinationen aus.
Mit dem Befehl update_config() wird die, durch getätigte Befehle womöglich geänderte Konfiguration, in die INI-Datei geschrieben.
Für den Anfang kann dieses Python Skript als Target-Algorithmus verwendet werden. Es beinhlatet eine simple NCC- und SAD-Implementierung, sowie einen Wrapper für die OpenCV-interne Semi-Global Block Matching Funktion.
Mit run() wird der Programmablauf gestartet und die Ergebnisse in die Datei "results.csv" in den in der Konfiguration definierten Pfad results_dir geschrieben.
Sollte ein anderer Dateiname gewünscht sein, so lässt sich dieser durch den Aufruf von run("filename.csv") bestimmen.
Nach Beendigung des Programms lässt sich direkt in Python Plots auf Basis der Ergebnisse erstellen.
Eine genaue Beschreibung der Plotting Funktion findet in Abschnitt Plotting statt.
Jedoch könnte so eine Auswertung für das obige Beispiel ablaufen:
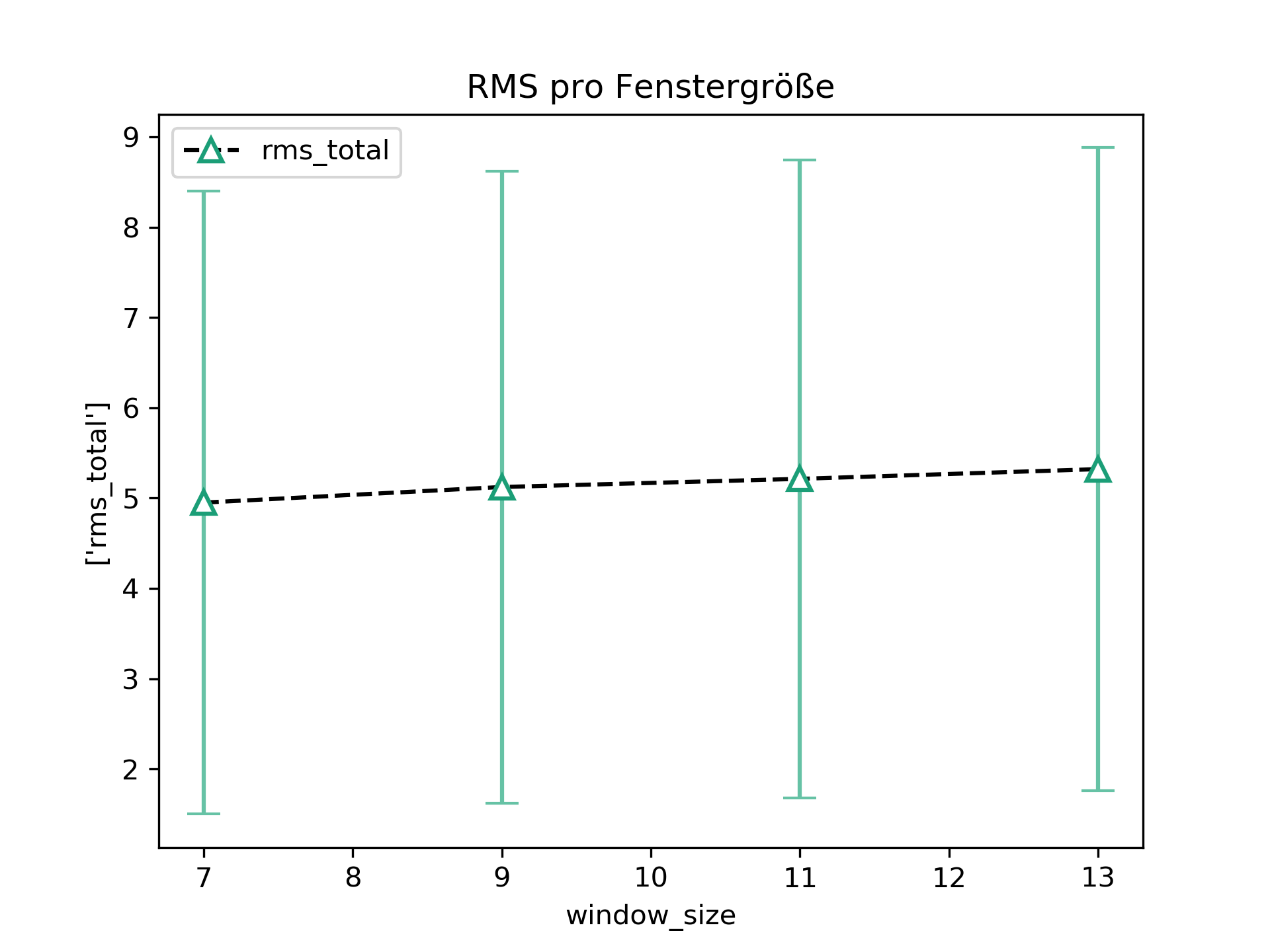
a.plot(y_category="rms_total", x_category="window_size", title="RMS pro Fenstergröße", results_name="filname.csv")
Es wird ein Plot erstellt, auf deren y-Achse der Mittelwert des rooted mean square error der Resultate über den Datensatz gezeigt wird.
Gruppiert sind die Werte pro Fenstergröße entlang der x-Achse.
Es ist zu beachten, dass results_name standardmäßig, bei Weglassen des Parameters, auf die Datei "results.csv" im Pfad results_dir zugreift.
Der erzeugte Plot sieht somit wie folgt aus:
Link
Konfiguration
Zur Verwendung der Bibliothek und zur Vereinfachung von Arbeitsabläufen wird eine Konfigurationsdatei benötigt. Diese muss vor dem Start eingelesen werden. Eine Beispielhafte config.ini Datei befindet sich im Repository.
Die Konfigurationsdatei besteht aus fünf Teilen. Im Nachfolgenden wird jeder Teil und jeder Schlüssel einzeln erläutert
[BASE]
dataset_dir = /Users/USER/Desktop/Dataset
results_dir = /Users/USER/Desktop
imgl_name = imgl.png
imgr_name = imgr.png
gt_name = ground_truth.png
output_disp_filepath = /Users/USER/Desktop/Dataset/output.png
template = $imgL$ $imgR$ $out$ $window_size$ $disparity_range$ $method$
dataset_dirbestimmt das Verzeichnis in dem sich alle Ordner mit den einzelnen Testbildpaaren befinden. Siehe dazu (Datensatz)results_dirbestimmt das Verzeichnis, in dem die CSV-Datei angelegt wird, in die alle Resultate der Evaluation und Plots des berechneten Disparitätsbildes geschrieben werden.imgl_name,imgr_nameundgt_namebestimmen die Namen, die das jeweils rechte, linke Bild sowie das Bild der Grundwahrheit der Testdaten im Ordner haben.output_disp_filepathbezeichnet den Dateipfad, unter dem das berechnete Disparitätsbild abgelegt wird. (Aktuell konstant, in zukünftigen Versionen variabel definierbar)templatedefiniert das erstellte Template.
[PREPROCESSING]
enable = True
filter = median
params = {'mode': 'reflect'}
enableaktiviert Vorverarbeitung durch Filter oder Feature-Detektorfilterder name einer beliebigen Filterfunction von skimage.filter oder skimage.feature. Es ist zu beachten, dass eventuell nicht alle aufgeführten Filterfunktionen zur Vorverarbeitung tauglich sind.paramsDictionary der zu übergebenen Parameter an die Filterfunktion. Der Parametername muss immer in Anführungszeichen geschrieben sein. Beispiel:"{"para1": 23.4", "para2": 'test'}"
[EXECUTION]
mode = python
target = /Users/USER/software/stereo.py
error_handling = interrupt
modebeschreibt, wie der intargetdefinierte Algorithmus ausgeführt werden soll.mode = pythonwird benötigt, wenn es sich bei dem Target um ein Python-Skript handelt. Dazu wird als Executable das aktuelle Python Environment benutzt, da Python-Skripte selbst nicht ausführbar sind. Ist der Algorithmus selbst eine aufrufbare Programminstanz, solltemode = genericgesetzt sein.targetist der aufzurufende Algorithmus selbst. Kann ein ausführbares Programm sein oder ein Python-Skript. Beachte dazu auchmode.error_handlingBeierror_handling = interruptwird der Ablauf gestoppt, sollte der Algorithmus einen Fehler zurückgeben. Beierror_handling = ignorewird jeglicher Fehler innerhalb des Algorithmus ignoriert und zur nächsten Kombination aus Bilddaten und Iteratoren gesprungen.
[ITERATORS]
window_size = 7,9,11,13
[CONSTANTS]
disparity_range = 112
method = NCC
Iteratoren und Konstanten können auch in der Konfigurationsdatei definiert werden. Dazu sind die Schritte der Iteratoren mit "," zu trennen. Mögliche Datentypen sind Ganze Zahlen, Kommazahlen (mit "." als Trennzeichen) und Text.
[EVALUATION]
gt_coefficient = 0.5
textureless_width = 5
textureless_threshold = 60.0
discont_width = 14
discont_threshold = 15.0
gt_coefficientbeschreibt einen Faktor, mit dem die Werte des Bildes der Grundwahrheit zur Auswertung multipliziert wird. Ist bei einer Reskalierung der Testdaten erforderlich.textureless_widthbeschreibt das Fenster über das, mit den Sobel-Operator erstelle Texturbild, der Mittelwert gebildet wird.textureless_thresholdist der Schwellenwert, unter welchem ein Bereich als texturarm gewertet wird.discont_widthAnzahl an Dilatationen die auf die Punkte an Disparitätsübergänge angewendet werden.discont_thresholdSchwellenwert für die Differenz von benachbarten Disparitätswerten der Grundwahrheit, ab wann ein Bildbereich als Disparitätsdiskontinuität gewertet wird. Die Ausweitung des Bereiches erfolgt mittelsdiscont_width.
Template
Die mit $ markierten Tags werden während des Programmablaufs durch gesetzte Konstanten und die Laufvariablen der Iteratoren ersetzt.
Des Weiteren können unterschiedliche programm-intere Tags verwendet werden:
$imgL$,$imgR$Der absolute Pfad des linken/rechten Bildes des aktuellen Testbildpaares.$out$Konstanter absoluter Pfad, der nach dem Ablauf des Algorithmus zur Evaluation mit der Grundwahrheit verwendet wird. In Konfigurationsdatei definierbar.$base_dir$Konstanter Pfad des Oberverzeichnisses des Datensatzes. In Konfigurationsdatei definierbar.$curr_dataset_dir$Aktueller absoluter Pfad des verwendeten Testbildpaares.
Es ist zu beachten, dass der Pfad des Algorithmus und im Fall eines Python-Skripts, auch die Python Executable, nicht im Template enthalten ist und automatisch davor gesetzt wird.
Beispiel: Wird oben genannte aufgeführte Beispielkonfiguration verwendet, ergibt sich folgender erster Aufruf des Algorithmus:
Template:
$imgL$ $imgR$ $out$ $window_size$ $disparity_range$
Ergebnis:
Executable -> python /Users/USER/software/stereo.py
$imgL$ -> /Users/USER/Desktop/Dataset/TestSet1/imgl.png
$imgR$ -> /Users/USER/Desktop/Dataset/TestSet1/imgr.png
$out$ -> /Users/USER/Desktop/Dataset/output.png
$window_size$ -> 7
$disparity_range$ -> 112
Vollständiger Konsolenaufruf:
python /Users/USER/software/stereo.py /Users/USER/Desktop/Dataset TestSet1/imgl.png /Users/USER/Desktop/Dataset/TestSet1/imgr.png
/Users/USER/Desktop/Dataset/output.png 7 112
Die Bildung des Aufrufs wird wiederholt für alle Testbildpaare in Verbindung mit allen Kombinationen aus den gesetzten Iteratoren.
Es ist zu beachten, dass wenn nach dem Parsen des Templates noch $-Symbole übrig sind, es zu einem Fehler kommt.
Eine weitere Vorraussetzung ist, dass alle gesetzten Iteratoren im Template vorkommen.
Es ist hingegen nicht erforderlich, dass die anderen oben genannten Tags beinhaltet sind (ausgenommen $out$).
Hinweis: Zur Nutzung der verwendeten Stereo-Algorithmus-Sammlung "stereo.py" muss diese datei aus dem Repository heruntergeladen werden. Diese ist in der Installation über pip nicht enthalten.
Evaluataion
Auf das berechnete Disparitätsbild wird eine Vielzahl von Qualitätsmetriken angewendet.
Die Metriken müssen nicht vorher ausgewählt werden, sondern werden stete berechnet.
Verglichen werden bei der Bestimmung der Werte immer das berechnte Disparitätsbild mit der Grundwahrheit.
Zu beachten ist, dass nur valide Bildpunkte ausgewertet werden, die in beiden Bildern (berechnetes Disparitätsbild und Grundwahrheit) ungleich 0 sind. Pixel für die kein Disparitätswert existiert, sollten vom Algorithmus den Zahlenwert 0 zugewiesen bekommen.
Bei reskalierten Testdaten müssen die Intensitätswerte der Grundwahrheit mit einem Korrekturfaktor gleich dem Skalierungsfaktor versehen werden. Der Faktor kann wie in Konfiguration beschrieben, im Abschnitt [EVALUATION] im Schlüssel gt_coefficient definiert werden.
CSV-Resultate
In der resultierenden CSV-Datei finden sich folgende Spalten wieder:
(der Platzhalter *region* wird in Segmentierung erklärt)
indexIndexdatasetNames des Testbildpaares (Ordnername)- Konstanten (eigene Spalte pro Konstante)
- Iteratoren (eigene Spalte pro Iterator)
heightundwidthHöhe und Breite des Testbildespsnr_*region*Peak signal to noise ratio (PSNR)rms_*region*Rooted mean square error (Quadratwurzel aus MSE)err_*region*_*threshold*Anteil an validen Bildpunkten, die um über den in*threshold*Angegeben prozentwert an der maximalen Intensität (255) von der Grundwahrheit abweichen.dens_imgVerhältnis von validen Bildpunkten zu Gesamtzahl der Bildpunkte des berechneten Disparitätsbildesdens_gtVerhältnis von validen Bildpunkten zu Gesamtzahl der Bildpunkte der Grundwahrheitdens_relVerhältnis vondens_imgzudens_gtdens_*region*
Segmentierung
Zum besseren Vergleich der Leistung der Algorithmen, in zur Evaluierung meist relevanten Bildregionen, lassen sich die Ergebnisse von einigen Metriken in bestimmten Bildregionen einzeln bestimmen. Dazu lässt sich das Bild nach zwei lokalen Bildmerkmalen segmentieren:
Textur
Es ist sinnvoll, die Resultate eines Algorithmus, anders in Bildbereichen mit geringer Textur, zu bewerten als in Bereichen mit viel Textur.
Es lässt sich vom Program mithilfe des Sobel Operators der Texturgehalt einer Bildregion bestimmen.
In der Konfigurationsdatei lassen sich im Abschnitt EVALUATION Einstellungen zu dem gewünschten Schwellenwert zur Segmentierung des Bildes treffen.
Der durch die Einstellungen definierte Bereich mit geringer Textur lässt sich mithilfe der Funktion show_region() anzeigen.
a.show_region("textureless")
Der nicht markierte Bereich ist somit der Bereich mit hoher Textur.
Es ist zu beachten, dass bevor der Befehl aufgerufen wird, die Konfigurationsdatei geladen sein muss.
Standardmäßig wird das erste Testbildpaar des Datensatzes zur Anzeige benutzt.
Durch Verwendung des zusätzlichen Parameters image_of_dataset kann der Ordnername eines anderen Testbildpaares angegeben werden.
Nach Aufruf des Fensters kann es zu Problemen kommen, die verhindern, dass sich das Fenster wieder schließt.
In diesem Fall schließt der Befehl daw() die Anzeige.
a.daw()
Disparitätsdiskontinuitäten
Ein weiteres wichtiges Kriterium der Bildsegmentierung ist der Bereich von Disparitätsdiskontinuitäten. Zur Auswertung kann es relevant sein, Bereiche in denen sich die Disparität eines Bildes sprunghaft ändert, anders zu beurteilen als Bereiche mit kontinuierlichen Disparitäten.
Daher wird analog zur Textur das Bild nach diesem Kriterum segmentiert.
Die Parameter der Segmentierung lassen sich in der Konfiguration festlegen.
Der ausgewählte Bereich lässt sich durch folgenden Befehl anzeigen:
a.showregion("discontinued")
Platzhalter
Aus der Segmentierung ergeben sich demnach folgenden Möglichkeiten den Platzhalter in den Spalten der CSV zu ersetzen:
lowtextureBereiche mit wenig TexturhightextureBereich mit hoher Textur (invertierte Auswahl vonlowtexture)discBereiche mit starken DisparitätssprüngennondiscBereiche mit geringen oder keinen Disparitätssprüngen (invertierte Auswahl vondisc)totalKeine Segmentierung
Plotting
Zur Visualisierung der Resultate steht ein intelligentes Werkzeug zur Verfügung.
Es ermöglicht die Gruppierung von Daten anhand einer Kategorie und die Darstellung von mehreren Mittelwerten unterschiedlicher Evaluationsparamter.
Zusätzlich lässt sich der Datensatz nach mehreren Kategorien filtern.
Der Plot wird dabei im results_dir Verzeichnis als PNG-Datei gespeichert.
Zur Erstellung eines Plots müssen mindestens zwei Festlegungen getroffen werden.
- Welche Datenkategorien (Spalten der CSV-Datei) im Mittelwert sollen angezeigt werden?
- Nach welcher Datenkategorie soll gruppiert werden?
- (optional) Soll nach einer/mehreren weiteren Kategorie/-en gefiltert werden?
Der konkrete Aufruf der Plotting-Funktion ist folgender:
a.plot(y_category="rms_total", x_category="window_size")
Der Parameter y_category definiert die Mittelwerte der Daten pro Kategorie, die entlang der y-Achse angezeigt werden. Es ist möglich mehrere innerhalb einer Liste anzugeben (nur für Style "default").
Der Parameter x_category definiert die Datenkategorie, nach der die Werte gruppiert werden sollen.
Es können dabei alle Spalten der CSV-Datei verwendet werden.
Filter
Es können zur weiteren Eingrenzung der Daten Filter verwendet werden. Dazu muss an den Parameter filters ein Dictionary übergeben werden, mit folgendem Aufbau:
filter = {category1: value1, category2: value2}
Styles
Es stehen zwei verschiedene Style-Optionen zur Verfügung, nach denen der Plot erstellt werden kann.
Definiert werden können die Styles mit dem Parameter style mit den Werten default oder whisker. Bei Weglassen des Parameters wird ein Plot im Default-Style erstellt.
Default
Die Erste ist "Default", die einen einfach Linienplot mit Fehlerbalken erstellt. In diesem Modus ist es möglich mehrere x-Kategorien anzugeben.
Beispiel: Link
Box-Whisker
Die zweite Möglichkeit ist die Anzeige eines Box-Whisker Plots, der weitere Informationen zur Verteilung der Werte um den Mittelwert enthält. Es ist zu beachten, dass in diesem Modus nur eine x-Kategorie ausgewählt werden kann.
Beispiel: Link
Weitere Parameter
results_nameNeben den genannten Parametern kann die CSV-Datei als Datenquelle ausgewählt werden, sollte sie vom Namenresults.csvabweichen. Die Datei muss sich jedoch immer in dem in der Konfiguration definiertenresults_dirVerzeichnis befinden.uniqueDurch einen übergebenenTrueWert an den Parameter, wird dem Dateinamen, der standardmäßig dem Dateinamen der CSV-Datei entspricht, ein Zeitstempel angehägt. Dieser Parameter ist standardmäßgFalse.relative_baseDiesem Parameter kann ein Wert aus der gewähltenx_categoryübergeben werden. Danach ist auf dem Plot der Mittelwert der relativen Änderungen der y-Werte zu dem gewählten Wert gezeigt. Die relativen Werte werden für jeden Datensatz einzeln berechnet und danach gemittelt.axis_labelDamit lassen sich eigene Achsen-Bezeichnungen einstellen, die die automatisch erzeugten überschreiben. Siehe Alle Funktionendisable_errorDie geplotteten Fehlerbalken können mit diesem Parameter deaktiviert werden.
Alle Funktionen
set_logging_level(level)zum setzen des Logging-Levels. Level standardmäßig aufINFOlevel (str):Python Logging Level (s. Doku). Möglichkeiten:DEBUG,INFO,WARNING,ERROR,CRITICAL
set_mode(mode)zum Setzen des Execution Modusmode (str): Execution Modus. Möglichkeiten:'python','generic'
set_target(target) (str)zum Setzen des Pfades zum Algorithmustarget (str): Pfad zum Algorithmus
set_error_handling(error_handling)zum Setzen des Verhaltens bei einem Fehler im Algorithmuserror_handling (str): Error Handling Modus. Möglichkeiten:'ignore','interrupt'
get_iterators()gibt alle definierten Iteratoren zurückreturn=dict: gibt Dictionary mit Iteratoren zurück.
get_constants()gibt alle definierten Konstanten zurückreturn=dict: gibt Dictionary mit Konstanten zurück.
set_iterators(name, steps, remove)zum setzen eines Iterators.name (str): Name des Iteratorssteps (list of int/str/float): Schritte der Laufvariableremove=False (bool): ob Iterator entfernt werden soll. Steps dürfen nicht angegeben werden.
set_constants(name, value)zum Setzen einer Konstanten.name (str): bestimmt Namen des Iteratorssteps (int/str/float): Wertremove=False (bool): ob Konstante entfernt werden soll. Value darf nicht angegeben werden. Standardmäßig aufFalse
set_evaluation_parameter(paramter, value)Definiert Parameter zur Auswertung, wie Segmentierung oder Koeffizient für Grundwahrheitparameter (str): Name des Parameters (siehe Konfiguration). Möglichkeiten:'gt_coefficient','textureless_threshold','discont_threshold','textureless_width','discont_width'value: Wert. Thresholds und der Koeffizient sind alsfloatund die Width Parameter alsintanzugeben
set_execution_template(template)zum Setzen des Templatestempalte (str): Template
check_execution_templateMethode zum Überprüfen des Templates, ob alle notwendigen Tags enthalten sindreturn=bool: ob Template funktionsfähig ist
set_preprocessing(filter_name, parms)Methode zum Aktivieren und Definieren der optionalen Vorverarbeitung der Bilddaten.filter_name (str)Name der Filterfunktion aus skimage.filter oder skimage.feature.params (dict)Optionale Parameter für die Filterfunktion im dict format. Beispiel:dict(param1=1.5, para2="test")
remove_preprocessing()Methode zum Löschen aller Einstellungen zur Vorverarbeitungdaw()schließt alle Fenstershow_region(mode, images_of_dataset)Funktion zum Anzeigen von aktueller Einstellung zur Segmentierungmode (str): angezeigte Segemtierung. Möglichkeiten:'textureless','discontinued'image_of_dataset=None (str): Ordnername des angezeigten Bildes. Standardmäßg wird erstes Bild des Datensatz-Verzeichnisses angezeigt.
get_dataset()Gibt geparstes Dictionary des Datensatz-Verzeichnisses wiederreturn=dict: Datensatz als Dictionary aufgelöst
run(results_name)führt Evaluations-Ablauf ausresults_name="results.csv" (str): Dateiname der resultierenden CSV-Datei
plot(y_category, x_category, filters, title, style, unique, results_name)Funktion zur Erstellung von Plotsy_category (list of int/str/floar)/(int/str/float): in y-Richtung dargestelle Wertex_category (int/str/float): Kategorie, nach der in x-Richtung gruppiert wirdfilters (dict): Filter im Format{cat1: value1, cat2: value2}title="Plot" (str): Titelstyle="default" (str): Style des Plots. Möglichkeiten:'default','whisker'unique=False (bool): ob Dateinamen ein Zeitstempel angehängt werden sollrelative_base (int,str,float): Basiswert aus derx_categoryvon dem aus die relavite Aggregation durchgeführt werden sollaxis_label(tuple len=2 of str): Eigene Achsen-Bezeichner.axis_label:= ("x-Achse", "y-Achse").disable_error=FalseDeaktiviert bei Bedarf die Fehlerbalken.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pystereoalgeval-0.2.3.tar.gz.
File metadata
- Download URL: pystereoalgeval-0.2.3.tar.gz
- Upload date:
- Size: 42.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.5.0.1 requests/2.12.4 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.31.0 CPython/3.6.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
edddadbfa09891d7a6924f378c45146c0320e524995bc36e04c62c37d6de53f6
|
|
| MD5 |
68f2f8a41b334d642b81571dfae302f7
|
|
| BLAKE2b-256 |
565d30f9149affffccd4a9c176421bb5be29ba5de58e082660ced6eb782ceb9c
|
File details
Details for the file pystereoalgeval-0.2.3-py3-none-any.whl.
File metadata
- Download URL: pystereoalgeval-0.2.3-py3-none-any.whl
- Upload date:
- Size: 38.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.5.0.1 requests/2.12.4 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.31.0 CPython/3.6.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
34469caa07f27aadbb9aade86020a051bcd10b834feddec7d67cff167abcdb15
|
|
| MD5 |
e0d7584f8d1357aaaf1731c102bd73ad
|
|
| BLAKE2b-256 |
726139c7752bf50a2dbde706cffe622b92ca44e6bd9dcdf5c56c40ea4dd5c457
|








{kind=link}
{kind=link}