Team Formation Library with Tensorflow Machine Learning

Project description
Team Formation Python Library
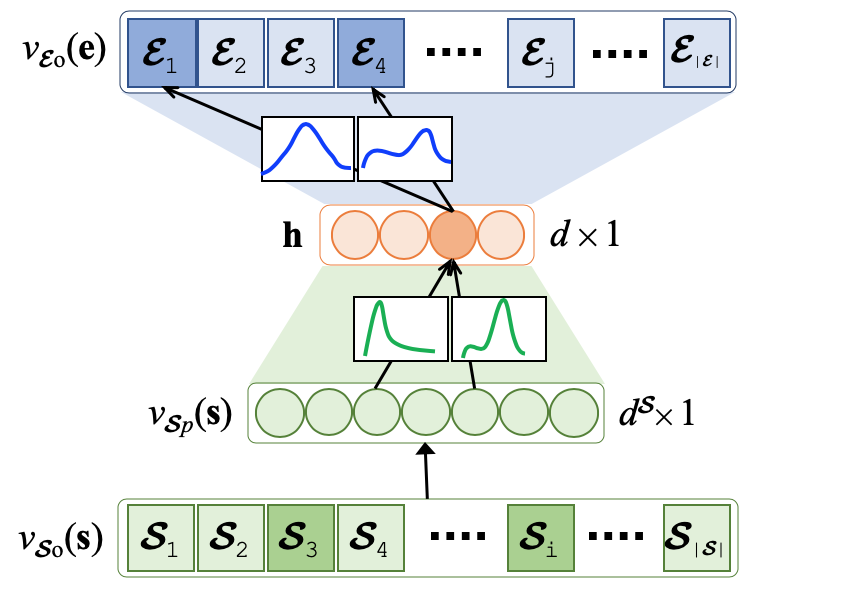
The Team Formation PyPI Tensorflow Python Library focuses on the composition of teams of experts that collectively cover a set of required skills based on their historical collaboration network and expertise. Prior works are primarily based on the shortest path between experts on the expert collaboration network,and suffer from three major shortcomings: (1) they are computationally expensive due to the complexity of finding paths on large network structures; (2) they use a small portion of the entire historical collaboration network to reduce the search space; hence, may form sub-optimal teams; (3) they fall short in sparse networks where the majority of the experts have only participated in a few teams in the past. Instead of forming a large network of experts, we propose to learn relationships among experts and skills through a variational Bayes neural architecture wherein:
- we consider all past team compositions as training instances to predict future teams;
- we bring scalability for large networks of experts due to the neural architecture;
- we address sparsity by incorporating uncertainty on the neural network’s parameters which yields a richer representation and more accurate team composition.
The PyPI python library implements the above-mentioned functionality by pipe-lining its architecture into stages that use classes and functions to maintain a fluid data flow. The pipeline consists of 5 stages that are as follows: (1) team formation layer instantiation; (2) dictionaries/embeddings generation; (3) train/test dataset split; (4) VAE learning; and, (5) performance evaluation. We empirically demonstrate how our proposed model outperforms the state-of-the-art approaches in terms of effectiveness and efficiency based on a large DBLP dataset.
Getting Started
These instructions will get you the Team Formation PyPI library installed on your machine and you will be able to use its features in a python compiler.
Prerequisites
These are the python libraries you need to pre-install before using this package.
Python 3.6 (or higher)
Tensorflow 1.15.0 (GPU preferred)
Keras 2.0.0
gensim
NLTK 3.5
scikit-learn
sklearn
Dataset
We choose DBLP as the benchmark. However, you can use your own database in similar fashion to perform team formation.
Preprocessing
Before starting the project you would need to preprocess your dataset to create the author-skill and team-skill mappings.
Output files
Output directory stores following data inside:
- Model snapshots
- Predictions
- Evaluation results
At the end of running session of each model, user will be asked wether if he/she wants to save the model or not. In case of approval model weights and configs will be saved in output folder. They will be accesible for next use. Also, after running a model, predictions for the test set will be saved into the output folder for the futhur comparison. You can find final evaluation results for each model in ".csv" individualy. They will be stored in folder.
Evaluation
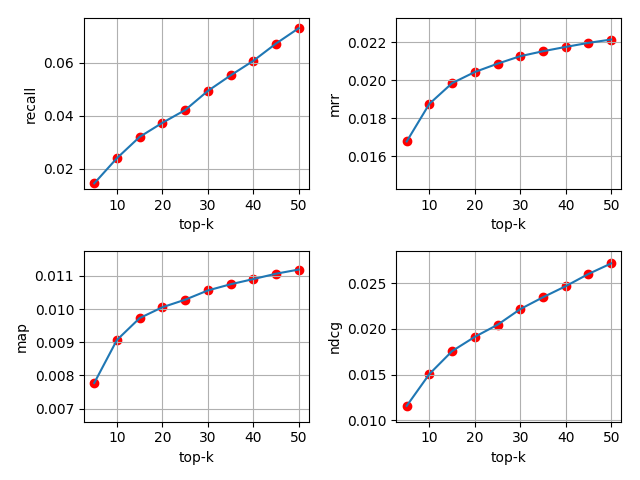
Evaluation of predicted files is done using the following metrics:
- Recall @k
- NDCG @k
- MAP @k
- MRR @k
The following diagram is a performance evaluation on the DBLP dataset.
End-to-end library dataflow
The following data flow can be tested and run using the script in example.py
# Create an instance of the TeamFormationSession
TFL = TeamFormationSession(database_name, database_path, embeddings_save_path)
# 1 - Generate dictionaries and embedding files
TFL.generate_embeddings()
# 2 - Create vectors to associate ids, teams, and skills
TFL.generate_t2v_dataset()
# 3 - Split the dataset into train and test sets
TFL.train_test_split_data()
# 4 - Pass the data through the VAE
TFL.run_VAE()
# 5 - Evaluate the results and compute correlation with another model
TFL.evaluate_results("output/predictions/S_VAE_O_output.csv", "output/predictions/correlation_baseline_output.csv", 50,
True)
Contributing
This branch is submitted as a public library package on the PyPI API.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pytfl-1.0.1.tar.gz.
File metadata
- Download URL: pytfl-1.0.1.tar.gz
- Upload date:
- Size: 24.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.5.0 pkginfo/1.5.0.1 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.47.0 CPython/3.8.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7fc8c6c60ab953c5f118403554472c1ad5c88d875e7b6ae4d7ea0adf8aa69f50
|
|
| MD5 |
1c8a0e6ab6bfa9cd2df0b2e2398b8af4
|
|
| BLAKE2b-256 |
1046759094be93b474947a874fc38b43e202f99110c7512acf7e799cf34b46db
|
File details
Details for the file pytfl-1.0.1-py3-none-any.whl.
File metadata
- Download URL: pytfl-1.0.1-py3-none-any.whl
- Upload date:
- Size: 24.9 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.5.0 pkginfo/1.5.0.1 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.47.0 CPython/3.8.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7ba4279f9747f57434d5c23f5c02ae6abab82e1d7a9c07437c176a0ccff43796
|
|
| MD5 |
668868d270b59362cccc3dd767e16465
|
|
| BLAKE2b-256 |
776fef7a2cbe3d5b0011f4894f365530176173390c6ac96e1713e5fc89eda92d
|







