A PyTorch Extension for Learning Rate Warmup

Project description
A PyTorch Extension for Learning Rate Warmup
This library contains PyTorch implementations of the warmup schedules described in On the adequacy of untuned warmup for adaptive optimization.




Installation
Make sure you have Python 3.7+ and PyTorch 1.1+ or 2.x. Then, run the following command in the project directory:
python -m pip install .
or install the latest version from the Python Package Index:
pip install -U pytorch_warmup
Examples
- CIFAR10 - A sample script to train a ResNet model on the CIFAR10 dataset using an optimization algorithm with a warmup schedule. Its README presents ResNet20 results obtained using each of AdamW, NAdamW, AMSGradW, and AdaMax together with each of various warmup schedules. In addition, there is a ResNet performance comparison (up to ResNet110) obtained using the SGD algorithm with a linear warmup schedule.
- EMNIST - A sample script to train a CNN model on the EMNIST dataset using the AdamW algorithm with a warmup schedule. Its README presents a result obtained using the AdamW algorithm with each of the untuned linear and exponential warmup, and the RAdam warmup.
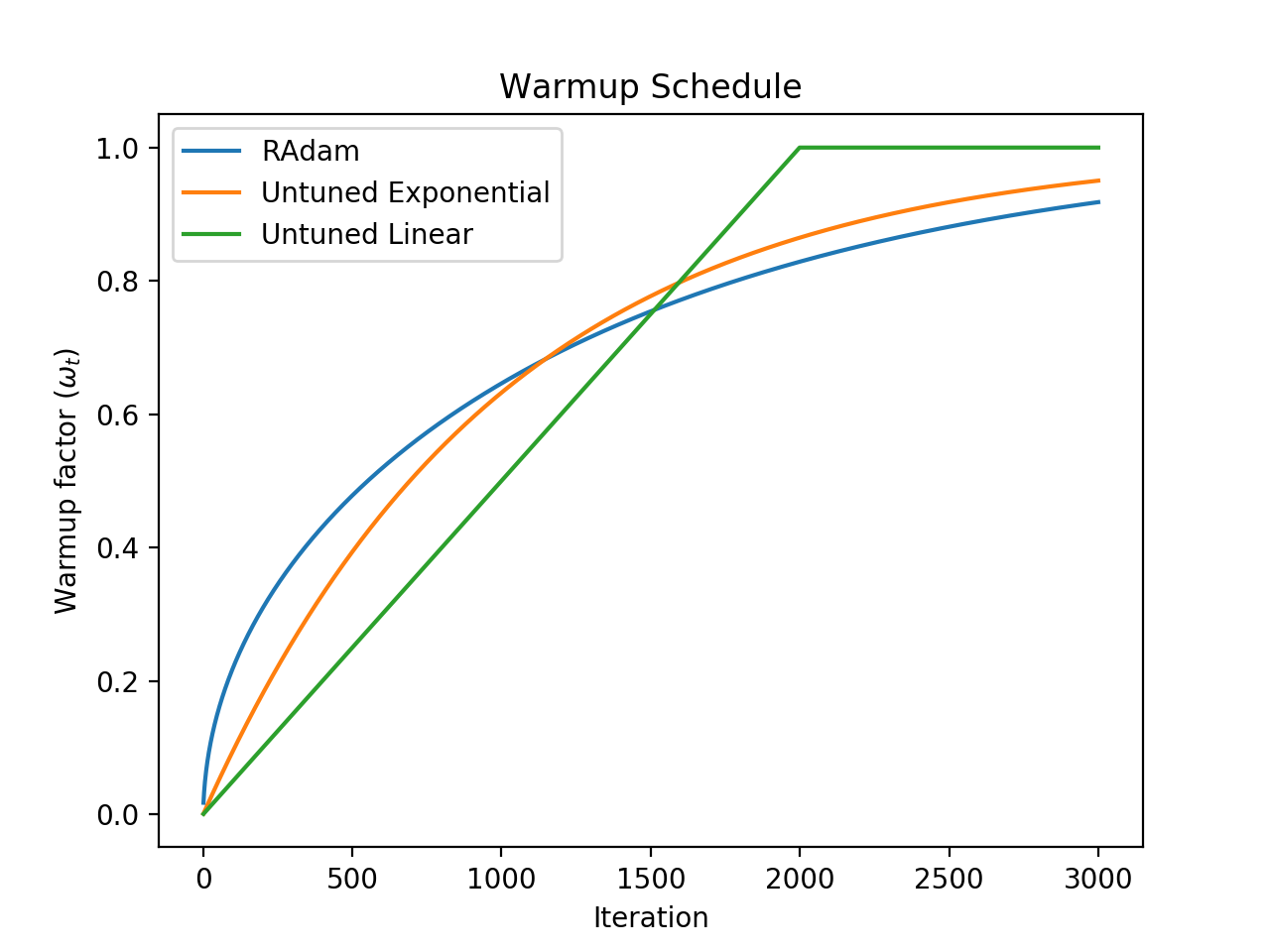
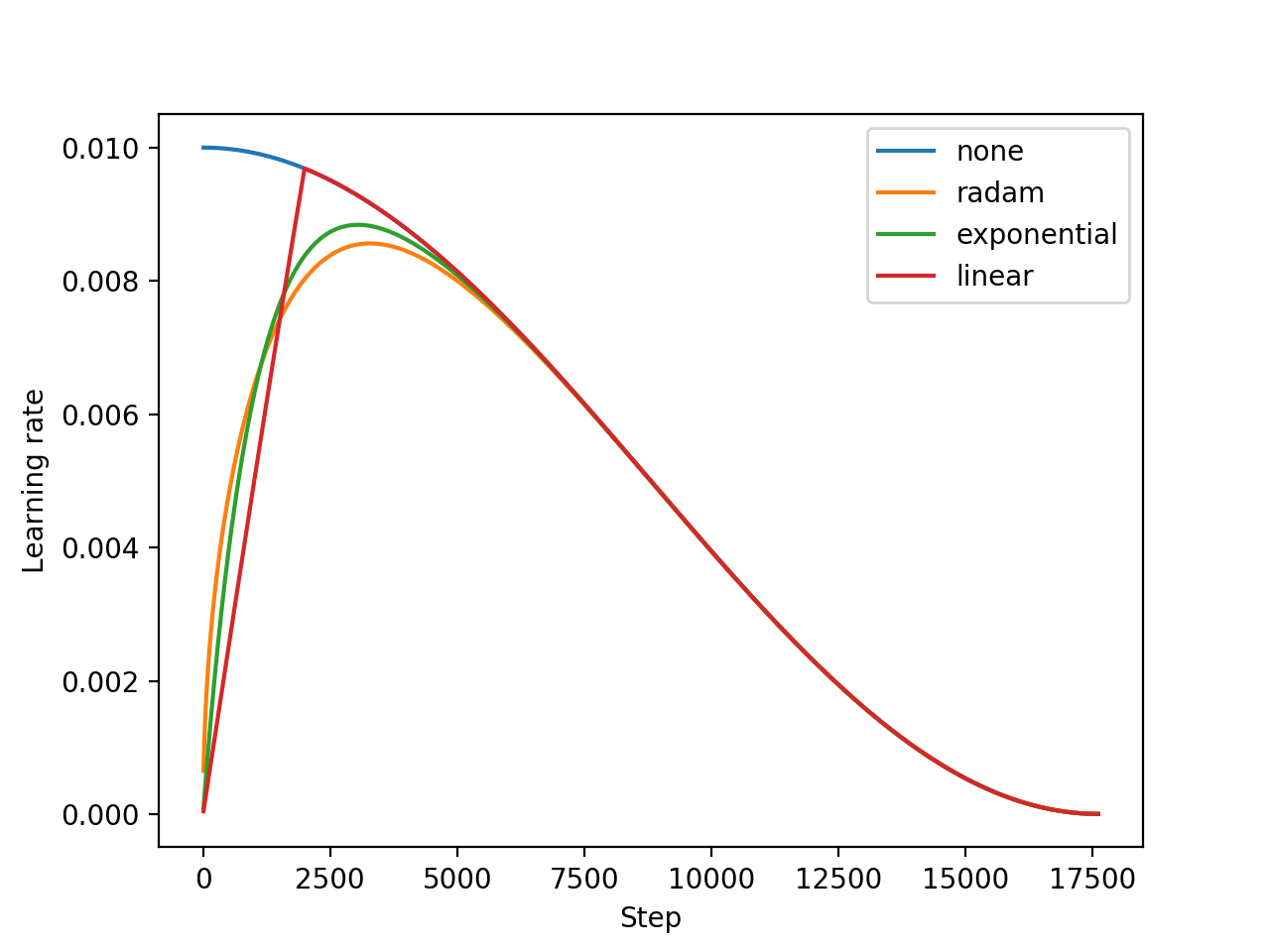
- Plots - A script to plot effective warmup periods as a function of β₂, and warmup schedules over time.
Usage
The documentation provides more detailed information on this library, unseen below.
Sample Codes
The scheduled learning rate is dampened by the multiplication of the warmup factor:
Approach 1

When the learning rate schedule uses the global iteration number, the untuned linear warmup can be used
together with Adam or its variant (AdamW, NAdam, etc.) as follows:
import torch
import pytorch_warmup as warmup
optimizer = torch.optim.AdamW(params, lr=0.001, betas=(0.9, 0.999), weight_decay=0.01)
# This sample code uses the AdamW optimizer.
num_steps = len(dataloader) * num_epochs
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_steps)
# The LR schedule initialization resets the initial LR of the optimizer.
warmup_scheduler = warmup.UntunedLinearWarmup(optimizer)
# The warmup schedule initialization dampens the initial LR of the optimizer.
for epoch in range(1,num_epochs+1):
for batch in dataloader:
optimizer.zero_grad()
loss = ...
loss.backward()
optimizer.step()
with warmup_scheduler.dampening():
lr_scheduler.step()
[!Warning] Note that the warmup schedule must not be initialized before the initialization of the learning rate schedule.
If you want to use the learning rate schedule chaining, which is supported for PyTorch 1.4 or above, you may simply write a code of learning rate schedulers as a suite of the with statement:
lr_scheduler1 = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
lr_scheduler2 = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
warmup_scheduler = warmup.UntunedLinearWarmup(optimizer)
for epoch in range(1,num_epochs+1):
for batch in dataloader:
...
optimizer.step()
with warmup_scheduler.dampening():
lr_scheduler1.step()
lr_scheduler2.step()
If you want to start the learning rate schedule after the end of the linear warmup, delay it by the warmup period:
warmup_period = 2000
num_steps = len(dataloader) * num_epochs - warmup_period
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_steps)
warmup_scheduler = warmup.LinearWarmup(optimizer, warmup_period)
for epoch in range(1,num_epochs+1):
for batch in dataloader:
...
optimizer.step()
with warmup_scheduler.dampening():
if warmup_scheduler.last_step + 1 >= warmup_period:
lr_scheduler.step()
Approach 2
When the learning rate schedule uses the epoch number, the warmup schedule can be used as follows:
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[num_epochs//3], gamma=0.1)
warmup_scheduler = warmup.UntunedLinearWarmup(optimizer)
for epoch in range(1,num_epochs+1):
for i, batch in enumerate(dataloader):
optimizer.zero_grad()
loss = ...
loss.backward()
optimizer.step()
if i < len(dataloader)-1:
with warmup_scheduler.dampening():
pass
with warmup_scheduler.dampening():
lr_scheduler.step()
This code can be rewritten more compactly:
for epoch in range(1,num_epochs+1):
for i, batch in enumerate(dataloader):
optimizer.zero_grad()
loss = ...
loss.backward()
optimizer.step()
with warmup_scheduler.dampening():
if i + 1 == len(dataloader):
lr_scheduler.step()
Approach 3
When you use CosineAnnealingWarmRestarts, the warmup schedule can be used as follows:
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2)
warmup_period = 2000
warmup_scheduler = warmup.LinearWarmup(optimizer, warmup_period)
iters = len(dataloader)
warmup_epochs = ... # for example, (warmup_period + iters - 1) // iters
for epoch in range(epochs+warmup_epochs):
for i, batch in enumerate(dataloader):
optimizer.zero_grad()
loss = ...
loss.backward()
optimizer.step()
with warmup_scheduler.dampening():
if epoch >= warmup_epochs:
lr_scheduler.step(epoch-warmup_epochs + i / iters)
Warmup Schedules
Manual Warmup
In LinearWarmup and ExponentialWarmup, the warmup factor w(t) depends on the warmup period that must manually be specified.
Linear
w(t) = min(1, t / warmup_period)
warmup_scheduler = warmup.LinearWarmup(optimizer, warmup_period=2000)
For details please refer to LinearWarmup in the documentation.
Exponential
w(t) = 1 - exp(-t / warmup_period)
warmup_scheduler = warmup.ExponentialWarmup(optimizer, warmup_period=1000)
For details please refer to ExponentialWarmup in the documentation.
Untuned Warmup
In UntunedLinearWarmup and UntunedExponentialWarmup, the warmup period is determined by a function of Adam's beta2 parameter.
Linear
warmup_period = 2 / (1 - beta2)
warmup_scheduler = warmup.UntunedLinearWarmup(optimizer)
For details please refer to UntunedLinearWarmup in the documentation.
Exponential
warmup_period = 1 / (1 - beta2)
warmup_scheduler = warmup.UntunedExponentialWarmup(optimizer)
For details please refer to UntunedExponentialWarmup in the documentation.
RAdam Warmup
In RAdamWarmup, the warmup factor w(t) is a complicated function depending on Adam's beta2 parameter.
warmup_scheduler = warmup.RAdamWarmup(optimizer)
For details please refer to RAdamWarmup in the documentation, or "On the Variance of the Adaptive Learning Rate and Beyond."
Apex's Adam
The Apex library provides an Adam optimizer tuned for CUDA devices, FusedAdam. The FusedAdam optimizer can be used together with any one of the warmup schedules above. For example:
optimizer = apex.optimizers.FusedAdam(params, lr=0.001, betas=(0.9, 0.999), weight_decay=0.01)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_steps)
warmup_scheduler = warmup.UntunedLinearWarmup(optimizer)
License
MIT License
© 2019-2024 Takenori Yamamoto


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pytorch_warmup-0.2.0.tar.gz.
File metadata
- Download URL: pytorch_warmup-0.2.0.tar.gz
- Upload date:
- Size: 1.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
da01fef6a75a0db3502f5566957ec3d28fc6d754bf5cceba3165815411a7278f
|
|
| MD5 |
71bb0f6681c7f40c1641c6b224633be8
|
|
| BLAKE2b-256 |
912afc985e8b8f2938815b0789ea28914640cb4b4bdb138d374053f45ca4fe6d
|
File details
Details for the file pytorch_warmup-0.2.0-py3-none-any.whl.
File metadata
- Download URL: pytorch_warmup-0.2.0-py3-none-any.whl
- Upload date:
- Size: 11.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
11d852a3f22a19026223c2b98250e9998c9e030adf6eb4afa0e6580d3e16aee5
|
|
| MD5 |
c4c666483441fe720bcab6366f21cd37
|
|
| BLAKE2b-256 |
9dc30986937e1c1bbe41790c807740bfcab3101d7d32d4707600e3bc37f3af5b
|







