Universal Game Translator from on-screen text in Python

Project description
pyugt - Python Universal Game Translator



pyugt is a universal game translator coded in Python: it takes screenshots from a region you select on your screen, uses OCR (via Tesseract v5) to extract the characters, then feeds them to a machine translator (multiple backends are included) to then show you a translated text.
Since it works directly on images, there is no need to hack the game or anything to access the text. It is also cross-platform (support for Windows and Linux and experimentally on MacOSX).
Here is a demo:
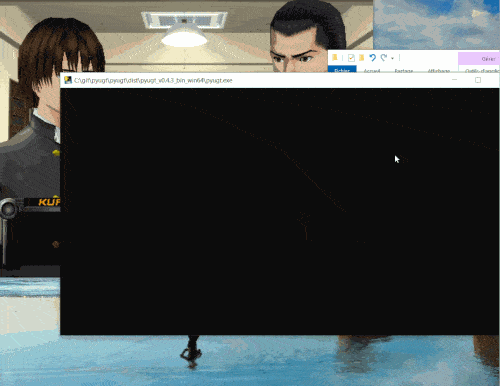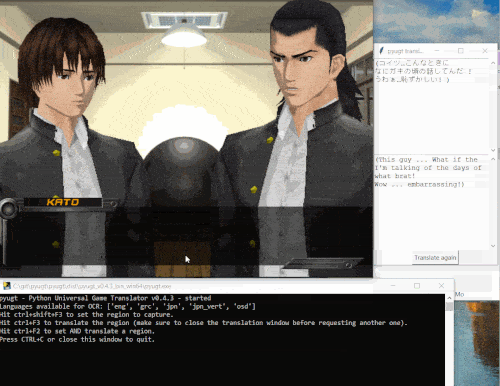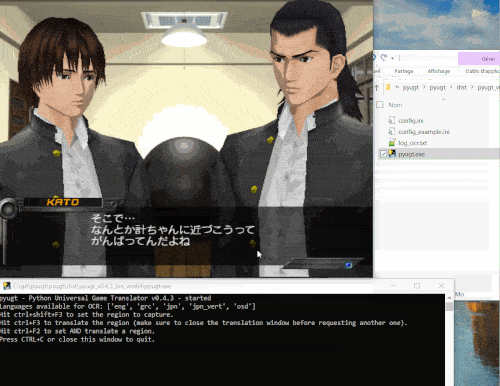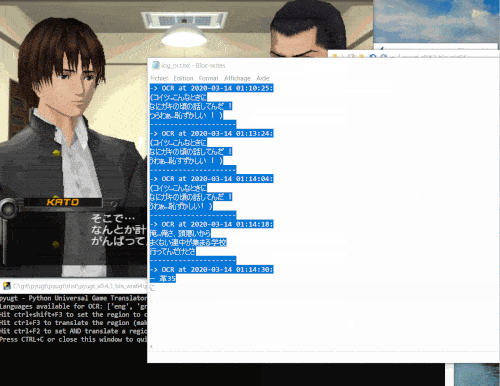
Several machine translation backends are available: from free online APIs such as Google Translate, to DeepL with a free or paid subscription, and also an offline translator that runs directly on your computer without needing internet access thanks to Argos Translate and OpenNMT.
Of course, since the translation is done by a machine, don't expect a very nice translation, but for games where no translation is available, it can be sufficient to understand the gist and be able to play.
The software can also be useful to human translators, as it is possible to enable logging of OCR'ed text in the config file, so that all captured text will be saved in a log file that can later be used as the source for a manual translation.
The software is also not limited to games, but can be applied to anything that displays text on screen.
This software was inspired by the amazing work of Seth Robinson on UGT (Universal Game Translator).
How to install & update
-
First, install Tesseract v5, installers are provided by UB Mannheim. Make sure to install the additional languages you want to translate from (eg, Japanese, there is support for both horizontal and vertical Kanji).
-
Then install pyugt:
-
Either on Windows OSes, there is a prepackaged binary you can download here (look for pyugt_vx.x.x_bin_win64.zip for 64-bit or win32 for 32-bit).
-
Either for other platform or if you want to run from sourcecode, you need to install a Python interpreter. Anaconda is a good one, and Miniconda3 is a smaller alternative that works too.
Then, install this software:
pip install --upgrade pyugtOr for developers who want to run it locally, after downloading the archive from Github, unzip it anywhere, cd in the folder and type:
python setup.py developNote the software was tested on Windows 10 x64 with Python 3.10 (Anaconda) and 3.11. It was tested on Linux by other users but is not regularly tested.
-
Language packs for the Tesseract are downloadable directly from the installer. Language packs for the offline machine translator Argos are downloaded on-the-fly when required by the user, but can also be downloaded beforehand from this index, which also provides IPFS links that are future-proof, in case the on-the-fly downloads fail.
How to use
-
First, you need to configure the config file
config.ini. A sample config file is provided with the software that should work fine on Windows, but on other platforms or in some cases you may need to edit it, particularly to setup the path to the Tesseract binaries. The config file also allows you to change the hotkeys and the monitor to screenshot from, and a few other things such as the source and target languages (by default, the source is japanese and target is english). -
Then, you can launch the script from a terminal/console:
pyugt
or:
python -m pyugt
-
Then, use the hotkey to select a region to capture from (default hotkey:
CTRL+SHIFT+F3). The selected region does not need to be very precise, but need to contain the text to translate. -
Finally, use the hotkey to translate what is shown in the region (default:
CTRL+F3). This will display a window with the original text and the translated text. Repeat as many times as you need, you don't need to reselect the region to translate again. -
Tip: if the software has difficulties in recognizing the characters (you get gibberish and non-letters characters instead of words), first try to redefine the region with CTRL+F2 and make sure the region includes all text with some margin but not too much of the background (the tighter around the text, the less the OCR will be confused by the background, this can help a lot!). You can use the region selection and translation hotkey to do both in a streamlined fashion (default:
CTRL+F2). -
Tip2: Try to make the game screen bigger. The bigger the characters, the easier for the OCR to work.
-
Tip3: You can specify the path to a config file by using the
-cor--configargument:pyugt -c <path_to_config_file> -
Tip4: In the translation box, it's possible to manually edit the OCR'ed text and force a new translation by clicking on the "Translate again" button. This can be useful when the OCR has wrongly detected non-letters characters.
-
Tip5: If you use blue light filtering softwares, disable them all before using the OCR, it will improve the contrast and hence the accuracy.
IMPORTANT NOTE: The software is still in alpha stage (and may forever stay in this state). It IS working, but sometimes the hotkeys glitch and they do not work anymore. If this happens, simply focus the Python console and hit CTRL+C to force quit the app, then launch it again. The selected region is saved in the config file, so you don't have to redo this step everytime.
Options
Here is a sample configuration file, with comments for the various additional options (such as logs for the OCR'ed text and translated text):
[USER]
# User parameters to configure the pyUGT program.
# Note that parameters can be modified on-the-fly while the app is running, and changes will be reflected in realtime. For example, translators can be changed on-the-fly.
# Path to Tesseract v5 binary. Easily install it from UB Mannheim installers: https://github.com/UB-Mannheim/tesseract/wiki
path_tesseract_bin = C:\Program Files\Tesseract-OCR\tesseract.exe
# Source language to translate from, for OCR. Both the Optical Recognition Character and the translator will search specifically for strings in this language, this reduces the amount of false positives (eg, translating strings in other languages that are more prominent or bigger on-screen). Language code can be found inside Tesseract tessdata folder (depends on what languages you chose in the installer).
lang_source_ocr = jpn
# Source language to translate from.
lang_source_trans = ja
# Target language to translate to. Must be a language code for the target machine translator: either Google Translate language code (NOT a Tesseract code! See: https://readthedocs.org/projects/py-googletrans/downloads/pdf/latest/ ) or DeepL code (eg, en for Google Translator, Argos and most others, or EN-US for DeepL).
lang_target = en
# Machine translator library to use. Can be online_free to use free online APIs but which can be throttled (eg, Google Translate, DeepL free, Baidu, etc) ; deepl to use DeepL API with your own authkey (not throttled but limited number of translations in free plan, then need to pay for more, but it's best in class japanese->english machine translator) ; offline_argos for offline translation using Argos based on OpenNMT, which produces less accurate translations but is free, unlimited and does not require an internet connection.
translator_lib = online_free
# If online_free is the selected translator_lib, we can specify here the translator service to use. For a list of available services, see: https://github.com/UlionTse/translators#more-about-translators
translator_lib_online_free_service = google
# If translator_lib is set to deepl, the API authorization key must be set here
translator_lib_deepl_authkey = fa14ef6c-d...
# Hotkey to set the region on screen to capture future screenshots from. The region does not need to be precise, but must contain the region where text is likely to be found.
hotkey_set_region_capture = ctrl+shift+F3
# Hotkey to translate from the selected region
hotkey_translate_region_capture = ctrl+F3
# Hotkey to set a region AND translate it directly on mouse click release. This is useful for games where the contrast between the text and background is bad (eg, transparent dialog box), so reselecting a tight region for each dialogue may yield better results, this is a faster way to do that with one shortcut instead of 2.
hotkey_set_and_translate_region_capture = ctrl+F2
# Hotkey to preview in a window the postprocessed screenshot that is fed to OCR, this helps with tweaking parameters here and see how it improve the text contrast
hotkey_show_ocr_preview = ctrl+p
# On which monitor the screen region capture should display? If you have only one screen, leave this to 0 (first monitor)
monitor = 0
# Save all OCR'ed text into a log file? Set a path or file name different than None to activate (exemple: log_ocr = log_ocr.txt). This can be very useful for human translators to gather game text data.
log_ocr = None
# Save all translated text into a log file? Set a path or file name different than None to activate (exemple: log_translation = log_trans.txt).
log_translation = None
# Only capture text by OCR without translating (set this value to True, else to also translate set to False). This is useful if you only want to use pyugt as a OCR tool, or don't want to send your OCR'ed text to Google.
ocr_only = False
# Remove line returns automatically, so that we consider all sentences to be one (this can help the translator make more sense because it will have more context to work with).
remove_line_returns = True
# Preprocess screenshots to improve OCR?
preprocessing = True
# Preprocessing filters to apply (set to None to disable, else input a list of strings with strings being methods of PILLOW.ImageFilter). Example: ['SMOOTH', 'SHARPEN', 'UnsharpMask']
preprocessing_filters = ['SHARPEN']
# Preprocessing binarization of image? Set to None to disable, else set a value between 0-255 (255 being white)
preprocessing_binarize_threshold = 180
# Preprocessing invert image (if text is white, it's better to invert to get black text, Tesseract OCR will be more accurate). Set to False to disable.
preprocessing_invert = True
# Show debug information
debug = False
Shortcomings & advantages
Compared to UGT, the translated text is not overlaid over a screenshot of the original text. This could maybe be done as Tesseract provides some functions (image_to_boxes() or image_to_osd() or image_to_data()). PRs are very welcome if anyone would like to give it a try!
UGT can also directly select and translate the active window. We dropped this feature because it's platform dependent, so a region selection seemed like the most reliable and cross-platform way to implement screen capture, even if it adds one additional step.
On the other hand, there are several advantages to our approach:
-
it's cross-platform (Windows & Linux currently, MacOSX should also supported experimentally but global hotkeys may sometimes fail because the
keyboardmodule only has experimental support for this platform), -
we use Tesseract so that OCR is done locally (instead of via the Google Cloud Vision API) so we only send text which is a lot smaller footprint and thus less expensive (generally free), and a big advantage is that it's possible to freely resize the game window to a bigger size, with bigger characters improving the OCR recognition, and also no downscaling/quality reduction is necessary since there is no image transfer,
-
Regions can be selected, so that unnecessary screen objects that may confuse the OCR can be elimited with a carefully selected region (update: UGT now also implements this feature :tada:),
-
We enforce the source and target languages, so that both the OCR and translator know what to expect, instead of trying to autodetect, which may fail particularly when there are names that may be written in another language or character form (eg, not in Kanji).
Similar projects
-
Universal Game Translator (Windows, opensource) - the inspiration for this project.
-
pyUGT fork by ByJacob (Windows, Linux, MacOS, opensource) - fork of this project but implementing the Marian Machine Translation offline translator instead of Argos-Translate. MMT is sometimes more accurate than Argos-Translate, but is slower and more space consuming. Both offline translators however remain less accurate than DeepL online translator.
-
Capture2Text (Windows, opensource) - OCR on-screen text, but no translation.
-
OwlOCR (MacOSX, freeware) - Similar to Capture2Text, OCR on-screen text, no translation.
-
Sugoi Japanese Translator combined with (Visual Novel OCR)[https://visual-novel-ocr.sourceforge.io/] by the same author: provides similar features to pyUGT but is closed-source, so that it cannot be improved upon. Also, it is unclear which OCR backend is used.
-
Translator++, a free but closed source app to translate non emulated games with access to the text, can leverage automatic machine translation.
License
This software is made by Stephen Larroque and is published under the MIT Public License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyugt-1.0.10.tar.gz.
File metadata
- Download URL: pyugt-1.0.10.tar.gz
- Upload date:
- Size: 27.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
616deb51314d9e044df416bf166090845af19d2c820967fae72cc6f1e4fa4894
|
|
| MD5 |
6de7a72369dc784f724d2b89b2fdb003
|
|
| BLAKE2b-256 |
ff997005314605cf5c5bc512031c9901ef9900df294f2d8ef969c5983274dfe2
|
File details
Details for the file pyugt-1.0.10-py3-none-any.whl.
File metadata
- Download URL: pyugt-1.0.10-py3-none-any.whl
- Upload date:
- Size: 22.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
45998cc8521c79979b4a242587729f1f3699bbcd840b0beede53fdc7bf35bf80
|
|
| MD5 |
626f91d9448caeca738ef7ed5eba925f
|
|
| BLAKE2b-256 |
b74229c21cd544204f3ac66dfd928871c12f3254b9ad6a15cc6bdf07259dadf6
|







