A fast web crawler to satisfy all your needs

Project description
Python Web Crawler 
A web crawler written in Python to crawl a given website.
Features!
- Faster
- Ablility to specify the number of threads to use to crawl the given website
- Ability to use proxies to bypass IP restrictions
- Clear summary of all the urls that were crawled. View the crawled.txt file to see the complete list of all the links crawled
- Ability to specify delay between each HTTP Request
- Stop and resume crawler whenever you need
- Gather all the urls with their titles to a csv, incase if you are planning to create a search engine
- Search for specific text throughout the website
- Clear statistics about how many links ended up as Files,Timeout Errors,Connecrion Errors
- Crawl until you need. You can specify upto what level the crawler should crawl.
- Random browser user agents will be used while crawling.
Upcoming Features!
- Gather AWS Buckets,Emails,Phone Numbers etc
- Download all images
Dependencies
This tool uses a number of open source projects to work properly:
- BeautifulSoup - Parser to parse the HTML response of each request made.
- Requests - To make GET requests to the URLs.
Usage
If you like to see the list of supported features, simply run
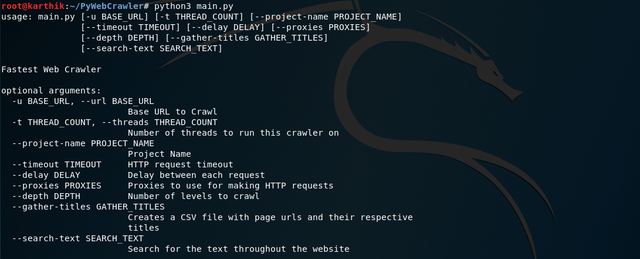
Specifying only to crawl for 3 levels
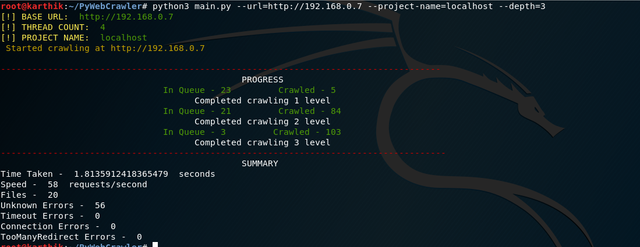
Search for specific text throughout the website
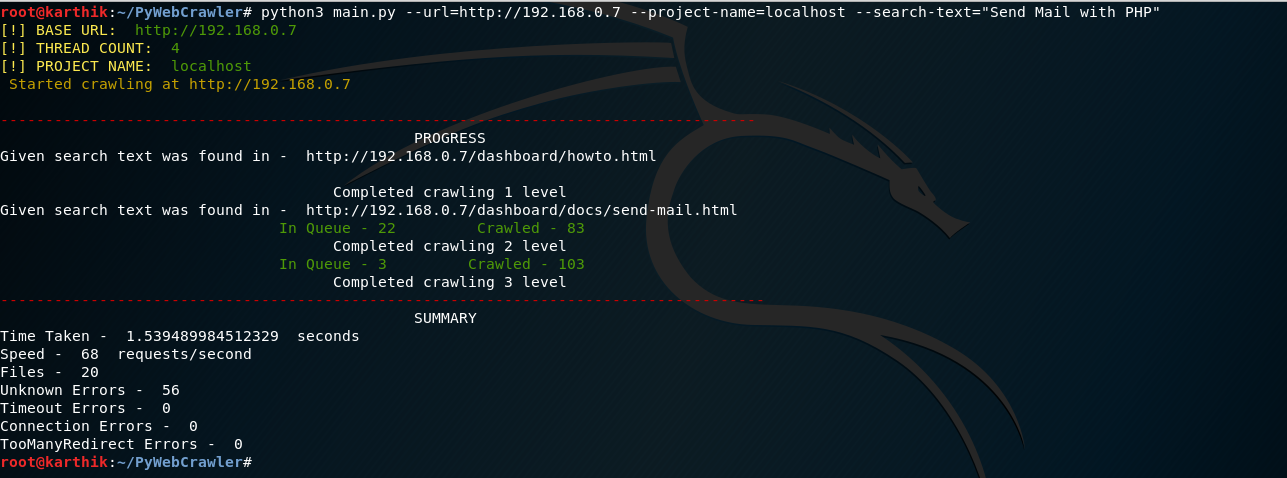
Gather all the links along with their titles to a CSV file. A CSV file with the links and their titles will be created after the crawl completes
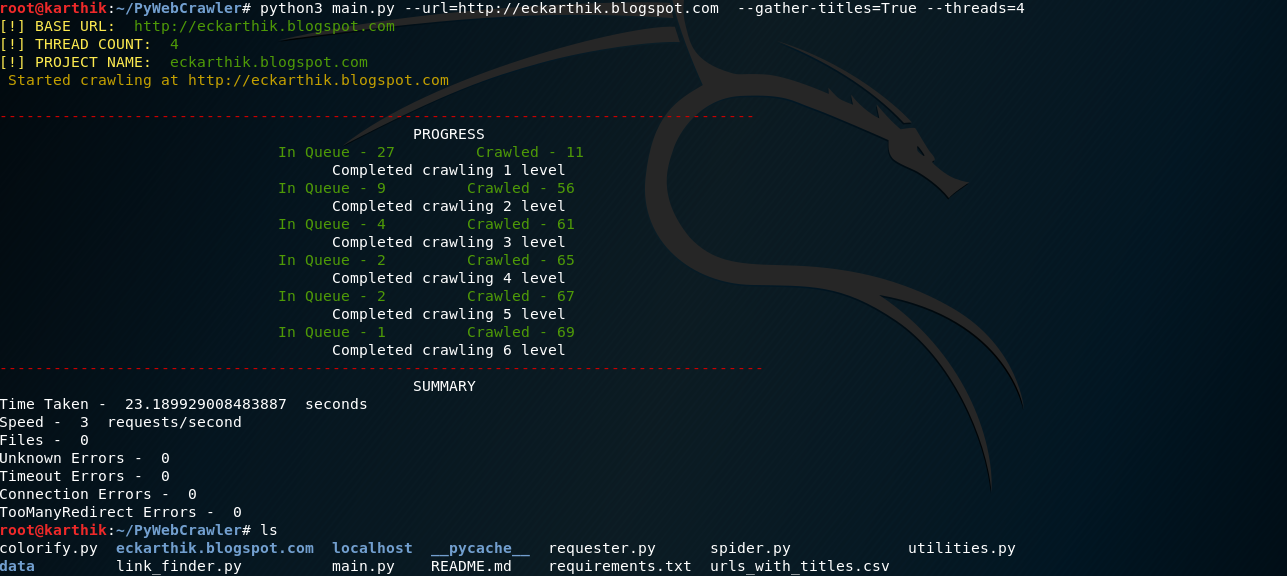
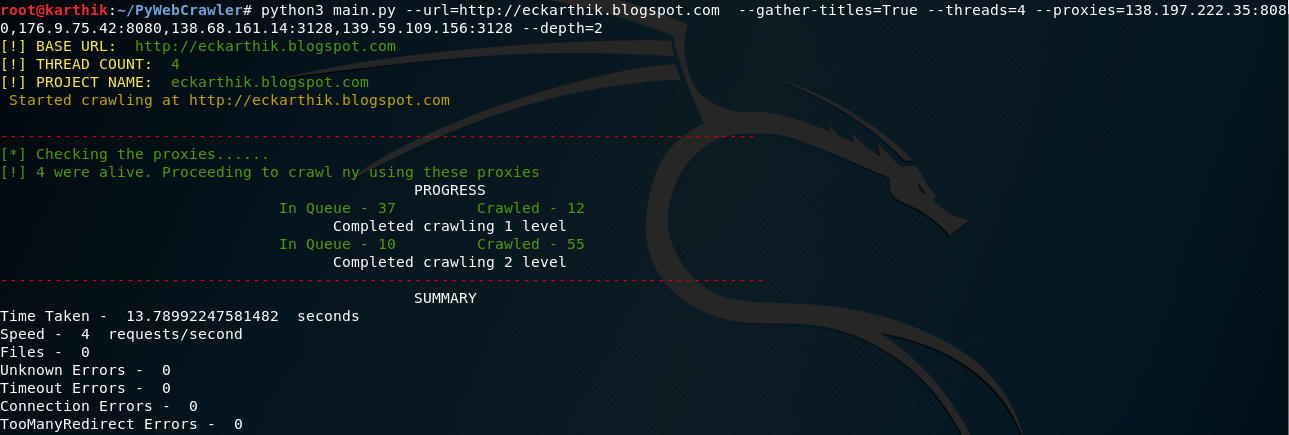
Use proxies to crawl the site.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
pywebcrawler-0.0.1.tar.gz
(8.2 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pywebcrawler-0.0.1.tar.gz.
File metadata
- Download URL: pywebcrawler-0.0.1.tar.gz
- Upload date:
- Size: 8.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.0.0 requests-toolbelt/0.9.1 tqdm/4.41.1 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8746bb0d60b12be062757375718a4fd96d58619f1edcaddc8c5ac4ee67223e01
|
|
| MD5 |
9c1fb2f4442a859811673d719f1a276c
|
|
| BLAKE2b-256 |
7810a5debfdd4e9c6949fca4233e152fb3d5dbe9a52eb6c3918978c6919517d1
|
File details
Details for the file pywebcrawler-0.0.1-py3-none-any.whl.
File metadata
- Download URL: pywebcrawler-0.0.1-py3-none-any.whl
- Upload date:
- Size: 17.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.0.0 requests-toolbelt/0.9.1 tqdm/4.41.1 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9decb290e655c1bd8b851cdf95556162c8285bb404b459dabada1f0ac8c70d2a
|
|
| MD5 |
3f6d412bf4f73e7e0d62a956d787df3a
|
|
| BLAKE2b-256 |
3138877e41e197bf1aec6a73533b0fb7ae326ec5decf7a3d7ce4b6ad577070de
|







