Random Access To Archived Resources

Project description

Random Access To Archived Resources (Ratarmount)











Ratarmount collects all file positions inside a TAR so that it can easily jump to and read from any file without extracting it. It, then, mounts the TAR using mfusepy, a fork of fusepy, for read access just like archivemount. In contrast to libarchive, on which archivemount is based, random access and true seeking is supported. And in contrast to tarindexer, which also collects file positions for random access, ratarmount offers easy access via FUSE and support for compressed TARs.
Capabilities:
- Random Access: Care was taken to achieve fast random access inside compressed streams for bzip2, gzip, xz, and zstd and inside TAR files by building indices containing seek points.
- Highly Parallelized: By default, all cores are used for parallelized algorithms like for the gzip, bzip2, and xz decoders.
This can yield huge speedups on most modern processors but requires more main memory.
It can be controlled or completely turned off using the
-P <cores>option. - Recursive Mounting: Ratarmount will also mount TARs inside TARs inside TARs, ... recursively into folders of the same name, which is useful for the 1.31TB ImageNet data set.
- Mount Compressed Files: You may also mount files with one of the supported compression schemes. Even if these files do not contain a TAR, you can leverage ratarmount's true seeking capabilities when opening the mounted uncompressed view of such a file.
- Read-Only Bind Mounting: Folders may be mounted read-only to other folders for usecases like merging a backup TAR with newer versions of those files residing in a normal folder.
- Union Mounting: Multiple TARs, compressed files, and bind mounted folders can be mounted under the same mountpoint.
- Write Overlay: A folder can be specified as write overlay. All changes below the mountpoint will be redirected to this folder and deletions are tracked so that all changes can be applied back to the archive.
- Remote Files and Folders: A remote archive or whole folder structure can be mounted similar to tools like sshfs thanks to the filesystem_spec project. These can be specified with URIs as explained in the section "Remote Files". Supported remote protocols include: FTP, HTTP, HTTPS, SFTP, SSH, Git, Github, S3, Samba v2 and v3, Dropbox, ... Many of these are very experimental and may be slow. Please open a feature request if further backends are desired.
A complete list of supported formats can be found here.
Examples
ratarmount archive.tar.gzto mount a compressed archive at a folder calledarchiveand make its contents browsable.ratarmount --recursive archive.tar mountpointto mount the archive and recursively all its contained archives under a folder calledmountpoint.ratarmount folder mountpointto bind-mount a folder.ratarmount folder1 folder2 mountpointto bind-mount a merged view of two (or more) folders undermountpoint.ratarmount folder archive.zip folderto mount a merged view of a folder on top of archive contents.ratarmount -o modules=subdir,subdir=squashfs-root archive.squashfs mountpointto mount an archive subfoldersquashfs-rootundermountpoint.ratarmount http://server.org:80/archive.rar folder folderMount an archive that is accessible via HTTP range requests.ratarmount ssh://hostname:22/relativefolder/ mountpointMount a folder hierarchy via SSH.ratarmount ssh://hostname:22//tmp/tmp-abcdef/ mountpointratarmount github://mxmlnkn:ratarmount@v0.15.2/tests/ mountpointMount a github repo as if it was checked out at the given tag or SHA or branch.AWS_ACCESS_KEY_ID=01234567890123456789 AWS_SECRET_ACCESS_KEY=0123456789012345678901234567890123456789 ratarmount s3://127.0.0.1/bucket/single-file.tar mountedMount an archive inside an S3 bucket reachable via a custom endpoint with the given credentials. Bogus credentials may be necessary for unsecured endpoints.
Table of Contents
Installation
You can install ratarmount either by simply downloading the AppImage or via pip. The latter might require installing additional dependencies. The latest nightly build AppImage can be found here.
pip install ratarmount
If you want all features, some of which may possibly result in installation errors on some systems, install with:
pip install ratarmount[full]
Installation via AppImage
The AppImage files are attached under "Assets" on the releases page.
They require no installation and can be simply executed like a portable executable.
If you want to install it, you can simply copy it into any of the folders listed in your PATH.
appImageName=ratarmount-0.15.0-x86_64.AppImage
wget 'https://github.com/mxmlnkn/ratarmount/releases/download/v0.15.0/$appImageName'
chmod u+x -- "$appImageName"
./"$appImageName" --help # Simple test run
sudo cp -- "$appImageName" /usr/local/bin/ratarmount # Example installation
Installation via Package Manager

Arch Linux
Arch Linux's AUR offers ratarmount as stable and development package. Use an AUR helper, like yay or paru, to install one of them:
# stable version
paru -Syu ratarmount
# development version
paru -Syu ratarmount-git
Conda
conda install -c conda-forge ratarmount
System Dependencies for PIP Installation (Rarely Necessary)
Python 3.6+, preferably pip 19.0+, FUSE, and sqlite3 are required. These should be preinstalled on most systems.
On Debian-like systems like Ubuntu, you can install/update all dependencies using:
sudo apt install python3 python3-pip fuse sqlite3 unar libarchive13 lzop gcc liblzo2-dev
On macOS, you have to install macFUSE and other optional dependencies with:
brew install macfuse unar libarchive lrzip lzop lzo
If you are installing on a system for which there exists no manylinux wheel, then you'll have to install further dependencies that are required to build some of the Python packages that ratarmount depends on from source:
sudo apt install \
python3 python3-pip fuse \
build-essential software-properties-common \
zlib1g-dev libzstd-dev liblzma-dev cffi libarchive-dev liblzo2-dev gcc
PIP Package Installation
Then, you can simply install ratarmount from PyPI:
pip install ratarmount
Or, if you want to test the latest version:
python3 -m pip install --user --force-reinstall \
'git+https://github.com/mxmlnkn/ratarmount.git#egginfo=ratarmountcore&subdirectory=core' \
'git+https://github.com/mxmlnkn/ratarmount.git#egginfo=ratarmount'
If there are troubles with the compression backend dependencies, you can try the pip --no-deps argument.
Ratarmount will work without the compression backends.
The hard requirements are fusepy and for Python versions older than 3.7.0 dataclasses.
Argument Completion
Ratarmount has support for argument completion in bash and zsh via argcomplete if it is installed.
On Debian-like systems, this sets everything up in /etc/bash_completion.d/global-python-argcomplete to work out-of-the-box with any Python tool that supports argcomplete:
sudo apt install python3-argcomplete
# Restart your shell.
ratarmount --<tab><tab>
Manual installation also works:
pip install argcomplete
# Either add this to your .bashrc
eval "$( register-python-argcomplete ratarmount )"
# Or run this script to install argcomplete globally (into `~/.bash_completion` and `~/.zshenv`):
activate-global-python-argcomplete # Requires a restart of your shell to.
ratarmount --<tab><tab>
Graphical User Interface (GUI)
If a graphical user interface is wanted, give one of these a try:
- Ratarmount UI: Created by Jan Prach based on GTK4, and with Gnome Nautilus integration
- A work-in-progress Qt-based Ratarmount GUI by me is available on the gui branch. It can be installed with
pip install --user --force-reinstall \ 'git+https://github.com/mxmlnkn/ratarmount.git@gui#egginfo=ratarmount'{'core&subdirectory=core',}and run withratarmount --gui <archive>. It is still very experimental, but basic functionality should work. Feedback would be welcome.
Supported Formats
TAR compressions supported for random access
- BZip2 as provided by indexed_bzip2 as a backend, which is a refactored and extended version of bzcat from toybox. See also the reverse engineered specification.
- Gzip and Zlib as provided by rapidgzip or indexed_gzip by Paul McCarthy. See also RFC1952 and RFC1950.
- Xz as provided by python-xz by Rogdham or lzmaffi by Tomer Chachamu. See also The .xz File Format.
- Zstd as provided by indexed_zstd by Marco Martinelli. See also Zstandard Compression Format.
Other supported archive formats
- TAR, Docker/OCI Images as provided by CPython's tarfile module. This includes support for Docker Images and OCI images, which are TAR files with specified layouts and metadata files.
- Rar as provided by rarfile by Marko Kreen. See also the RAR 5.0 archive format.
- SquashFS, AppImage, Snap, SIF as provided by PySquashfsImage by Matteo Mattei. There seems to be no authoritative, open format specification, only this nicely-done reverse-engineered description, I assume based on the source code. Note that Snaps, Appimages, and Singularity Image Format are, or contain, SquashFS images, with an executable prepended for AppImages, and other data prepended for SIF files.
- Zip as provided by zipfile, which is distributed with Python itself. See also the ZIP File Format Specification.
- 7z via libarchive or py7zr for encrypted 7z archives by Hiroshi Miura.
- FAT12/FAT16/FAT32/VFAT as provided by PyFatFS by Nathan-J. Hirschauer. See also Microsoft's FAT32 File System Specification.
- EXT4 as provided by python-ext4 by Nathaniel van Diepen. See also the Linux kernel docs for EXT4.
- SQLAR via CPython's sqlite3 module or via the Python3 bindings to sqlcipher for encrypted archives.
- HTML files with embedded data URLs, such as those created by Firefox's Save Page WE extension or similar ones. The base64-encoded embedded files are exposed via the virtual file system in subfolders based on
data-srcURLs in a similar manner to thePage Info -> Mediafunctionality. - Ratarmount Indexes can also be mounted directly without the associated archive. This can be useful for viewing the file tree hierarchy in cases where the contents are not required, e.g., to search in indexes to archives stored in cold storage. A longer term goal of mine would be some kind metadata database with computed hashes, thumbnails, and others that can be mounted and searched, similar to the locate family of commands on Linux, but for archival usage, i.e., for disconnected media, and with recursion into archives, something like Tracker but less intrusive and for browsing, not just searching in the metadata, something like iRods but less complicated. (If anyone knows of such a tool or needs help with it, please contact me, e.g., via an issue.)
- Many Others as provided by libarchive via python-libarchive-c.
- Formats with tests: 7z, ar, cab, compress, cpio, iso, lrzip, lzma, lz4, lzip, lzo, warc, xar.
- Untested formats that might work or not: deb, grzip, rpm, uuencoding.
- Beware that libarchive has no performant random access to files and to file contents. In order to seek or open a file, in general, it needs to be assumed that the archive has to be parsed from the beginning. If you have a performance-critical use case for a format only supported via libarchive, then please open a feature request for a faster customized archive format implementation. The hope would be to add suitable stream compressors such as "short"-distance LZ-based compressions to rapidgzip.
Benchmarks
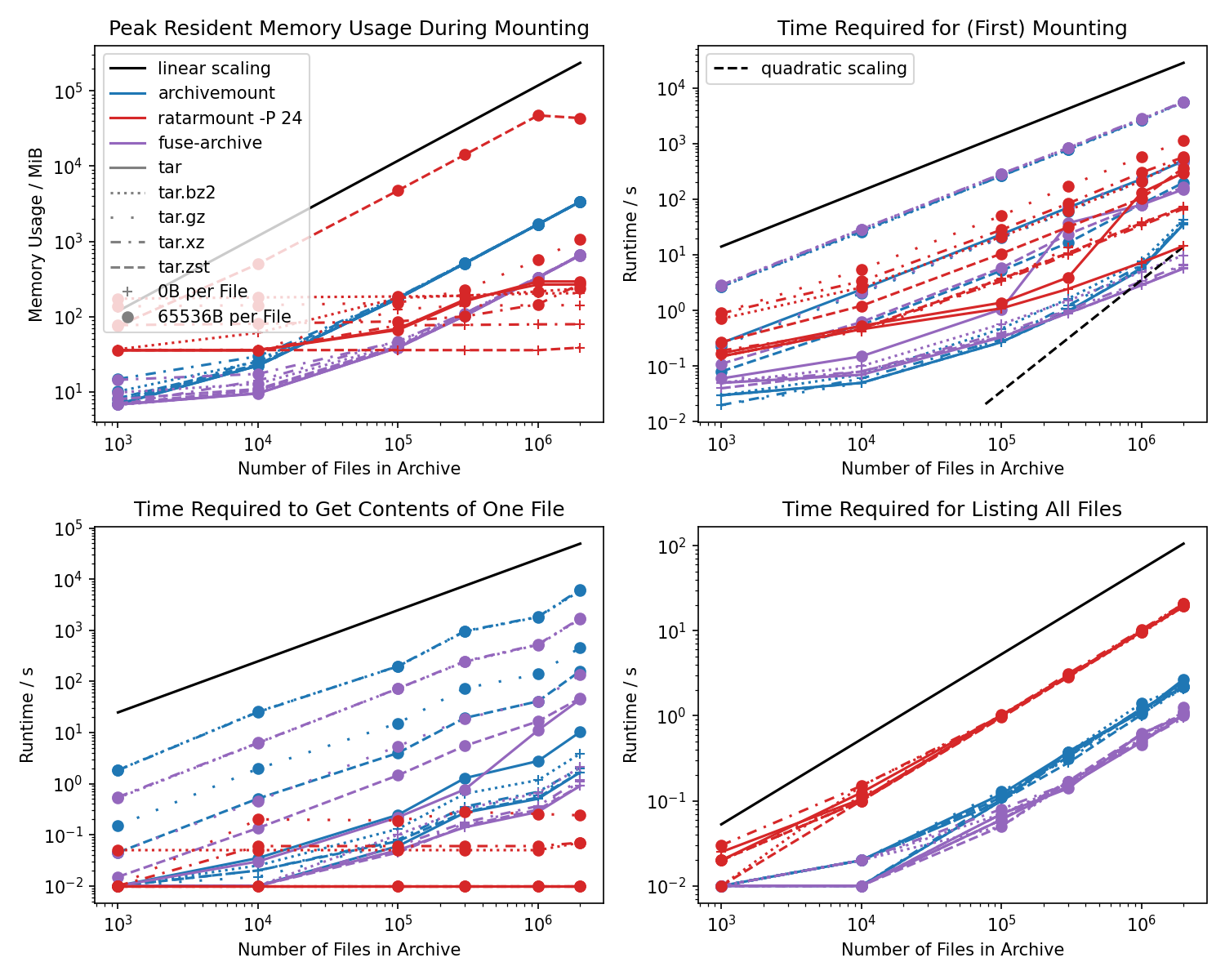
- Not shown in the benchmarks, but ratarmount can mount files with preexisting index sidecar files in under a second making it vastly more efficient compared to archivemount for every subsequent mount.
Also, archivemount has no progress indicator making it very unlikely the user will wait hours for the mounting to finish.
Fuse-archive, an iteration on archivemount, has the
--asyncprogressoption to give a progress indicator using the timestamp of a dummy file. Note that fuse-archive daemonizes instantly but the mount point will not be usable for a long time and everything trying to use it will hang until then when not using--asyncprogress! - Getting file contents of a mounted archive is generally vastly faster than archivemount and fuse-archive and does not increase with the archive size or file count resulting in the largest observed speedups to be around 5 orders of magnitude!
- Memory consumption of ratarmount is mostly less than archivemount and mostly does not grow with the archive size.
Not shown in the plots, but the memory usage will be much smaller when not specifying
-P 0, i.e., when not parallelizing. The gzip backend grows linearly with the archive size because the data for seeking is thousands of times larger than the simple two 64-bit offsets required for bzip2. The memory usage of the zstd backend only seems humongous because it usesmmapto open. The memory used bymmapis not even counted as used memory when showing the memory usage withfreeorhtop. - For empty files, mounting with ratarmount and archivemount does not seem be bounded by decompression nor I/O bandwidths but instead by the algorithm for creating the internal file index. This algorithm scales linearly for ratarmount and fuse-archive but seems to scale worse than even quadratically for archives containing more than 1M files when using archivemount. Ratarmount 0.10.0 improves upon earlier versions by batching SQLite insertions.
- Mounting bzip2 and xz archives has actually become faster than archivemount and fuse-archive with
ratarmount -P 0on most modern processors because it actually uses more than one core for decoding those compressions.indexed_bzip2supports block parallel decoding since version 1.2.0. - Gzip compressed TAR files are two times slower than archivemount during first time mounting. It is not totally clear to me why that is because streaming the file contents after the archive being mounted is comparably fast, see the next benchmarks below. In order to have superior speeds for both of these, I am experimenting with a parallelized gzip decompressor like the prototype pugz offers for non-binary files only.
- For the other cases, mounting times become roughly the same compared to archivemount for archives with 2M files in an approximately 100GB archive.
- Getting a lot of metadata for archive contents as demonstrated by calling
findon the mount point is an order of magnitude slower compared to archivemount. Because the C-based fuse-archive is even slower than ratarmount, the difference is very likely that archivemount uses the low-level FUSE interface while ratarmount and fuse-archive use the high-level FUSE interface.
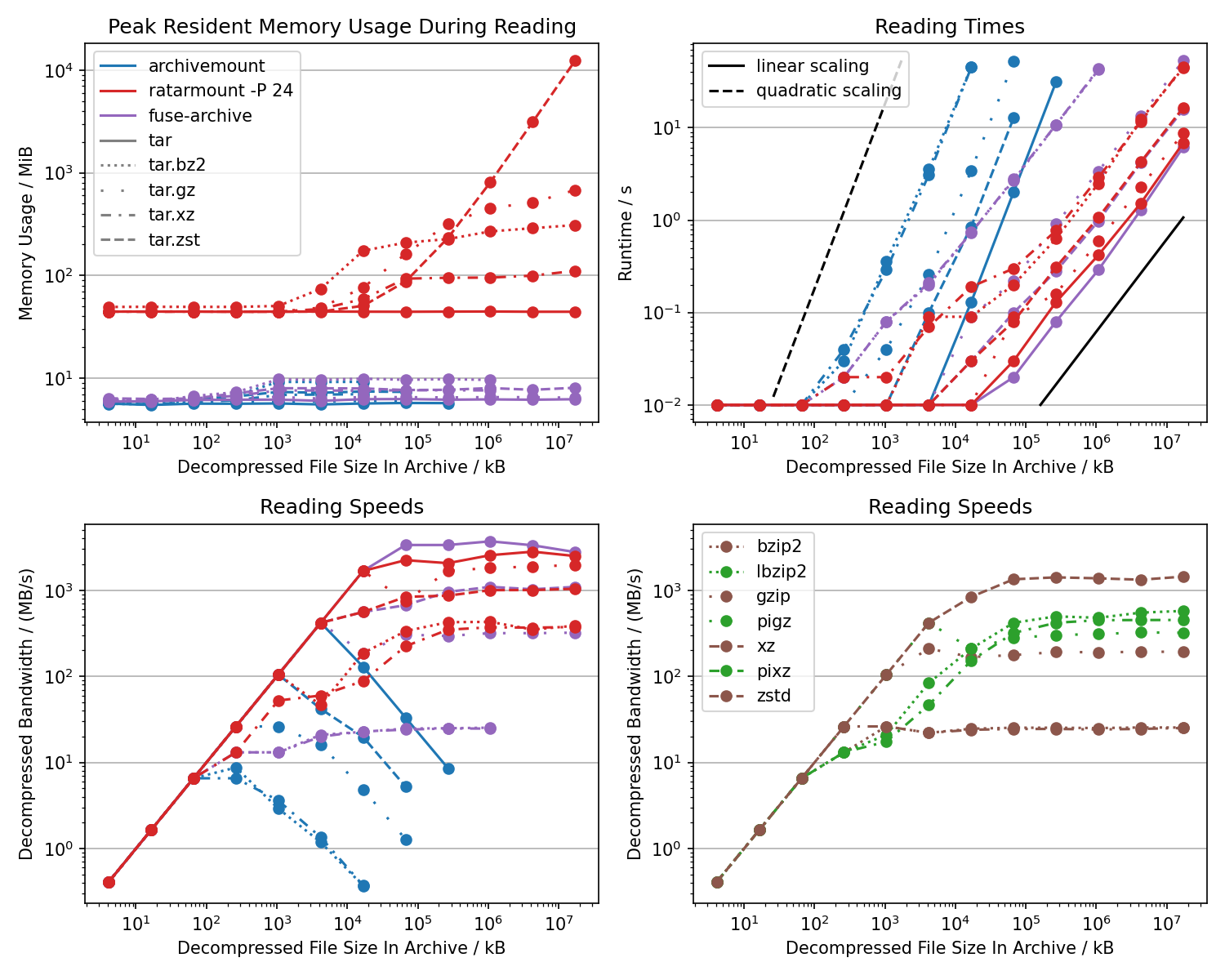
- Reading files from the archive with archivemount are scaling quadratically instead of linearly.
This is because archivemount starts reading from the beginning of the archive for each requested I/O block.
The block size depends on the program or operating system and should be in the order of 4 kiB.
Meaning, the scaling is
O( (sizeOfFileToBeCopiedFromArchive / readChunkSize)^2 ). Both, ratarmount and fuse-archive avoid this behavior. Because of this quadratic scaling, the average bandwidth with archivemount seems like it decreases with the file size. - Reading bz2 and xz are both an order of magnitude faster, as tested on my 12/24-core Ryzen 3900X, thanks to parallelization.
- Memory is bounded in these tests for all programs but ratarmount is a lot more lax with memory because it uses a Python stack and because it needs to hold caches for a constant amount of blocks for parallel decoding of bzip2 and xz files. The zstd backend in ratarmount looks unbounded because it uses mmap, whose memory usage will automatically stop and be freed if the memory limit has been reached.
- The peak for the xz decoder reading speeds happens because some blocks will be cached when loading the index, which is not included in the benchmark for technical reasons. The value for the 1 GiB file size is more realistic.
Further benchmarks can be viewed here.
The Problem
You downloaded a large TAR file from the internet, for example the 1.31TB large ImageNet, and you now want to use it but lack the space, time, or a file system fast enough to extract all the 14.2 million image files.
Existing Partial Solutions
Partial Solutions
Archivemount
Archivemount seems to have large performance issues for too many files and large archive for both mounting and file access in version 0.8.7. A more in-depth comparison benchmark can be found here.
- Mounting the 6.5GB ImageNet Large-Scale Visual Recognition Challenge 2012 validation data set, and then testing the speed with:
time cat mounted/ILSVRC2012_val_00049975.JPEG | wc -ctakes 250ms for archivemount and 2ms for ratarmount. - Trying to mount the 150GB ILSVRC object localization data set containing 2 million images was given up upon after 2 hours. Ratarmount takes ~15min to create a ~150MB index and <1ms for opening an already created index (SQLite database) and mounting the TAR. In contrast, archivemount will take the same amount of time even for subsequent mounts.
- Does not support recursive mounting. Although, you could write a script to stack archivemount on top of archivemount for all contained TAR files.
Tarindexer
Tarindex is a command line to tool written in Python which can create index files and then use the index file to extract single files from the tar fast. However, it also has some caveats which ratarmount tries to solve:
- It only works with single files, meaning it would be necessary to loop over the extract-call. But this would require loading the possibly quite large tar index file into memory each time. For example for ImageNet, the resulting index file is hundreds of MB large. Also, extracting directories will be a hassle.
- It's difficult to integrate tarindexer into other production environments. Ratarmount instead uses FUSE to mount the TAR as a folder readable by any other programs requiring access to the contained data.
- Can't handle TARs recursively. In order to extract files inside a TAR which itself is inside a TAR, the packed TAR first needs to be extracted.
TAR Browser
I didn't find out about TAR Browser before I finished the ratarmount script. That's also one of it's cons:
- Hard to find. I don't seem to be the only one who has trouble finding it as it has one star on Github after 7 years compared to 45 stars for tarindexer after roughly the same amount of time.
- Hassle to set up. Needs compilation and I gave up when I was instructed to set up a MySQL database for it to use. Confusingly, the setup instructions are not on its Github but here.
- Doesn't seem to support recursive TAR mounting. I didn't test it because of the MysQL dependency but the code does not seem to have logic for recursive mounting.
- Xz compression also is only block or frame based, i.e., only works faster with files created by pixz or pxz.
Pros:
- supports bz2- and xz-compressed TAR archives
The Solution
Ratarmount creates an index file with file names, ownership, permission flags, and offset information.
This sidecar is stored at the TAR file's location or in ~/.ratarmount/.
Ratarmount can load that index file in under a second if it exists and then offers FUSE mount integration for easy access to the files inside the archive.
Here is a more recent test for version 0.2.0 with the new default SQLite backend:
- TAR size: 124GB
- Contains TARs: yes
- Files in TAR: 1000
- Files in TAR (including recursively in contained TARs): 1.26 million
- Index creation (first mounting): 15m 39s
- Index size: 146MB
- Index loading (subsequent mounting): 0.000s
- Reading a 64kB file: ~4ms
- Running 'find mountPoint -type f | wc -l' (1.26M stat calls): 1m 50s
The reading time for a small file simply verifies the random access by using file seek to be working. The difference between the first read and subsequent reads is not because of ratarmount but because of operating system and file system caches.
Older test with 1.31 TB Imagenet (Fall 2011 release)
The test with the first version of ratarmount (50e8dbb), which used the, as of now removed, pickle backend for serializing the metadata index, for the ImageNet data set:
- TAR size: 1.31TB
- Contains TARs: yes
- Files in TAR: ~26 000
- Files in TAR (including recursively in contained TARs): 14.2 million
- Index creation (first mounting): 4 hours
- Index size: 1GB
- Index loading (subsequent mounting): 80s
- Reading a 40kB file: 100ms (first time) and 4ms (subsequent times)
Index loading is relatively slow with 80s because of the pickle backend, which now has been replaced with SQLite and should take less than a second now.
Usage
Command Line Options
See ratarmount --help or here.
Metadata Index Cache
In order to reduce the mounting time, the created index for random access to files inside the tar will be saved to one of these locations. These locations are checked in order and the first, which works sufficiently, will be used. This is the default location order:
- ~/.ratarmount/<path to tar: '/' -> '_'>.index.sqlite E.g., ~/.ratarmount/_media_cdrom_programm.tar.index.sqlite
This list of fallback folders can be overwritten using the --index-folders
option. Furthermore, an explicitly named index file may be specified using
the --index-file option. If --index-file is used, then the fallback
folders, including the default ones, will be ignored!
Bind Mounting
The mount sources can be TARs and/or folders. Because of that, ratarmount
can also be used to bind mount folders read-only to another path similar to
bindfs and mount --bind. So, for:
ratarmount folder mountpoint
all files in folder will now be visible in mountpoint.
Union Mounting
If multiple mount sources are specified, the sources on the right side will be added to or update existing files from a mount source left of it. For example:
ratarmount folder1 folder2 mountpoint
will make both, the files from folder1 and folder2, visible in mountpoint.
If a file exists in both multiple source, then the file from the rightmost
mount source will be used, which in the above example would be folder2.
If you want to update / overwrite a folder with the contents of a given TAR, you can specify the folder both as a mount source and as the mount point:
ratarmount folder file.tar folder
The FUSE option -o nonempty will be automatically added if such a usage is detected. If you instead want to update a TAR with a folder, you only have to swap the two mount sources:
ratarmount file.tar folder folder
File versions
If a file exists multiple times in a TAR or in multiple mount sources, then the hidden versions can be accessed through special .versions folders. For example, consider:
ratarmount folder updated.tar mountpoint
and the file foo exists both in the folder and as two different versions
in updated.tar. Then, you can list all three versions using:
ls -la mountpoint/foo.versions/
dr-xr-xr-x 2 user group 0 Apr 25 21:41 .
dr-x------ 2 user group 10240 Apr 26 15:59 ..
-r-x------ 2 user group 123 Apr 25 21:41 1
-r-x------ 2 user group 256 Apr 25 21:53 2
-r-x------ 2 user group 1024 Apr 25 22:13 3
In this example, the oldest version has only 123 bytes while the newest and by default shown version has 1024 bytes. So, in order to look at the oldest version, you can simply do:
cat mountpoint/foo.versions/1
Note that these version numbers are the same as when used with tar's
--occurrence=N option.
Prefix Removal
Use ratarmount -o modules=subdir,subdir=<prefix> to remove path prefixes
using the FUSE subdir module. Because it is a standard FUSE feature, the
-o ... argument should also work for other FUSE applications.
When mounting an archive created with absolute paths, e.g.,
tar -P cf /var/log/apt/history.log, you would see the whole var/log/apt
hierarchy under the mount point. To avoid that, specified prefixes can be
stripped from paths so that the mount target directory directly contains
history.log. Use ratarmount -o modules=subdir,subdir=/var/log/apt/ to do
so. The specified path to the folder inside the TAR will be mounted to root,
i.e., the mount point.
Compressed non-TAR files
If you want a compressed file not containing a TAR, e.g., foo.bz2, then
you can also use ratarmount for that. The uncompressed view will then be
mounted to <mountpoint>/foo and you will be able to leverage ratarmount's
seeking capabilities when opening that file.
Xz and Zst Files
In contrast to bzip2 and gzip compressed files, true seeking on XZ and ZStandard files is only possible at block or frame boundaries. This wouldn't be noteworthy, if both standard compressors for xz and zstd were not by default creating unsuited files. Even though both file formats do support multiple frames and XZ even contains a frame table at the end for easy seeking, both compressors write only a single frame and/or block out, making this feature unusable. The standard zstd tool does not support setting smaller block sizes yet although an issue does exist.
In order to generate truly seekable compressed files, you'll have to use pixz for XZ files.
You can check with xz -l <file> for the number of streams and blocks in the generated XZ file.
For ZStandard, you can use zstd -l <file> to check that a file contains more than one frame and therefore is seekable.
These are some possibilities to create seekable ZStandard files:
-
pzstd: It comes installed with the
zstdUbuntu/Debian package. Unfortunately, it it is in "maintenance-only mode" even though there is no replacement for the multi-stream functionality.zstd -T0does use parallelism but creates only a single frame and hence unseekable file. -
zeekstd: Rust implementation of the ZStandard Seekable Format. It includes a CLI Tool, which can be used standalone or as a tar compressor
tar --use-compress-program 'zeekstd -' .... -
t2sz: There is a
debpackage on the releases page. If that cannot be used, it has to be compiled from the C sources using CMake. -
zstd-seekable-format-go: Some of the releases, e.g., v0.7.1 contain static binaries that can be downloaded and used without installation. Unfortunately, not all releases seem to have static binaries. So, if some other version is required it might be necessary to install from source with a Go compiler.
-
You can manually split the original file into parts, compress those parts, and then concatenate those parts together to get a suitable multiframe ZStandard file. Here is a bash function, which can be used for that:
Bash script: createMultiFrameZstd
createMultiFrameZstd() ( # Detect being piped into if [ -t 0 ]; then file=$1 frameSize=$2 if [[ ! -f "$file" ]]; then echo "Could not find file '$file'." 1>&2; return 1; fi fileSize=$( stat -c %s -- "$file" ) else if [ -t 1 ]; then echo 'You should pipe the output to somewhere!' 1>&2; return 1; fi echo 'Will compress from stdin...' 1>&2 frameSize=$1 fi if [[ ! $frameSize =~ ^[0-9]+$ ]]; then echo "Frame size '$frameSize' is not a valid number." 1>&2 return 1 fi # Create a temporary file. I avoid simply piping to zstd # because it wouldn't store the uncompressed size. if [[ -d /dev/shm ]]; then frameFile=$( mktemp --tmpdir=/dev/shm ); fi if [[ -z $frameFile ]]; then frameFile=$( mktemp ); fi if [[ -z $frameFile ]]; then echo "Could not create a temporary file for the frames." 1>&2 return 1 fi if [ -t 0 ]; then true > "$file.zst" for (( offset = 0; offset < fileSize; offset += frameSize )); do dd if="$file" of="$frameFile" bs=$(( 1024*1024 )) \ iflag=skip_bytes,count_bytes skip="$offset" count="$frameSize" 2>/dev/null zstd -c -q -- "$frameFile" >> "$file.zst" done else while true; do dd of="$frameFile" bs=$(( 1024*1024 )) \ iflag=count_bytes count="$frameSize" 2>/dev/null # pipe is finished when reading it yields no further data if [[ ! -s "$frameFile" ]]; then break; fi zstd -c -q -- "$frameFile" done fi 'rm' -f -- "$frameFile" )
In order to compress a file named
foointo a multiframe zst file calledfoo.zst, which contains frames sized 4MiB of uncompressed ata, you would call it like this:createMultiFrameZstd foo $(( 4*1024*1024 ))
It also works when being piped to. This can be useful for recompressing files to avoid having to decompress them first to disk.
lbzip2 -cd well-compressed-file.bz2 | createMultiFrameZstd $(( 4*1024*1024 )) > recompressed.zst
Remote Files
The fsspec API backend adds support for mounting many remote archive or folders. Please refer to the linked respective backend documentation to see the full configuration options, especially for specifying credentials. Some often-used configuration environment variables are copied here for easier viewing.
| Symbol | Description |
|---|---|
[something] |
Optional "something" |
(one|two) |
Either "one" or "two" |
-
git://[path-to-repo:][ref@]path/to/file
Uses the current path if no repository path is specified. Backend: ratarmountcore via pygit2 -
github://org:repo@[sha]/path-to/file-or-folder
Example:github://mxmlnkn:ratarmount@v0.15.2/tests/single-file.tar
Backend: fsspec -
http[s]://hostname[:port]/path-to/archive.rar
Backend: fsspec via aiohttp -
(ipfs|ipns)://content-identifier
Example:ipfs daemon & sleep 2 && ratarmount -f ipfs://QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG mounted
Backend: fsspec/ipfsspec
Tries to connect to running localipfs daemoninstance by default, which needs to be started beforehand.Alternatively, a (public) gateway can be specified with the environment variableSpecifying a public gateway does not (yet) work because of this issue.IPFS_GATEWAY, e.g.,https://127.0.0.1:8080. -
s3://[endpoint-hostname[:port]]/bucket[/single-file.tar[?versionId=some_version_id]]
Backend: fsspec/s3fs via boto3
The URL will default to AWS according to the Boto3 library defaults when no endpoint is specified. Boto3 will check, among others, these environment variables, for credentials:AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY,AWS_SESSION_TOKEN,AWS_DEFAULT_REGION
fsspec/s3fs furthermore supports this environment variable:
FSSPEC_S3_ENDPOINT_URL, e.g.,http://127.0.0.1:8053
-
ftp://[user[:password]@]hostname[:port]/path-to/archive.rar
Backend: fsspec via ftplib -
(ssh|sftp)://[user[:password]@]hostname[:port]/path-to/archive.rar
Backend: fsspec/sshfs via asyncssh
The usual configuration via~/.ssh/configis supported. -
smb://[workgroup;][user:password@]server[:port]/share/folder/file.tar -
webdav://[user:password@]host[:port][/path]
Backend: webdav4 via httpx
Environment variables:WEBDAV_USER,WEBDAV_PASSWORD -
dropbox://path
Backend: fsspec/dropboxdrivefs via dropbox-sdk-python
Follow these instructions to create an app. Check thefiles.metadata.readandfiles.content.readpermissions and press "submit" and after that create the (long) OAuth 2 token and store it in the environment variableDROPBOX_TOKEN. Ignore the (short) app key and secret. This creates a corresponding app folder that can be filled with data.
Many other fsspec-based projects may also work when installed.
This functionality of ratarmount offers a hopefully more-tested and out-of-the-box experience over the experimental fsspec.fuse implementation. And, it also works in conjunction with the other features of ratarmount such as union mounting and recursive mounting.
Index files specified with --index-file can also be compressed and/or be an fsspec (chained) URL, e.g., https://host.org/file.tar.index.sqlite.gz.
In such a case, the index file will be downloaded and/or extracted into the default temporary folder.
If the default temporary folder has insufficient disk space, it can be changed by setting the RATARMOUNT_INDEX_TMPDIR environment variable.
Writable Mounting
The --write-overlay <folder> option can be used to create a writable mount point.
The original archive will not be modified.
- File creations will create these files in the specified overlay folder.
- File deletions and renames will be registered in a database that also resides in the overlay folder.
- File modifications will copy the file from the archive into the overlay folder before applying the modification.
This overlay folder can be stored alongside the archive or it can be deleted after unmounting the archive. This is useful when building the executable from a source tarball without extracting. After installation, the intermediary build files residing in the overlay folder can be safely removed.
If it is desired to apply the modifications to the original archive, then the --commit-overlay can be prepended to the original ratarmount call.
Here is an example for applying modifications to a writable mount and then committing those modifications back to the archive:
-
Mount it with a write overlay and add new files. The original archive is not modified.
ratarmount --write-overlay example-overlay example.tar example-mount-point echo "Hello World" > example-mount-point/new-file.txt
-
Unmount. Changes persist solely in the overlay folder.
fusermount -u example-mount-point
-
Commit changes to the original archive.
ratarmount --commit-overlay --write-overlay example-overlay example.tar example-mount-point
Output:
To commit the overlay folder to the archive, these commands have to be executed: tar --delete --null --verbatim-files-from --files-from='/tmp/tmp_ajfo8wf/deletions.lst' \ --file 'example.tar' 2>&1 | sed '/^tar: Exiting with failure/d; /^tar.*Not found in archive/d' tar --append -C 'zlib-wiki-overlay' --null --verbatim-files-from --files-from='/tmp/tmp_ajfo8wf/append.lst' --file 'example.tar' Committing is an experimental feature! Please confirm by entering "commit". Any other input will cancel. > Committed successfully. You can now remove the overlay folder at example-overlay.
-
Verify the modifications to the original archive.
tar -tvlf example.tar
Output:
-rw-rw-r-- user/user 652817 2022-08-08 10:44 example.txt -rw-rw-r-- user/user 12 2023-02-16 09:49 new-file.txt -
Remove the obsole write overlay folder.
rm -r example-overlay
As a Library
Ratarmount can also be used as a library. Using ratarmountcore, files inside archives can be accessed directly from Python code without requiring FUSE. For a more detailed description, see the ratarmountcore readme here.
Fsspec Integration
To use all fsspec features, either install via pip install ratarmount[fsspec] or pip install ratarmount[fsspec].
It should also suffice to simply pip install fsspec if ratarmountcore is already installed.
The optional fsspec integration is threefold:
- Files can be specified on the command line via URLs pointing to remotes as explained in this section.
- A
ratarmountcore.MountSourcewrapping fsspecAbstractFileSystemimplementation has been added. A specializedSQLiteIndexedTarFileSystemas a more performant and direct replacement forfsspec.implementations.TarFileSystemhas also been added.from ratarmountcore.SQLiteIndexedTarFsspec import SQLiteIndexedTarFileSystem as ratarfs fs = ratarfs("tests/single-file.tar") print("Files in root:", fs.ls("/", detail=False)) print("Contents of /bar:", fs.cat("/bar"))
- During installation ratarmountcore registers the
ratar://protocol with fsspec via an entrypoint group. This enables usages withfsspec.open. The fsspec URL chaining feature must be used in order for this to be useful. Example for opening the filebar, which is contained inside the filetests/single-file.tar.gzwith ratarmountcore:import fsspec with fsspec.open("ratar://bar::file://tests/single-file.tar.gz") as file: print("Contents of file bar:", file.read())
This also works with pandas:import fsspec import pandas as pd with fsspec.open("ratar://bar::file://tests/single-file.tar.gz", compression=None) as file: print("Contents of file bar:", file.read())
Thecompression=Noneargument is currently necessary because of this Pandas bug.
File Joining
Files with sequentially numbered extensions can be mounted as a joined file. If it is an archive, then the joined archive file will be mounted. Only one of the files, preferably the first one, should be specified. For example:
base64 /dev/urandom | head -c $(( 1024 * 1024 )) > 1MiB.dat
tar -cjf- 1MiB.dat | split -d --bytes=320K - file.tar.gz.
ls -la
# 320K file.tar.gz.00
# 320K file.tar.gz.01
# 138K file.tar.gz.02
ratarmount file.tar.gz.00 mounted
ls -la mounted
# 1.0M 1MiB.dat
Mount Point Control Interface
The FUSE mount contains a special hidden .ratarmount-control folder with special files inside it.
.ratarmount-control/output: Contains the errors and log output of the ratarmount process. Especially useful when it runs in the background. Alternatively,-fcan be used to keep it in the foreground..ratarmount-control/command: Command line invocations can be written into this file to invoke another ratarmount subprocess. Command lines must start withratarmount<delimiter>, where<delimiter>can be\n(newline), or\0(null byte).
For example, try:
ratarmount --control-interface mounted
echo "ratarmount -d 3 $PWD/tests/single-file.tar $HOME/mounted" > mounted/.ratarmount-control/command
sleep 1
cat mounted/.ratarmount-control/command
HTML support
HTML files with embedded data files, e.g., as saved with Firefox's Save Page WE extension can be mounted to expose these embedded files as actual files in a file hierarchy. This can be used to inspect resources similar to Firefox's Page Info Window.
This HTML file:
<img data-savepage-src="https://example.com/logo.png"
src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mNkYPhfDwAChwGA60e6kgAAAABJRU5ErkJggg==">
will be mounted as:
/mnt/html/
└── https:/example.com/logo.png
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ratarmount-1.3.0.tar.gz.
File metadata
- Download URL: ratarmount-1.3.0.tar.gz
- Upload date:
- Size: 105.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9e96f0f887db67a3ea68c4ecc625c05a3636cd8f29d80491eb170d934d3caa00
|
|
| MD5 |
43cf7be1cf6b8f9d365b4837e1b68628
|
|
| BLAKE2b-256 |
a580f7f628af7652a89b7f400b23fea17395dd6b27949ae8a45b6e81d69bd810
|
File details
Details for the file ratarmount-1.3.0-py3-none-any.whl.
File metadata
- Download URL: ratarmount-1.3.0-py3-none-any.whl
- Upload date:
- Size: 66.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f445863df17b73eb55bf8e4b42f998f4413f7b26b0f0dbd592f21b32384ad08c
|
|
| MD5 |
c9ccd012fa231cfbdd8dd1a2ae499df1
|
|
| BLAKE2b-256 |
4c63ff974dc95cfb4ff45cd3c8ac707c8853182ec5792659506eb6bc1346f403
|







