Linear left barrier loss and data augmention for survival anlysis

Project description
RATIO-T2E
This package contains 3 different elements:
- suRvival Analysis lefT barrIer lOss (RATIO) + uniFormatIve fEatureS daTa Augmentation (FIESTA) + Ridge model
- suRvival Analysis lefT barrIer lOss (RATIO) - loss function
- uniFormatIve fEatureS daTa Augmentation (FIESTA) class
Prerequisites
Before you begin, ensure you have met the following requirements:
- Checked for Windows only
- python 3.8
Installing RATIO-T2E
pip install ratio-t2e
suRvival Analysis lefT barrIer lOss (RATIO) + uniFormatIve fEatureS daTa Augmentation (FIESTA) + Ridge model
This model solves a regression problem where the loss function is the Mean Square Error (MSE)
for the uncensored data and the RATIO loss for the wrong censored samples.
The user can moderate the relations between the censored and uncensored loss.
For extremely small datasets ( < 50), Data augmentatuin (DA) should be added. The combination of RATIO and DA
is called FIESTA.
Using suRvival Analysis lefT barrIer lOss (RATIO) + uniFormatIve fEatureS daTa Augmentation (FIESTA) + Ridge model
To use the model follow these steps:
-
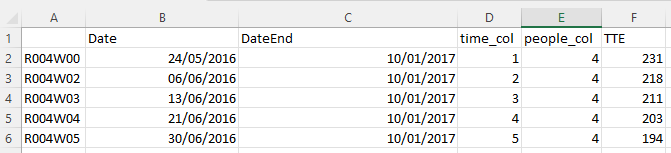
Divide your data to a censored dataframe and an uncensored dataframe, where a sample is condisered as censored when its time of a competing event preceeds the time to event (TTE), or when a sample did not have an event within the cohort's time. Make sure the dataframes consists of the following columns:
-
A TTE column for the uncensored dataframe and a competing times for the censored, that measures the times in days that have passes from the sample's date to the target date.
-
A column named "Date" of the date of the sample.
-
A column named "DateEnd" of the date of an event for uncensored, and date of competing event for censored.
-
A people column named similar to the people_col parameter, contains the identity of a patient.
-
A time column named similar to the time_col parameter, contains the order of samples for sequntial data.
Example of the mendatory columns:
-
-
Load the uncensored and censored datafrmes.
censored = pd.read_csv("censored_data_file_name.csv", index_col=0)
uncensored = pd.read_csv("uncensored_data_file_name.csv", index_col=0)
- Name the list of categorical features (name of columns).
list_of_categories = ['cat1', 'cat2', 'cat3', 'cat4']
- Create the LBL class with the parameters you want.
lbl = LBL("TTE_col", "people_col", "time_col", num_of_bact=881, feature_selection=20, categories=list_of_categories,
with_microbiome=False, augmented_censored=False, gamma=0.0)
-
Divide the uncensored dataframe into a training set and a test set.
-
Merge the uncensored training dataframe with the censored dataframe, for training.
-
Fit the model on the training set.
-
Use the predict function for prediction.
-
Use the score function for evaluations (Spearman Correlation Coefficient (SCC), AUC and Concordance Index (CI).
suRvival Analysis lefT barrIer lOss (RATIO) - loss function
Since the RATIO loss is "model-free", there is an option to add RATIO loss to any model.
Using the RATIO loss
To use RATIO:
import RATIO
RATIO.RATIO(y,y_hat)
where y is a Tensor of shape (batch_size,2), its first dimension is a binary indicator of having the event (= 1) or lacking the event (= 0), and its second dimension is the TTE.
uniFormatIve fEatureS daTa Augmentation (FIESTA) class
uniFormatIve fEatureS daTa Augmentation (FIESTA) defines the augmented TTE of the censored samples by using high dimensional and not highly informative data. The DA process contains 2 steps:
1. Defining the augmented TTE as a weighted average of the uncensored samples based
on the difference in M (high dimensional data) between samples (as described in our paper).
There are 3 options for declaying functions Exponential (function_1), Hyperbolic (function_2) and Cauchy (function_3), which
is the default.
2. Computing the augmented TTE using Maximum Likelihood Estimation (MLE) on a model
where a constant censoring rate of lamda is assumed and the event is normally distributed around the previously computed in step 1.
Using FIESTA
To use FIESTA:
import MLE_augmentor
MLE_augmentor.FIESTA.implement_augment(censored_df,lamda)
such that censored_df has to contain the mendatory columns as was explained above, and lamda is the assumed censoring rate.
Contributors
Shtossel Oshrit
Contact
If you want to contact me you can reach me at oshritvig@gmail.com
Citation


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ratio_t2e-0.0.6.tar.gz.
File metadata
- Download URL: ratio_t2e-0.0.6.tar.gz
- Upload date:
- Size: 15.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8f8a0eb2f2850657c0121222545c6e108c7673c66cb88d16b043bb64aff6eb57
|
|
| MD5 |
bd55951f1667560e350390d836ff32f4
|
|
| BLAKE2b-256 |
42cae335bf0264beb0690915e00a4b545004be881aea625d903b778968d7f308
|
File details
Details for the file ratio_t2e-0.0.6-py3-none-any.whl.
File metadata
- Download URL: ratio_t2e-0.0.6-py3-none-any.whl
- Upload date:
- Size: 15.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8818ddc20ce0821cdc5c6560daa8d96cb2ba4d5bf61be64d0d64f6c83fb1acf0
|
|
| MD5 |
65a53a58f617765f70a43dd9da540283
|
|
| BLAKE2b-256 |
25eb10a144c52ff53848d83bdc08c5ca3f5758d6b9925a4d3870772bc3cfa1f6
|







