Rainbow Query Language
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
RBQL is an eval-based SQL-like query engine for (not only) CSV file processing. It provides SQL-like language that supports SELECT queries with Python expressions.
RBQL is best suited for data transformation, data cleaning, and analytical queries.
Using RBQL as a Python library
If you want to use rbql module as a python library for your own app - please read API Documentation
The rbql module includes functions to query csv tables, pandas dataframes, python lists and more.
Using RBQL as IPython "magic" command
Syntax
%rbql <query>
Usage example
from vega_datasets import data
my_cars = data.cars()
%load_ext rbql
result_df = %rbql SELECT a.Name, a.Weight_in_lbs / 1000, a.Horsepower FROM my_cars WHERE a.Horsepower > 100 ORDER BY a.Weight_in_lbs DESC LIMIT 15
result_df
You can also visit the demo Google Colab notebook to try the %rbql "magic" command.
Using RBQL as a CLI App
Installation:
$ pip install rbql
Usage example (non-interactive mode):
$ rbql-py --query "select a1, a2 order by a1" --delim , < input.csv
Usage example (interactive mode):
In interactive mode rbql-py will show input table preview so it is easier to type SQL-like query.
$ rbql-py --input input.csv --output result.csv
Main Features
- Use Python expressions inside SELECT, UPDATE, WHERE and ORDER BY statements
- Supports multiple input formats
- Result set of any query immediately becomes a first-class table on its own
- No need to provide FROM statement in the query when the input table is defined by the current context.
- Supports all main SQL keywords
- Supports aggregate functions and GROUP BY queries
- Supports user-defined functions (UDF)
- Provides some new useful query modes which traditional SQL engines do not have
- Lightweight, dependency-free, works out of the box
Limitations:
- RBQL doesn't support nested queries, but they can be emulated with consecutive queries
- Number of tables in all JOIN queries is always 2 (input table and join table), use consecutive queries to join 3 or more tables
Supported SQL Keywords (Keywords are case insensitive)
- SELECT
- UPDATE
- WHERE
- ORDER BY ... [ DESC | ASC ]
- [ LEFT | INNER ] JOIN
- DISTINCT
- GROUP BY
- TOP N
- LIMIT N
- AS
All keywords have the same meaning as in SQL queries. You can check them online
RBQL variables
RBQL for CSV files provides the following variables which you can use in your queries:
- a1, a2,..., a{N}
Variable type: string
Description: value of i-th field in the current record in input table - b1, b2,..., b{N}
Variable type: string
Description: value of i-th field in the current record in join table B - NR
Variable type: integer
Description: Record number (1-based) - NF
Variable type: integer
Description: Number of fields in the current record - a.name, b.Person_age, ... a.{Good_alphanumeric_column_name}
Variable type: string
Description: Value of the field referenced by it's "name". You can use this notation if the field in the header has a "good" alphanumeric name - a["object id"], a['9.12341234'], b["%$ !! 10 20"] ... a["Arbitrary column name!"]
Variable type: string
Description: Value of the field referenced by it's "name". You can use this notation to reference fields by arbitrary values in the header
UPDATE statement
UPDATE query produces a new table where original values are replaced according to the UPDATE expression, so it can also be considered a special type of SELECT query.
Aggregate functions and queries
RBQL supports the following aggregate functions, which can also be used with GROUP BY keyword:
COUNT, ARRAY_AGG, MIN, MAX, ANY_VALUE, SUM, AVG, VARIANCE, MEDIAN
Limitation: aggregate functions inside Python expressions are not supported. Although you can use expressions inside aggregate functions.
E.g. MAX(float(a1) / 1000) - valid; MAX(a1) / 1000 - invalid.
There is a workaround for the limitation above for ARRAY_AGG function which supports an optional parameter - a callback function that can do something with the aggregated array. Example:
SELECT a2, ARRAY_AGG(a1, lambda v: sorted(v)[:5]) GROUP BY a2 - Python; SELECT a2, ARRAY_AGG(a1, v => v.sort().slice(0, 5)) GROUP BY a2 - JS
JOIN statements
Join table B can be referenced either by its file path or by its name - an arbitrary string which the user should provide before executing the JOIN query.
RBQL supports STRICT LEFT JOIN which is like LEFT JOIN, but generates an error if any key in the left table "A" doesn't have exactly one matching key in the right table "B".
Table B path can be either relative to the working dir, relative to the main table or absolute.
Limitation: JOIN statements can't contain Python/JS expressions and must have the following form: <JOIN_KEYWORD> (/path/to/table.tsv | table_name ) ON a... == b... [AND a... == b... [AND ... ]]
SELECT EXCEPT statement
SELECT EXCEPT can be used to select everything except specific columns. E.g. to select everything but columns 2 and 4, run: SELECT * EXCEPT a2, a4
Traditional SQL engines do not support this query mode.
UNNEST() operator
UNNEST(list) takes a list/array as an argument and repeats the output record multiple times - one time for each value from the list argument.
Example: SELECT a1, UNNEST(a2.split(';'))
LIKE() function
RBQL does not support LIKE operator, instead it provides "like()" function which can be used like this:
SELECT * where like(a1, 'foo%bar')
WITH (header) and WITH (noheader) statements
You can set whether the input (and join) CSV file has a header or not using the environment configuration parameters which could be --with_headers CLI flag or GUI checkbox or something else.
But it is also possible to override this selection directly in the query by adding either WITH (header) or WITH (noheader) statement at the end of the query.
Example: select top 5 NR, * with (header)
Pipe syntax for query chaining
You can chain consecutive queries via pipe | syntax. Example:
SELECT a2 AS region, count(*) AS cnt GROUP BY a2 | SELECT * ORDER BY a.cnt DESC
User Defined Functions (UDF)
RBQL supports User Defined Functions
You can define custom functions and/or import libraries in a special file:
~/.rbql_init_source.py- for Python
Examples of RBQL queries
With Python expressions
SELECT TOP 100 a1, int(a2) * 10, len(a4) WHERE a1 == "Buy" ORDER BY int(a2) DESCSELECT a.id, a.weight / 1000 AS weight_kgSELECT * ORDER BY random.random()- random sortSELECT len(a.vehicle_price) / 10, a2 WHERE int(a.vehicle_price) < 500 and a['Vehicle type'] in ["car", "plane", "boat"] limit 20- referencing columns by names from header and using Python's "in" to emulate SQL's "in"UPDATE SET a3 = 'NPC' WHERE a3.find('Non-playable character') != -1SELECT NR, *- enumerate records, NR is 1-basedSELECT * WHERE re.match(".*ab.*", a1) is not None- select entries where first column has "ab" patternSELECT a1, b1, b2 INNER JOIN ./countries.txt ON a2 == b1 ORDER BY a1, a3- example of join querySELECT MAX(a1), MIN(a1) WHERE a.Name != 'John' GROUP BY a2, a3- example of aggregate querySELECT *a1.split(':')- Using Python3 unpack operator to split one column into many. Do not try this with other SQL engines!
RBQL design principles and architecture
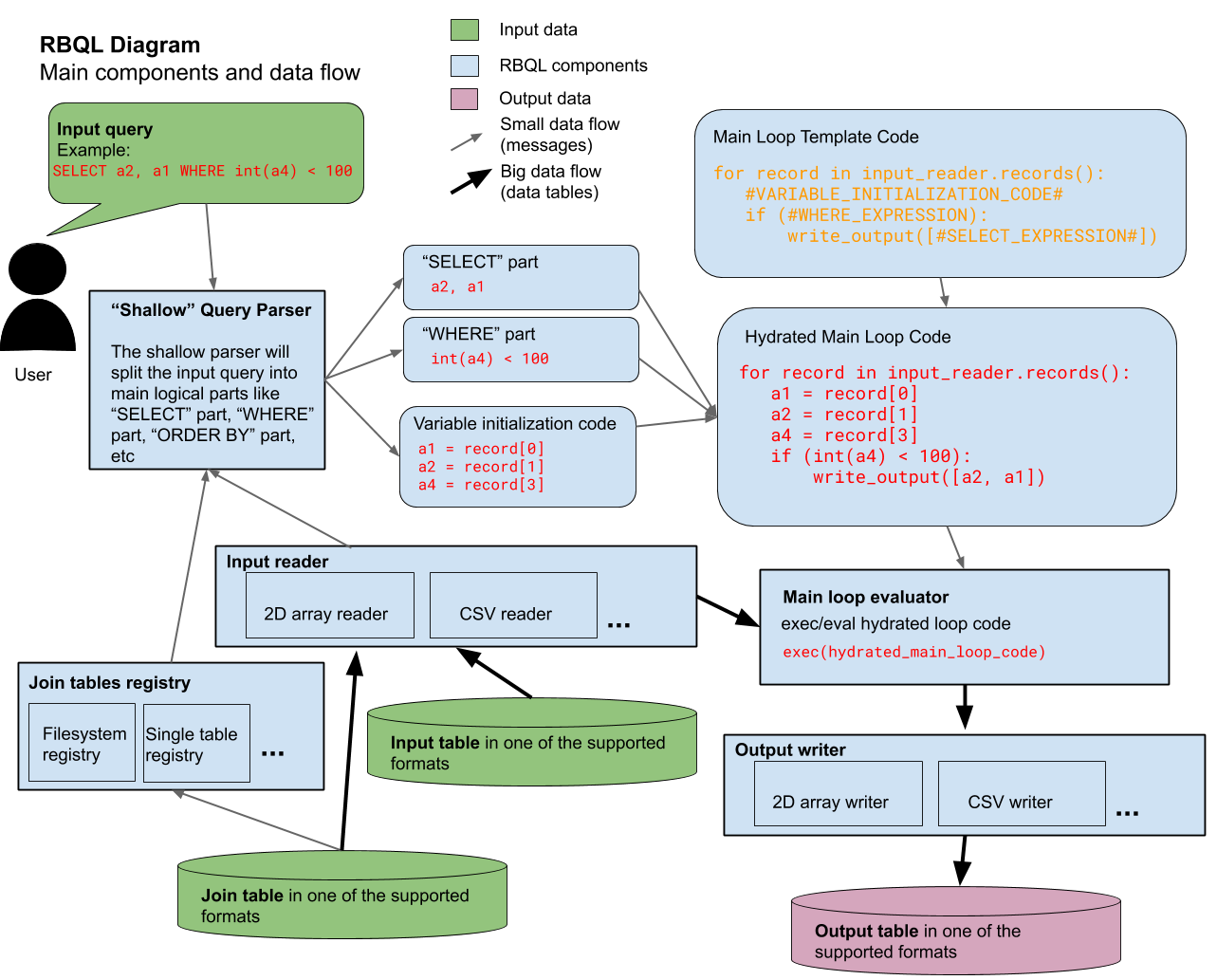
RBQL core idea is based on dynamic code generation and execution with exec and eval functions. Here are the main steps that RBQL engine performs when processing a query:
- Shallow parsing: split the query into logical expressions such as "SELECT", "WHERE", "ORDER BY", etc.
- Embed the expression segments into the main loop template code
- Execute the hydrated loop code
Here you can find a very basic working script (only 15 lines of Python code) which implements this idea: mini_rbql.py
The diagram below gives an overview of the main RBQL components and data flow:
Advantages of RBQL over traditional SQL engines
- Provides power and flexibility of general purpose Python and JS languages in relational expressions (including regexp, math, file system, json, xml, random and many other libraries that these languages provide)
- Can work with different data sources including CSV files, sqlite tables, native 2D arrays/lists (traditional SQL engines are usually tightly coupled with their databases)
- Result set of any query immediately becomes a first-class table on its own
- Supports both TOP and LIMIT keywords
- Provides additional NR (record number) variable which is especially useful for input sources where record order is well defined (such as CSV files)
- Supports input tables with inconsistent number of fields per record
- Allows to generate result sets with variable number of fields per record e.g. by using split() function and unpack operator (Python) / destructuring assignment (JS)
- UPDATE is a special case of SELECT query - this prevents accidental data loss
- No need to use FROM statement when the table name is defined by the context. This improves query typing speed and allows immediate autocomplete for variables inside SELECT statement (in traditional SQL engines autocomplete will not work until you write FROM statement, which goes after SELECT statement)
- SELECT, WHERE, ORDER BY, and other statements can be rearranged in any way you like
- Supports EXCEPT statement
- Provides a fully-functional client-side browser demo application
- Almost nonexistent entry barrier both for SQL users and JS/Python users
- Integration with popular text editors (VSCode, Vim, Sublime Text)
- Small, maintainable, dependency-free, eco-friendly and hackable code base: RBQL engine fits into a single file with less than 2000 LOC
Disadvantages of RBQL compared to traditional SQL engines
- Not suitable for transactional workload
- RBQL doesn't support nested queries, but they can be emulated with consecutive queries
- Number of tables in all JOIN queries is always 2 (input table and join table), use consecutive queries to join 3 or more tables
- Does not support HAVING statement
References
- RBQL: Official Site
- rbql-js library and CLI App for Node.js - npm
- Rainbow CSV extension with integrated RBQL in Visual Studio Code
- Rainbow CSV extension with integrated RBQL in Vim
- Rainbow CSV extension with integrated RBQL in Sublime Text 3
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rbql-0.30.2.tar.gz.
File metadata
- Download URL: rbql-0.30.2.tar.gz
- Upload date:
- Size: 45.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e7e58b1f03d36b7973a4c074e11c736a2e7aea5789ebc23dbb5b6fbd2e8dc396
|
|
| MD5 |
f58b730c962564ba8fb2f08f8086dce0
|
|
| BLAKE2b-256 |
705bc857513ed7bffd1767581d3b226d2bca8c0c88b5af64a1fed120d5cf422a
|
Provenance
The following attestation bundles were made for rbql-0.30.2.tar.gz:
Publisher:
publish-pypi.yml on mechatroner/RBQL
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
rbql-0.30.2.tar.gz -
Subject digest:
e7e58b1f03d36b7973a4c074e11c736a2e7aea5789ebc23dbb5b6fbd2e8dc396 - Sigstore transparency entry: 954373970
- Sigstore integration time:
-
Permalink:
mechatroner/RBQL@fea0bdeae4bd4728da5dff9af228c375c02ba16e -
Branch / Tag:
refs/heads/master - Owner: https://github.com/mechatroner
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@fea0bdeae4bd4728da5dff9af228c375c02ba16e -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file rbql-0.30.2-py3-none-any.whl.
File metadata
- Download URL: rbql-0.30.2-py3-none-any.whl
- Upload date:
- Size: 44.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
52afe1af0054509b9c968c0b015db11ca8b23b112ab48084bc73a716c6079ce6
|
|
| MD5 |
c3bdf7fac67f1e07544836d7b03cd6eb
|
|
| BLAKE2b-256 |
d278c13bd111fa4763169fb2af79680858b3f3e0ca9201e979ef0c81bb3c19d1
|
Provenance
The following attestation bundles were made for rbql-0.30.2-py3-none-any.whl:
Publisher:
publish-pypi.yml on mechatroner/RBQL
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
rbql-0.30.2-py3-none-any.whl -
Subject digest:
52afe1af0054509b9c968c0b015db11ca8b23b112ab48084bc73a716c6079ce6 - Sigstore transparency entry: 954373976
- Sigstore integration time:
-
Permalink:
mechatroner/RBQL@fea0bdeae4bd4728da5dff9af228c375c02ba16e -
Branch / Tag:
refs/heads/master - Owner: https://github.com/mechatroner
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@fea0bdeae4bd4728da5dff9af228c375c02ba16e -
Trigger Event:
workflow_dispatch
-
Statement type:







