Community analysis in bibliographical references

Project description
RefCliq
This package is a full rewrite of Neal Caren's RefCliq. The objective is the same, to analyse clustering of co-cited publications using graph clustering. Note that this package also operates over the co-citation network, not the citation network.
The main differences are:
- More robust article matching, based on all available information (so two articles from the same author/year in the same journal don't get clumped together if they also have the DOI or title)
- Robust string matching, to catch spelling errors (using fuzzywuzzy)
- Degree centrality instead of betweenness centrality.
- Geocoding support, where the affiliation field is used to map the location of the citing authors. This requires a Google maps API key, which may require payment. More information about Google geocoding API. The guide on how to get a key is available here.
Important: The input bibliography files must be from Web of Science / Web of Knowledge, including the Cited references field. Otherwise the references section might be missing or with a different format and this will not work.
Really Important: Most .bib files include information that was manually filled by different people using different ideas/notations/conventions. This package will work for most cases, but not all. Some manual editing of the .bib file might be required.
If you run into an error that you believe should be fixed in the code, or if you have a suggestion for a new feature, please open a new issue here. Be sure to check the existing issues first, be as descriptive as possible and include examples of the error and detailed instructions on how to replicate it.
Installation:
Only python 3 is supported, after all python 2 is set to retire very soon.
pip install refcliq
All the dependencies will be automatically installed.
It is a good idea to run a small .bib file to make sure every step of the script works before running large datasets (see the FAQ at the end).
Usage:
This package contains two scripts:
- rc_cluster.py: Computes the clustering and saves the result in a json file.
- rc_vis.py: Starts the visualization interface for a pre-computed file.
Generating the results
Running rc_cluster.py with a '-h' argument will display the help:
$ rc_cluster.py -h
usage: rc_cluster.py [-h] [-o OUTPUT_FILE] [--cites CITES] [-k GOOGLE_KEY]
[--graphs]
files [files ...]
positional arguments:
files List of .bib files to process
optional arguments:
-h, --help show this help message and exit
-o OUTPUT_FILE Output file to save, defaults to 'clusters.json'.
--cites CITES Minimum number of citations for an article to be included,
defaults to 2.
-k GOOGLE_KEY Google maps API key. Necessary for precise geocoding.
--graphs Saves graph drawing information for the cluster.
- files: The .bib files to be used. It can be one file (
a.bib), a list of files (a.bib b.bib), or wildcards (*.bib). - -o (output_file): The name to be used for the results file. The 'json' extension is automatically added. If not provided, defaults to
clusters.json. - --cites: Minimum number of citations for an article be included. While this can be changed in the interactive interface, increasing this number speeds up the processing time and reduces the memory requirements. Increase this parameter if the processing crashes / runs out of memory. Further, with an argument of
1, all the works cited by only one article will present as a densely connected cluster, which may hinder a bit the interpretation, so it defaults to2. - --graphs: Enables the visualization of citation graphs in the interface. *Greatly increases the size of the results file. Only clusters with less than 50 articles will be displayed in the interface.
- -k: The Google API key. This key is necessary for geocoding and may require payment. Please check Google's billing calculator. While this package tries to be smart and reduce the geocoding calls, it is reasonably safe to assume one call for each author of each publication as an approximation of an upper bound on the number of calls. Monitor your usage carefully, this package is provided as is and the authors cannot be help responsible for any billing issues with Google.
Without the geocoding key the countries are still identified and present in the exported .tsv files, but the map will not be displayed in the interface.
Visualizing the results
Assuming that the results file is named clusters.json:
$ rc_vis.py clusters.json
A new tab will be open on the default browser that will look like this (with geocoding enabled):
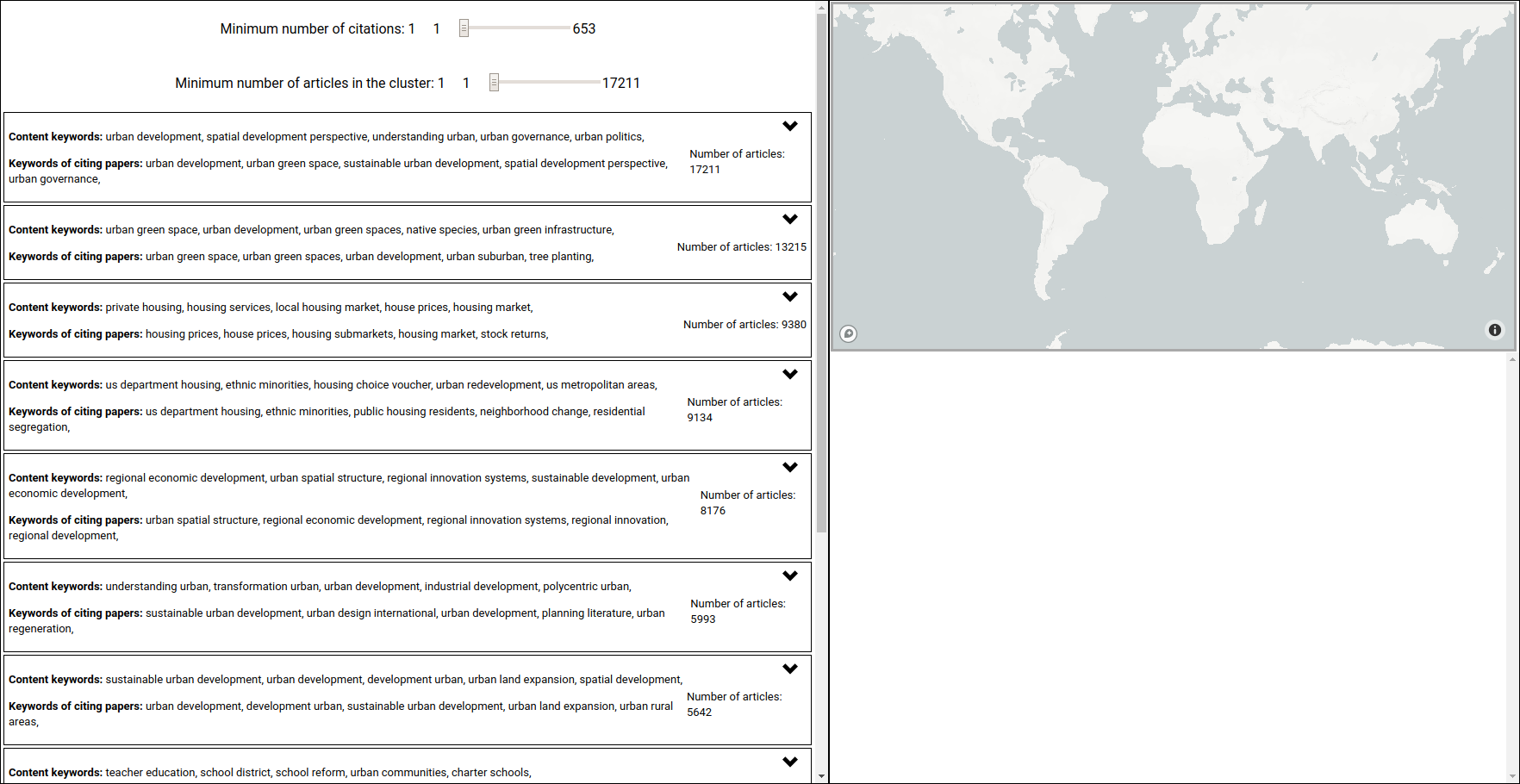
The interface is divided in two panels, the cluster visualisation on the left and the citation details on the right.
Clusters: Each box on the left represents one cluster found by the louvain method. In its "collapsed" visualisation, it displays the number of articles in this cluster, the Content keywords directly computed from the available abstracts of the articles in this cluster, and the Keyworkds of citing papers, representing they keywords computed from the papers that cite the papers in this cluster. The keywords are computed using sklearn, with only tf enabled.
The two sliders on the top left control what is displayed, hiding works with fewer citations than the value of the first slider and clusters with fewer works than the value of the second. This is done without reprocessing the clustering.
Clicking on the chevron on the top right part of the cluster box will "expand" that cluster, looking like this (after clicking also on the first citation):
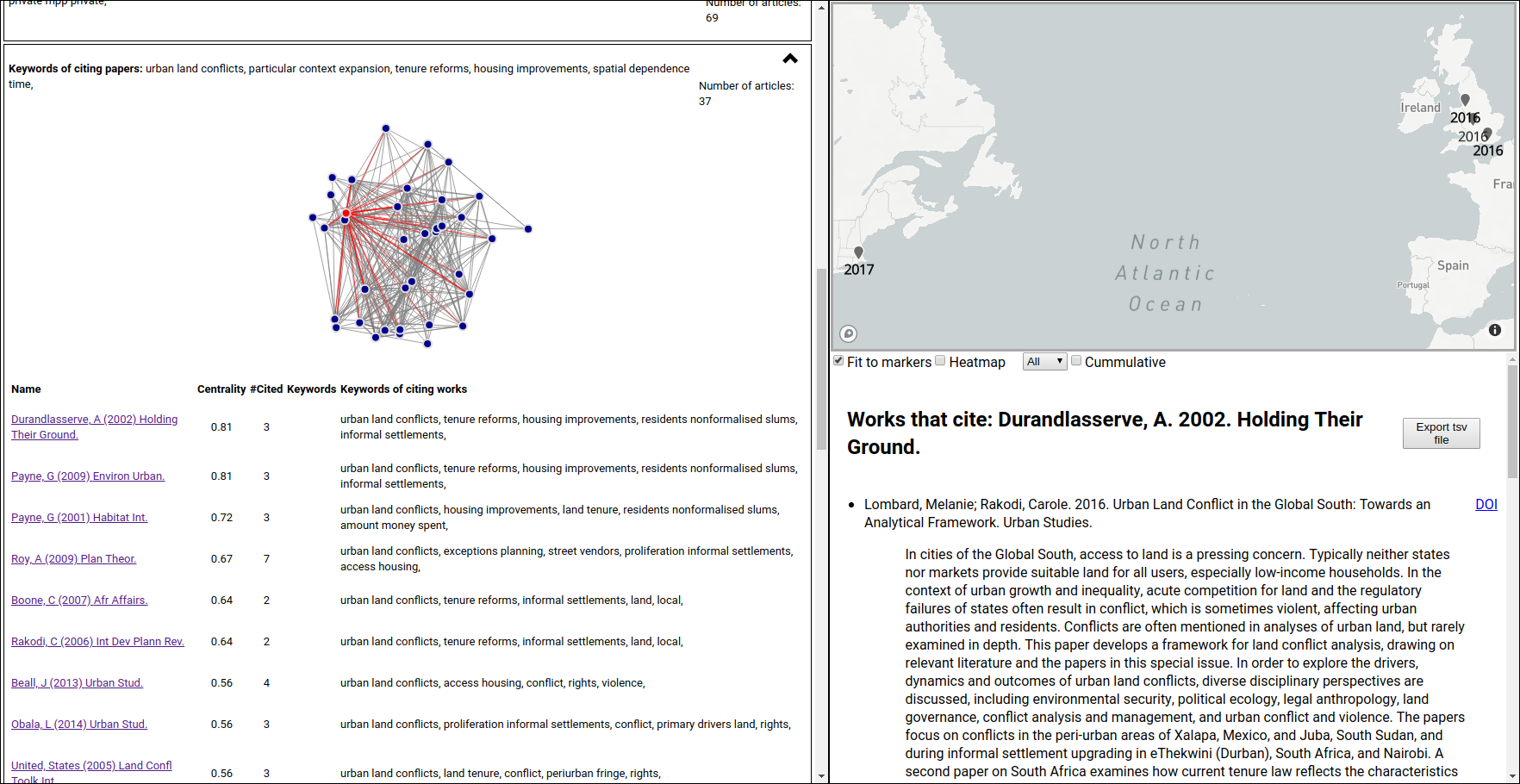
The expanded version lists all articles in that cluster, with clickable links that activate the panel on the right of the interface that displays the citing details for that citation, along with the network centrality measure (degree_centrality implemented using networkx), citation count, article keywords (when the abstract is available), and the keywords of the citing works.
Centrality: This image is also showing the network plot, with the first work in the list highlighted. This plot is not included by default (and only available for clusters with fewer than 50 works), but it is helpful to understand the centrality measure. Since we adopted degree centrality, this number is the ratio between the number of existing connections of this work and the number of possible connections, it represents the fraction of the cluster that is cited when this work is cited. A centrality of 1 means that every time any article in this cluster is cited, that work is also cited. In this case, the work "Durandlasserve, A. 2002. Holding Their Ground." has only three citations, but has a centrality measure of 0.81 meaning that it is connected (was cited concomitantly) to 81% of the works in this cluster. The connections are highlighted in red in the network plot.
Citation details: This panel is divided in two parts: the map on the top (if geocoding is enabled by providing a Google geocoding key) and the list of citing works. This list can be exported as a tab separated values file by clicking on the Export tsv file button. The DOI link for each work is also provided, if that information is available.
The geocoded information can be displayed as markers or as a heatmap. To reduce the impact of papers with several authors on the heatmap, the log of the number of authors is used. The information on the map can be filtered to include only a single year or all years up to the selected year (using the cumulative checkbox). Unchecking the Fit to markers box will keep the map from changing the viewport (useful to do comparisons).
FAQ
-
I don't need geocoding, should I use the original version? or I ran my .bibs in the original version and I got different results!
This project started as a fork of the original version, aiming only to add the authors' addresses information, I'm not sure if any lines from the original version are present in this project now. Python 2 and coding methodology aside (and the whole try/except misuse), since the original version only considers the first author, year, and the title/journal, it merges things that should not be merged (two papers of the same author in the same journal and year). Further, the cavalier approach to text processing silently loses works, even whole files (.bib).
-
Why two scripts?
I chose to store the processed information as a json, instead of generating a bunch of static pages, because then I can fully use react and make an interactive visualization interface. Further, if/when I decide to change the interface, the results don't need to be processed again (depending on the feature), which is handy if you ran for a few hundred files and has around a million works in there. And if someone wants to use the processed result for something else, the json is easy to load and parse.
-
I don't want to get a Google key, is there any way to draw a map?
The exported .tsv files contain country information as a field. It should be possible to break that field and use Excel or Google docs map drawing features to do a choropleth map. It is a bit tricky to match the country names provided to actual countries, which is why I didn't implement that yet. Pull requests more than welcome for this.
-
The sliders are too finicky! It's hard to select precisely a number.
Once the slider is selected, you can use the left/right arrows in the keyboard to do unitary increments. On mobile, well, that's trickier.
-
What is this
cache.jsonfile that appeared in my folder?To minimize the calls to Google's geocoding API, the script caches the results, so no duplicate calls are made, even in different runs. If you don't want start from zero, download my current cache.json here.
-
The first time I'm running it I get
Can't find model 'en_core_web_sm'., then it crashes.Just run the command again and it will work. It needs to download the English language model for SpaCy, but the script doesn't automatically refresh the installed packages. Pull requests welcome.
-
Why not use nominatim for geocoding?
We actually used it at the start of the project because it was free, but it missed several addresses (like
Leics, England) and it geocodedToronto, Ontario, Canadaas a point about 50km north of Victoria, BC, in the middle of the forest. Google geocoding can get expensive, but it actually works. -
Why tab separated values (.tsv) instead of comma separated values (.csv) for the exported citations?
While the specification of the csv format is rather robust, there are some atrocious implementations of it in the wild. By using a character that is not present in the values, the parsing is easier and less error-prone.
-
Why degree centrality instead of betweenness_centrality as the original RefCliq?
Consider the following graph:
Betweenness centrality measures how many shortest paths of the graph pass through a given node. In this case, all paths connecting nodes from the left side of the red node to nodes on the right side will pass through the red node, so the betweenness centrality of the red node will be rather high (
~0.57), which is not exactly what we want to measure. The degree centrality for this node is2/8, because it is connected to two of the possible eight nodes in the network. This is a rather extreme example, which likely would be cut in two clusters by Louvain (depending on the co-citation count).Further, degree centrality is much faster to compute.
-
The time estimates for the citation network - Cited-References part of the processing are wrong/consistently increasing.
That is the trickiest part of the code, where given a very incomplete reference (parts of the name of the first author, year, and something related to the title/journal, maybe a DOI), the code has to decide if that work is already on the citation graph or not. Since the graph keeps growing, this search will get progressively slower. Robust string comparison is slow, but it is a somewhat reliable way of properly matching the works, even when DOIs are present, because the same work can be associated with multiple DOIs, or someone might have written the name of the company in the DOI field. Manually filled fields. And typos.
-
How do I save a map displayed on the interface to use in my blog/paper/etc ?
Print screen. Yes, a rather archaic way, but it works and it doesn't require any complicated implementation on my part. It helps if you "zoom in" / increase the resolution on the browser (Ctrl and + on Chrome) to make the map bigger. Pull requests on that feature are welcome.

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file refcliq-0.1.12.tar.gz.
File metadata
- Download URL: refcliq-0.1.12.tar.gz
- Upload date:
- Size: 1.5 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.23.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.46.0 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b434c45b36aa90b31d9ef7740762a42c93adab7b89213f177aa8de74b0470140
|
|
| MD5 |
b26c5c1484276638ea2d8528ce58c736
|
|
| BLAKE2b-256 |
893f4827eb894699634da6a7c952e57f0af48e000cbb1a0a5b66da61b3ce2298
|
File details
Details for the file refcliq-0.1.12-py3-none-any.whl.
File metadata
- Download URL: refcliq-0.1.12-py3-none-any.whl
- Upload date:
- Size: 1.5 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.23.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.46.0 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4c4ec3918ddcbad7d4819a8a45c244759f672c031420a03f4ad9ec4cb4c2d87b
|
|
| MD5 |
ea02ffdab9acab850c2e2704776383e7
|
|
| BLAKE2b-256 |
e03c5a8539eda7b37fbf37ab1e60459d0b1ca26c9a608b69cbe302917155f2f6
|







