A collection of RL algorithms written in JAX.

Project description
WARNING: Rljax is currently in a beta version and being actively improved. Any contributions are welcome :)
Rljax
Rljax is a collection of RL algorithms written in JAX.
Setup
You can install dependencies simply by executing the following. To use GPUs, CUDA (10.0, 10.1, 10.2 or 11.0) must be installed.
pip install https://storage.googleapis.com/jax-releases/`nvcc -V | sed -En "s/.* release ([0-9]*)\.([0-9]*),.*/cuda\1\2/p"`/jaxlib-0.1.55-`python3 -V | sed -En "s/Python ([0-9]*)\.([0-9]*).*/cp\1\2/p"`-none-manylinux2010_x86_64.whl jax==0.2.0
pip install -e .
If you don't have a GPU, please execute the following instead.
pip install jaxlib==0.1.55 jax==0.2.0
pip install -e .
If you want to use a MuJoCo physics engine, please install mujoco-py.
pip install mujoco_py==2.0.2.11
Algorithm
Currently, following algorithms have been implemented.
| Algorithm | Action | Vector State | Pixel State | PER[11] | D2RL[15] |
|---|---|---|---|---|---|
| PPO[1] | Continuous | :heavy_check_mark: | - | - | - |
| DDPG[2] | Continuous | :heavy_check_mark: | - | :heavy_check_mark: | :heavy_check_mark: |
| TD3[3] | Continuous | :heavy_check_mark: | - | :heavy_check_mark: | :heavy_check_mark: |
| SAC[4,5] | Continuous | :heavy_check_mark: | - | :heavy_check_mark: | :heavy_check_mark: |
| SAC+DisCor[12] | Continuous | :heavy_check_mark: | - | - | :heavy_check_mark: |
| TQC[16] | Continuous | :heavy_check_mark: | - | :heavy_check_mark: | :heavy_check_mark: |
| SAC+AE[13] | Continuous | - | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| SLAC[14] | Continuous | - | :heavy_check_mark: | - | :heavy_check_mark: |
| DQN[6] | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
| QR-DQN[7] | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
| IQN[8] | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
| FQF[9] | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
| SAC-Discrete[10] | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
Example
All algorithms can be trained in a few lines of code.
Getting started
Here is a quick example of how to train DQN on CartPole-v0.
import gym
from rljax.algorithm import DQN
from rljax.trainer import Trainer
NUM_AGENT_STEPS = 20000
SEED = 0
env = gym.make("CartPole-v0")
env_test = gym.make("CartPole-v0")
algo = DQN(
num_agent_steps=NUM_AGENT_STEPS,
state_space=env.observation_space,
action_space=env.action_space,
seed=SEED,
batch_size=256,
start_steps=1000,
update_interval=1,
update_interval_target=400,
eps_decay_steps=0,
loss_type="l2",
lr=1e-3,
)
trainer = Trainer(
env=env,
env_test=env_test,
algo=algo,
log_dir="/tmp/rljax/dqn",
num_agent_steps=NUM_AGENT_STEPS,
eval_interval=1000,
seed=SEED,
)
trainer.train()
MuJoCo(Gym)
I benchmarked my implementations in some environments from MuJoCo's -v3 task suite, following Spinning Up's benchmarks (code). In TQC, I set num_quantiles_to_drop to 0 for HalfCheetath-v3 and 2 for other environments. Note that I benchmarked with 3M agent steps, not 5M agent steps as in TQC's paper.
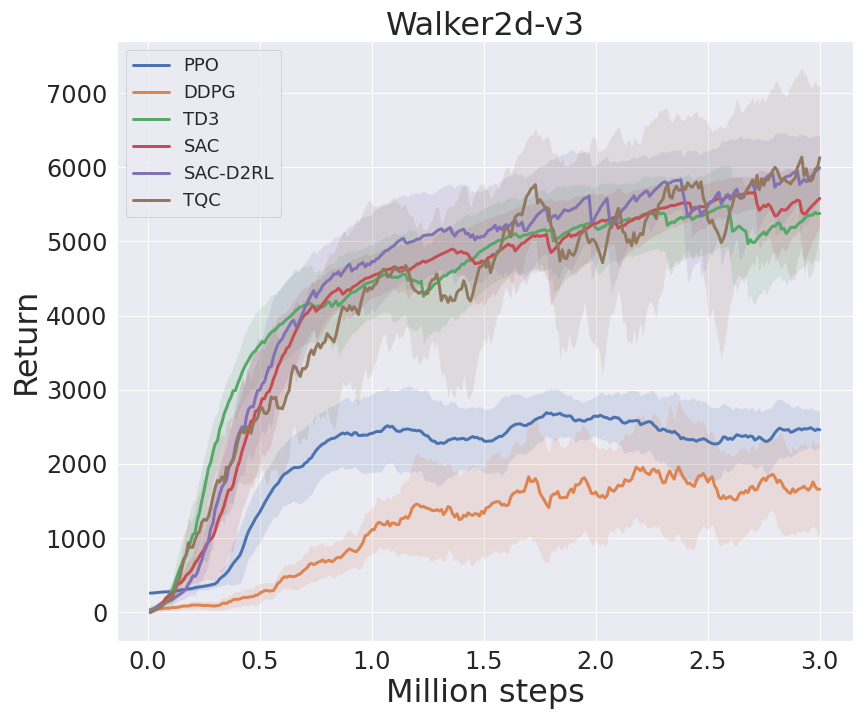
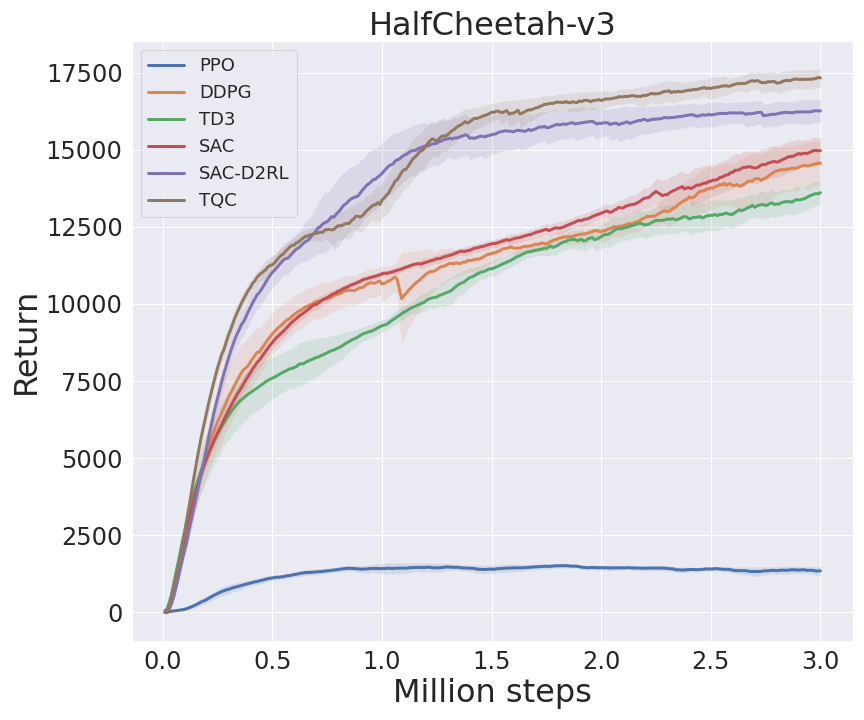
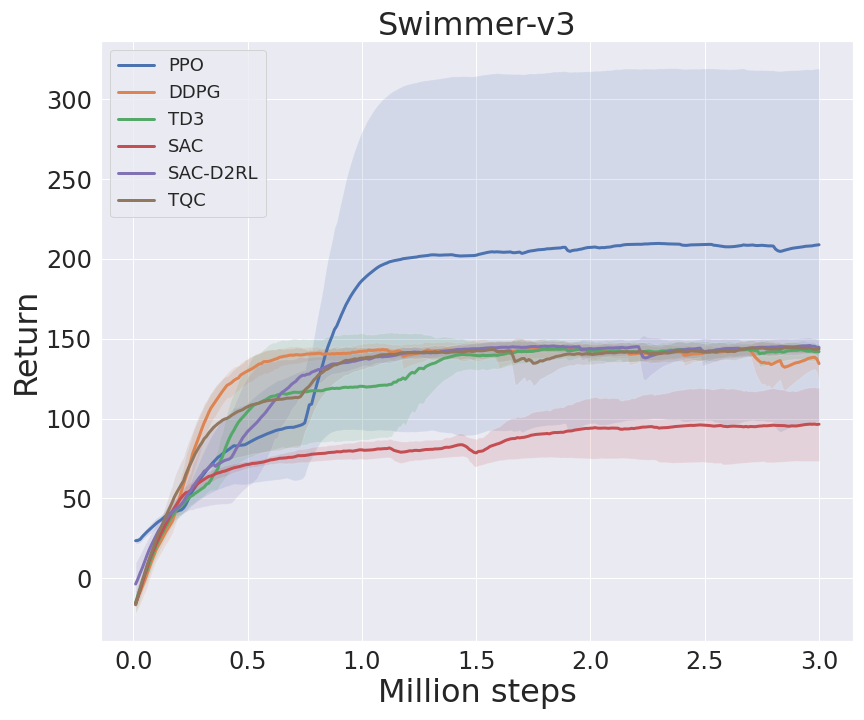
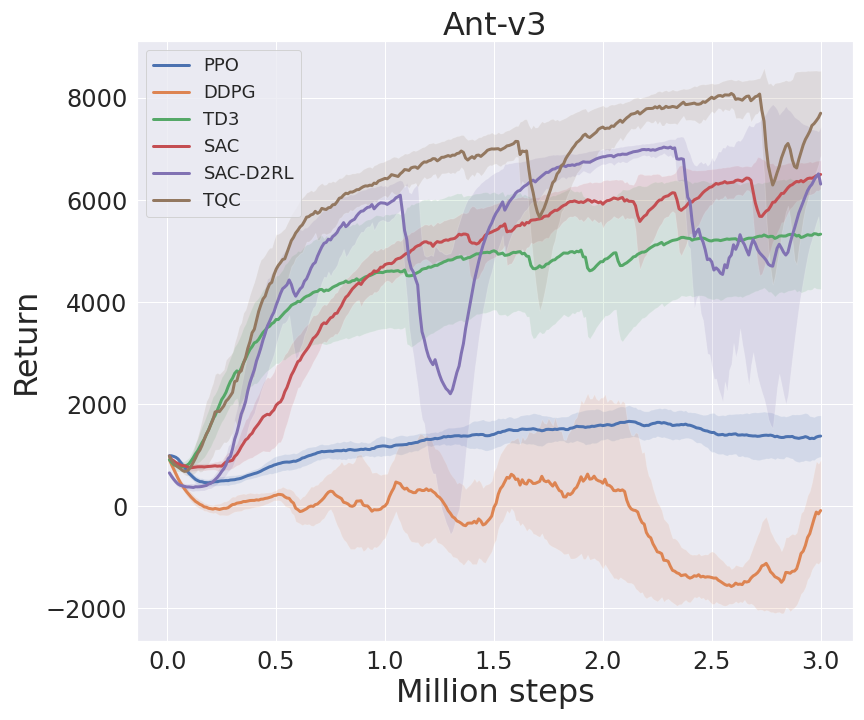
DeepMind Control Suite
I benchmarked SAC+AE and SLAC implementations in some environments from DeepMind Control Suite (code). Note that the horizontal axis represents the environment step, which is obtained by multiplying agent_step by action_repeat. I set action_repeat to 4 for cheetah-run and 2 for walker-walk.
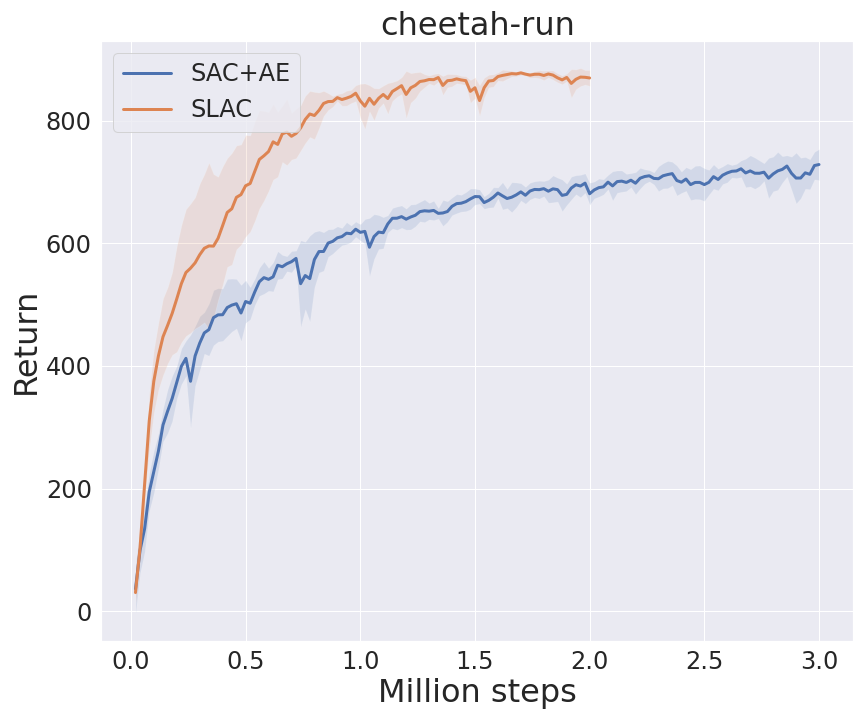
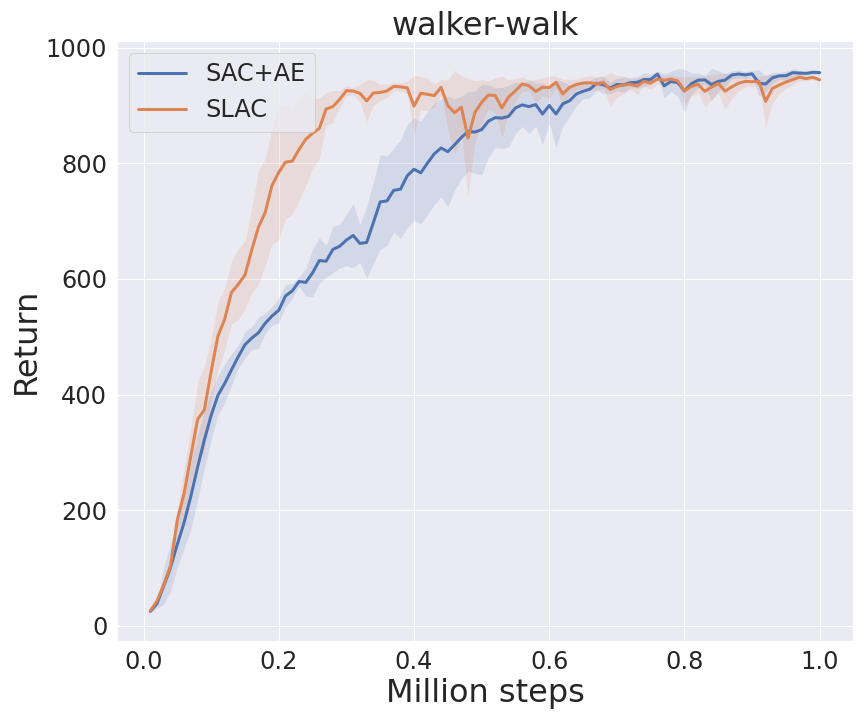
Atari(Arcade Learning Environment)
I benchmarked SAC-Discrete implementation in MsPacmanNoFrameskip-v4 from the Arcade Learning Environment(ALE) (code). Note that the horizontal axis represents the environment step, which is obtained by multiplying agent_step by 4.
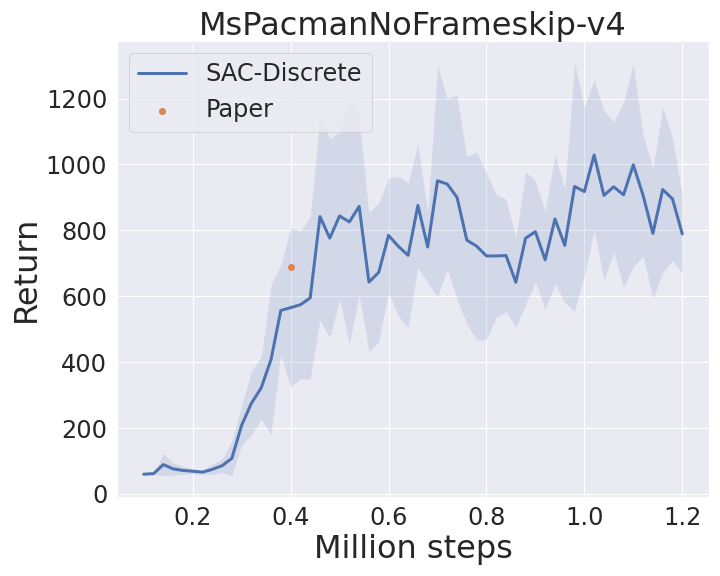
Reference
[1] Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
[2] Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015).
[3] Fujimoto, Scott, Herke Van Hoof, and David Meger. "Addressing function approximation error in actor-critic methods." arXiv preprint arXiv:1802.09477 (2018).
[4] Haarnoja, Tuomas, et al. "Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor." arXiv preprint arXiv:1801.01290 (2018).
[5] Haarnoja, Tuomas, et al. "Soft actor-critic algorithms and applications." arXiv preprint arXiv:1812.05905 (2018).
[6] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." nature 518.7540 (2015): 529-533.
[7] Dabney, Will, et al. "Distributional reinforcement learning with quantile regression." Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[8] Dabney, Will, et al. "Implicit quantile networks for distributional reinforcement learning." arXiv preprint. 2018.
[9] Yang, Derek, et al. "Fully Parameterized Quantile Function for Distributional Reinforcement Learning." Advances in Neural Information Processing Systems. 2019.
[10] Christodoulou, Petros. "Soft Actor-Critic for Discrete Action Settings." arXiv preprint arXiv:1910.07207 (2019).
[11] Schaul, Tom, et al. "Prioritized experience replay." arXiv preprint arXiv:1511.05952 (2015).
[12] Kumar, Aviral, Abhishek Gupta, and Sergey Levine. "Discor: Corrective feedback in reinforcement learning via distribution correction." arXiv preprint arXiv:2003.07305 (2020).
[13] Yarats, Denis, et al. "Improving sample efficiency in model-free reinforcement learning from images." arXiv preprint arXiv:1910.01741 (2019).
[14] Lee, Alex X., et al. "Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model." arXiv preprint arXiv:1907.00953 (2019).
[15] Sinha, Samarth, et al. "D2RL: Deep Dense Architectures in Reinforcement Learning." arXiv preprint arXiv:2010.09163 (2020).
[16] Kuznetsov, Arsenii, et al. "Controlling Overestimation Bias with Truncated Mixture of Continuous Distributional Quantile Critics." arXiv preprint arXiv:2005.04269 (2020).


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rljax-0.0.4.tar.gz.
File metadata
- Download URL: rljax-0.0.4.tar.gz
- Upload date:
- Size: 40.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.6.1 requests/2.24.0 setuptools/49.6.0.post20200925 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4a88be9f145dcaa22e00546beca92bc47c9ee469dfef1a134937f7256b65034b
|
|
| MD5 |
97d4cbb4c7f0feb23edc09ee13bad1d9
|
|
| BLAKE2b-256 |
c1a36b5b4c102c10f7eeb1fa036ec603e1fc99825150c7d42b8680d8c58f3ce3
|
File details
Details for the file rljax-0.0.4-py2.py3-none-any.whl.
File metadata
- Download URL: rljax-0.0.4-py2.py3-none-any.whl
- Upload date:
- Size: 88.7 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.6.1 requests/2.24.0 setuptools/49.6.0.post20200925 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
532d8217c9a4fe4031b9091b9ee76cd0b3b978e5605c7a33bae72ab6a0787cd1
|
|
| MD5 |
2358ab5228f7a7603ebfb2234bbc2d0b
|
|
| BLAKE2b-256 |
176fde1ca717ee25f176cf28ba3b9f8f8f6afc233fb62045c569eece7e452de1
|







