S3-as-a-datastore is a library that lives on top of botocore and boto3, as a way to use S3 as a key-value datastore instead of a real datastore

Project description
S3 As A Datastore (S3aaDS)
S3-as-a-datastore is a library that lives on top of botocore and boto3, as a way to use S3 as a key-value datastore instead of a real datastore
DISCLAIMER: This is NOT a real datastore, only the illusion of one. If you have remotely high I/O, this is NOT the library for you.
Motivation
S3 is really inexpensive compared to Memcache, or RDS.
For example, this is the RDS cost
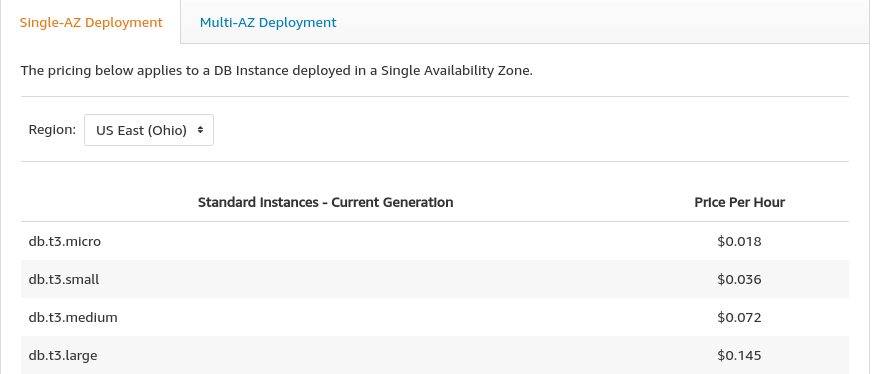
while this is S3 cost
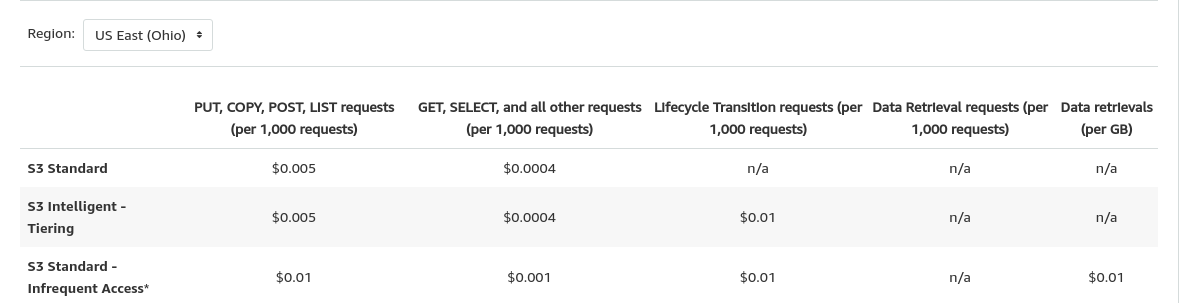
If a service doesn't have a lot of traffic, keeping up a RDS deployment is wasteful because it stands idle but incurring cost. S3 doesn't have that problem. For services that has low read/writes operations, or only has CRD without the U (if you don't know what that means, read CRUD), saving things in S3 gets similar results. As long as data isn't getting upgrade, only written and read, S3 can be used. However, Writing to S3 requires a lot of documentation reading if you're not used to it. This library is an interface to communication with S3 like a very pseudo-ORM way.
Installation
pip3 install s3aads
or
pip3 install s3-as-a-datastore
Idea
The main idea is a database is mapped to a bucket, and a table is the top level "folder" of s3. The rest of nested "folders" are columns. Because the way buckets work in S3, they must be unique for all S3 buckets. This also mean the combination of keys must be unique
NOTE: There are quotations around "folder" because files in a S3 bucket are flat, and there aren't really folders.
Example
Database: joeyism-test
Table: daily-data
id | year | month | day | data
------------------------------
1 | 2020 | 01 | 01 | ["a", "b"]
2 | 2020 | 01 | 01 | ["c", "d"]
3 | 2020 | 01 | 01 | ["abk20dj3i"]
is mapped to
joeyism-test/daily-data/1/2020/01/01 -> ["a", "b"]
joeyism-test/daily-data/2/2020/01/01 -> ["c", "d"]
joeyism-test/daily-data/3/2020/01/01 -> ["abk20dj3i"]
but it can be called with
from s3aads import Table
table = Table(name="daily-data", database="joeyism-test", columns=["id", "year", "month", "day"])
table.select(id=1, year=2020, month="01", day="01") # b'["a", "b"]'
table.select(id=2, year=2020, month="01", day="01") # b'["c", "d"]'
table.select(id=3, year=2020, month="01", day="01") # b'["abk20dj3i"]'
Usage
Example
from s3aads import Database, Table
db = Database("joeyism-test")
db.create()
table = Table(name="daily-data", database=db, columns=["id", "year", "month", "day"])
table.insert(id=1, year=2020, month="01", day="01", data=b'["a", "b"]')
table.insert(id=2, year=2020, month="01", day="01", data=b'["c", "d"]')
table.insert(id=2, year=2020, month="01", day="01", data=b'["abk20dj3i"]')
table.select(id=1, year=2020, month="01", day="01") # b'["a", "b"]'
table.select(id=2, year=2020, month="01", day="01") # b'["c", "d"]'
table.select(id=3, year=2020, month="01", day="01") # b'["abk20dj3i"]'
table.delete(id=1, year=2020, month="01", day="01")
table.delete(id=2, year=2020, month="01", day="01")
table.delete(id=3, year=2020, month="01", day="01")
API
Database
Database(name)
- name: name of the table
Properties
tables: list of tables for that Database (S3 Bucket)
Methods
create(): Create the database (S3 Bucket) if it doesn't exist
get_table(table_name) -> Table: Pass in a table name and returns the Table object
drop_table(table_name): Fully drops table
Class methods
list_databases(): List all available databases (S3 Buckets)
Table
Table(name, database, columns=[])
- name: name of the table
- database: Database object. If a string is passed instead, it'll attempt to fetch the Database object
- columns (default: []): Table columns
Properties
keys: list of all keys in that table. Essentially, list the name of all files in the folder
objects: list of all objects in that table. Essentially, list the keys but broken down so it can be selected by column name
Full Param Methods
The following methods require all the params to be passed in order for it to work.
delete(**kwargs): If you pass the params, it'll delete that row of data
insert(data:bytes, metadata:dict={}, **kwargs): If you pass the params and value for data, it'll insert that row of bytes data.
datais the data to save, inbytesmetadata(optional) is used if you want to pass in extra data that is related to S3. Available params can be found in the boto3 docs
insert_string(data:string, metadata:dict={}, **kwargs): If you pass the params and value for data, it'll insert that row of string data
datais the data to save, instrmetadata(optional) is used if you want to pass in extra data that is related to S3. Available params can be found in the boto3 docs
select(**kwargs) -> bytes: If you pass the params, it'll select that row of data and return the value as bytes
select_string(**kwargs) -> string: If you pass the params, it'll select that row of data and return the value as a string
Partial Param Methods
The following methods can work with partial params passed in.
query(**kwargs) -> List[Dict[str, str]]: If you pass the params, it'll return a list of params that is availabe in the table
Key Methods
to_key(self, **kwargs) -> str: When you pass the full kwargs, it'll return the key
delete_by_key(key): If you pass the full key/path of the file, it'll delete that row/file
insert_by_key(key, data: bytes): If you pass the full key/path of the file and the data (in bytes), it'll insert that row/file with the data
select_by_key(key) -> bytes: If you pass the full key/path of the file, it'll select that row/file and return the data
query_by_key(key="", sort_by=None) -> List[str]: If you pass the full or partial key/path of the file, it'll return a list of keys that matches the pattern
sort_by: Possible values are Key, LastModified, ETag, Size, StorageClass
Methods
distinct(columns: List[str]) -> List[Tuple]: If you pass a list of columns, it'll return a list of distinct tuple combinations based on those columns
random_key() -> str: Returns a random key to data
random() -> Dict: Returns a set of params and data of a random data
count() -> int: Returns the number of objects in the table
<first_column_name>s() -> List[str]: Taking the name of the first column, returns a list of unique values.
<n_column_name>s() -> List[str]: Taking the name of the Nth column, returns a list of unique values.
filter_objects_by_<column_name>(val: str) -> List[object]: This method exists for each column name. It allows the user to provide a string input, and output a list of objects which are the keys to the table
filter_objects_by(col1=val1, col2=val2, ...) -> List[object]: Similar to filter_objects_by_<column_name>(val: str), except instead of filtering for one, the method can filter for multiple columns and values
- For example, a table with columns
["id", "name"]will have the methodtable.ids()which will return a list of unique ids
copy(key) -> Copy: Returns a Copy object
copy(key).to(table2, key, **kwargs) -> None: Copies from one table to another. kwargs details can be seen in boto3 docs
- Example:
from s3aads import Table
table1 = Table("table1", database="db1", columns=["a"])
table2 = Table("table2", database="db2", columns=["a"])
key = table1.keys[0]
table1.copy(key).to(table2, key)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file s3-as-a-datastore-2.13.6.tar.gz.
File metadata
- Download URL: s3-as-a-datastore-2.13.6.tar.gz
- Upload date:
- Size: 10.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.3 readme-renderer/29.0 requests/2.25.1 requests-toolbelt/0.9.1 urllib3/1.26.9 tqdm/4.64.0 importlib-metadata/3.10.1 keyring/22.3.0 rfc3986/1.5.0 colorama/0.4.3 CPython/3.6.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
00a4d298d86fc5cf4181c85c45306ce4089da465eefbcf0ecb174dc552986b38
|
|
| MD5 |
d86d78914a4463e017d89e0d1cc21032
|
|
| BLAKE2b-256 |
37a95d61eb1a83860ed50e761ebf2f92ad26405b731357221acc85eed5faa3da
|







