Hyper parameters search for scikit-learn components using Microsoft NNI

Project description
scikit-nni



Hyper parameters search for scikit-learn components using Microsoft NNI
Free software: Apache Software License 2.0
Documentation: https://scikit-nni.readthedocs.io.
Introduction
Microsoft NNI (Neural Network Intelligence) is a toolkit to help users run automated machine learning (AutoML) experiments. The tool dispatches and runs trial jobs generated by tuning algorithms to search the best neural architecture and/or hyper-parameters in different environments like local machine, remote servers and cloud.
Read and explore more about Microsoft NNI here - https://github.com/microsoft/nni
scikit-nni is a helper tool (and a package) that :
generates the configuration (config.yaml & search-space.json) required for NNI
automatically builds the scikit-learn pipelines based on your specification and becomes an experiment/trial code for Microsoft NNI to run.
What value does this tool add to Microsoft NNI ?
First note that this tool is specifically written to only help with scikit-learn pipelines and to tune classification algorithms. In near future, I would add the support for regression algorithms as well.
Now when you use Microsoft NNI you need to specify (at minimum) 3 files :
A search space (json) file that contains the parameters that you want to search/tune.
- Your code/experiment. In your experiment code, you perform these tasks in sequence :
Request for the parameters from NNI server
Create your model using these parameters
Fit your model
Score your model
Report the score to NNI server.
a configuration file where you specify the tuner, which mode to use to run, path to your code file and search space file.
scikit-nni eliminiates the second step i.e. it builds the scikit pipelines, request NNI server for parameters and also report back the score of your model. It also simplifies (in IMHO) the input specification by only requiring one file instead of 3.
Sounds interesting ? Then read the documentation below, install scikit-nni, and more importantly provide feedback if it does not work for you and/or you think it can be improved.
Features
Hyperparameters search for scikit-learn pipelines using Microsoft NNI
No code required to define the pipelines
Built-in datasource reader for reading npz files for classification
Support for using custom datasource reader
Single configuration file to define NNI configuration and search space
I plan to add more datasource readers (e.g. CSV, libSVM format files etc). Contributions are always welcome !
Usage
Step 1 - Write a specification file
The specification file is essentially a YAML file but with extension .nni.yml
There are 4 parts (sections) in the configuration file.
Datasource Section
This is where you will specify the (python) callable that sknni would be invoking to get the training and test dataset.
The callable must return two values where each value is a tuple of two items. The first tuple consists of training data (X_train, y_train) and the second tuple consists of test data (X_test, y_test).
An example callable would look like this:
import numpy as np
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
class ACustomDataSource(object):
def __init__(self):
pass
def __call__(self, test_size:float=0.25):
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, random_state=99, test_size=test_size)
return (X_train, y_train), (X_test, y_test)
In the above example, the callable generates the train and test dataset. The callable can even have paramaters for e.g. in this example you could optionally pass the fraction of data to be used for testing.
Now let’s see how you would add it in the specification file.
# Datasource is how you specify which callable
# sknni will invoke to get the data
dataSource:
reader: yourmodule.ACustomDataSource
params:
test_size: 0.30Make sure that during the exeuction of the experiment your datasource (i.e. in this case yourmodule.ACustomDataSource) is available in the PYTHONPATH.
Here is an additional example showing the usage of a built-in datasource reader
dataSource:
reader: sknni.datasource.NpzClassificationSource
params:
dir_path: /Users/ksachdeva/Desktop/Dev/myoss/scikit-nni/examples/data/multiclass-classificationNpzClassificationSource expects that at dir_path you have two folders - train and test. In each folder are the files named as 0.npz, 1.npz etc. Every file contains that features for that corresponding class.
The repository contains two such datasources to do binary and multiclass classifications.
Pipline definition Section
Below is an example of this type of section. You simply specify the list of steps of your scikit-learn Pipeline.
Note - The sequence of steps is very important.
What you MUST ensure is that the full qualified name of your scikit-learn preprocessors, transformers and estimators is correctly specified & spelled. sknni uses reflection and introspection to create the instances of these components so if you have a typo in the names and/or they are not available in your PYTHONPATH you will get an error at experiment execution time.
sklearnPipeline:
name: normalizer_svc
steps:
normalizer:
type: sklearn.preprocessing.Normalizer
classArgs:
norm: l2
svc:
type: sklearn.svm.SVCIn above example, there are 2 steps. The first step is to normalize the data and the second step is train a classifier using Support Vector Machine.
Search Space Section
This section corresponds to the search space for your hyperparameters. When you use `nnictrl` this is typically specified in search-space.json file.
See https://nni.readthedocs.io/en/latest/Tutorial/SearchSpaceSpec.html to learn more about the search space syntax.
Here are the important things to note about this section -
The syntax is the same (except we are using YAML here instead of JSON) for specifiying parameter types and ranges.
You MUST specifiy the parameters corresponding to the step in your scikit pipeline.
You MUST use the names of the parameters that are same as the ones accepted by the constructors of scikit-learn components (i.e. preprocessors, estimators etc).
Below is an example of this type of section.
nniConfigSearchSpace:
- normalizer:
norm:
_type: choice
_value: [l2, l1]
- svc:
C:
_type: uniform
_value: [0.1,0.0]
kernel:
_type: choice
_value: [linear,rbf,poly,sigmoid]
degree:
_type: choice
_value: [1,2,3,4]
gamma:
_type: uniform
_value: [0.01,0.1]
coef0:
_type: uniform
_value: [0.01,0.1]Note that sklearn.svm.SVC takes C, kernel, degree, gamman and coef0 is the paramaters and hence we have used here the same names (keys) in the search space specification. You can add as many or as little parameters to search for.
NNI Config Section
This is the simplest of all sections as there is nothing new here from sknni perspective. You just copy-paste here your NNI’s config.yaml here. You do not have to specify codedir and command field in the trial subsection as this is added by the sknni in the generated configuration files.
See https://nni.readthedocs.io/en/latest/Tutorial/ExperimentConfig.html
Here is an example of this type of section.
# This is exactly same as the one that of NNI
# except that you do not have to specify the command
# and code fields. They are automatically added by the sknni generator
nniConfig:
authorName: default
experimentName: example_sklearn-classification
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 100
trainingServicePlatform: local
useAnnotation: false
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
trial:
gpuNum: 0You can look at the various examples in the repository to learn how to define your own specification file.
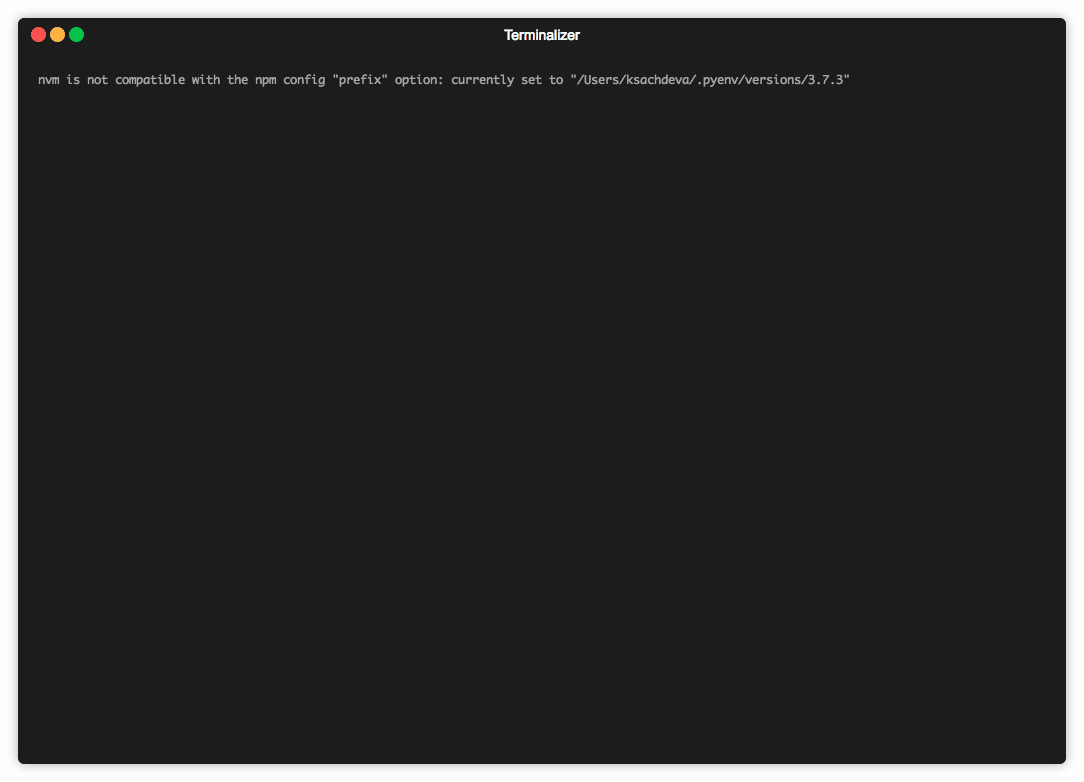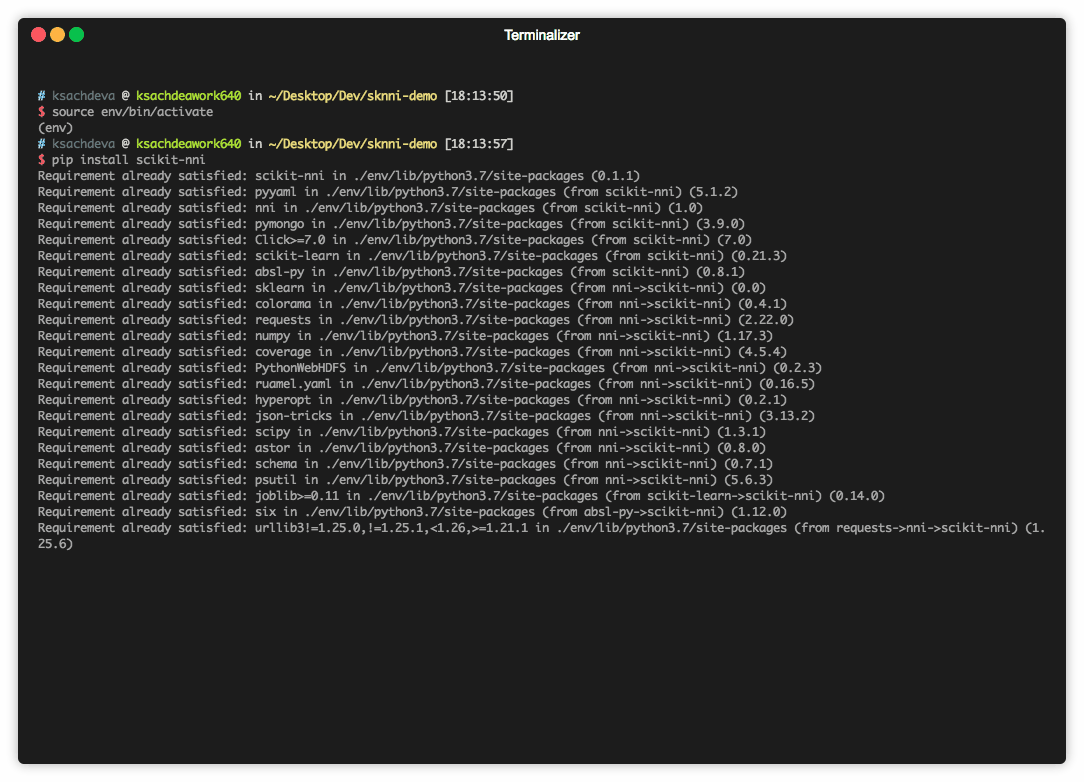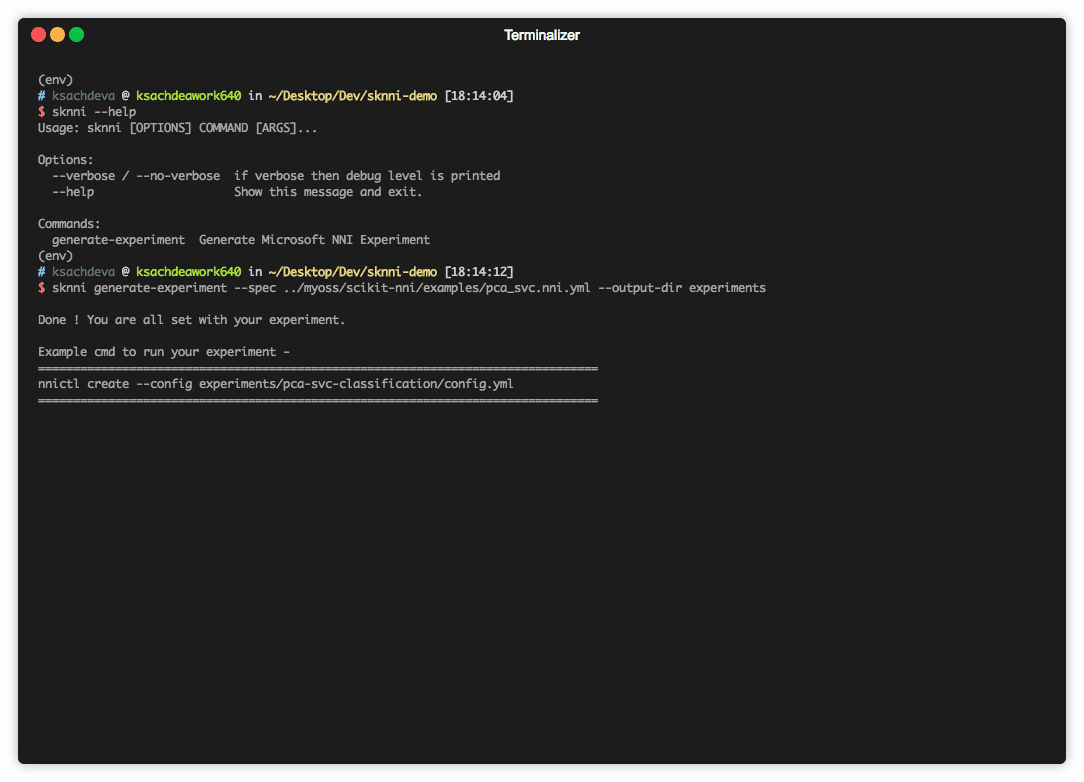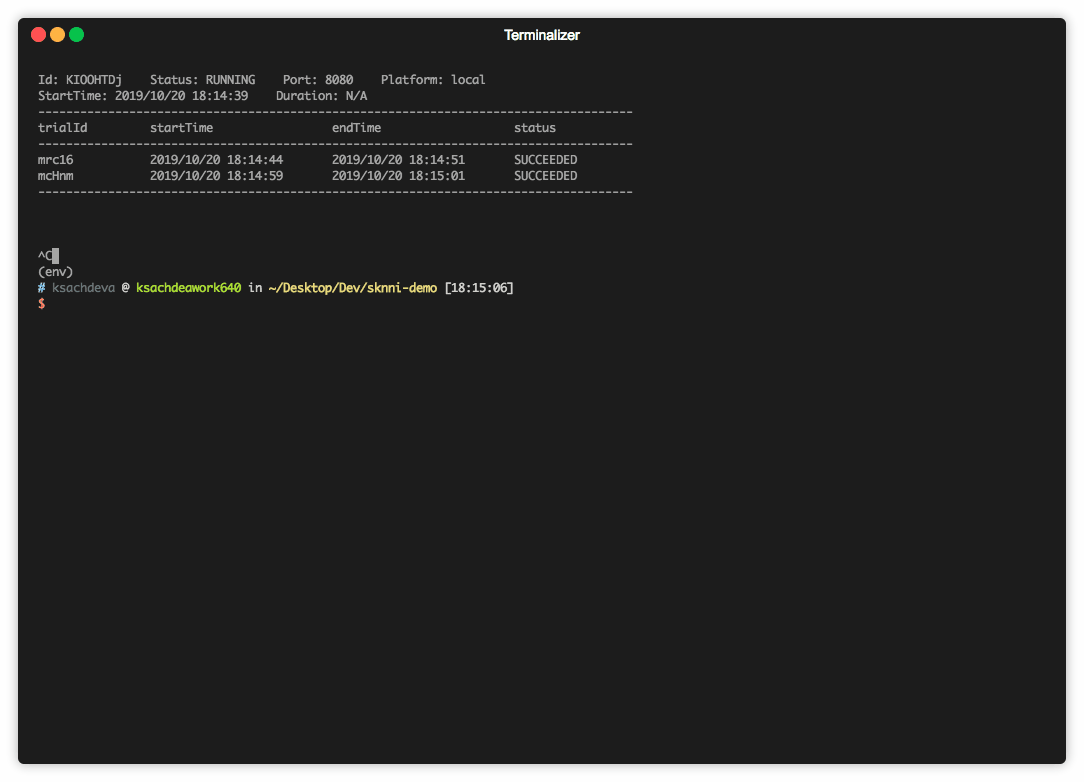
Step 2 - Generate your experiment
sknni generate-experiment --spec example/basic_svc.nni.yml --output-dir experimentsAbove command will create a directory experiments/svc-classification with the following files
The original specification file i.e. basic_svc.nni.yml (used during experiment run as well)
Generated Microsoft NNI’s config.yml
Generated Microsoft NNI’s search-space.json
Note - there is no python file as typically shown in the examples of Microsoft NNI as the command in ends up invoking sknni entry point when the experiment is run.
Step 3 - Run your experiment
This is same as running nnitctl
nnictl create --config experiments/svc-classification/config.ymlTroubleshooting
My trials are failing what is wrong ?
Your trial could fail for many reasons -
Bug in your DataSource code resulting the exception/error
Wrong inputs to your (or built-in) DataSources resulting in exception/error
Your DataSource (python callable) could not be found
Here is what I would recommend -
Test your DataSource code
The webui does not always display all the errors/logs so look at the log of your trials and more specifically stderr file
cat $HOME/nni/experiments/<YOUR_EXPERIMENT_ID>/trials/<TRIAL_ID>/stderr cat $HOME/nni/experiments/<YOUR_EXPERIMENT_ID>/trials/<TRIAL_ID>/trial.log
Credits
This package was created with Cookiecutter and the audreyr/cookiecutter-pypackage project template.
History
0.1.1 (2019-10-20)
First release on PyPI.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file scikit-nni-0.2.1.tar.gz.
File metadata
- Download URL: scikit-nni-0.2.1.tar.gz
- Upload date:
- Size: 18.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.4.0 requests-toolbelt/0.9.1 tqdm/4.36.1 CPython/3.7.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
133f36f58b73bcae0a6ee0ab932a4001927cd3f5aab55659c0276e853bbe8a36
|
|
| MD5 |
ec9e77e85c5758b192339dc246b31610
|
|
| BLAKE2b-256 |
24b27fa0a36c4d9623403182bb701ec94c44be866c68d5ddcb17762bf779fcb5
|
File details
Details for the file scikit_nni-0.2.1-py2.py3-none-any.whl.
File metadata
- Download URL: scikit_nni-0.2.1-py2.py3-none-any.whl
- Upload date:
- Size: 11.1 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.4.0 requests-toolbelt/0.9.1 tqdm/4.36.1 CPython/3.7.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6b474697823867b47b7c471888982efcc6bba213c8ba09df5ccd9f8f8d586283
|
|
| MD5 |
7e116f38aeddb7a4e752bc96266b3666
|
|
| BLAKE2b-256 |
0775ddb13db7b23707a580407aa17929e003cd8c3f7adc905e3d5bb5dc8dfa4e
|







