Model Compresion Made Easy

Project description




Bored to read it thoroughly? Give a quick look at the mind map behind why this package was developed: Mind Map. Then get grinding with a Quick Start Notebook:

If you are still reading, bruh!!!! Thank you…
The advancement of deep learning has been primarily driven by the availability of large datasets and the computational power to train large models. The complexity increases with each day, and it is becoming increasingly difficult to train/deploy these models. However, the brain can learn from a few examples and is incredibly energy efficient (Psst.. that too sparsely).
Humans tend to solve problems from their lens of perspective, and thus, we comprehend the universe through mathematical models. One such postulation is the concept of gradient descent or other optimization techniques we use to train our models. However, the brain does not use gradient descent to learn. How the brain learns and can solve complex problems is still a mystery.
Until we hit the holy grail, we must make wise methods to achieve efficiency. The logical solution is to minimize the usage of COPM (Performance, Computation, Power, Memory) and thus achieve high throughputs and latency gains.
Hence, this package aims to bridge this gap by compressing a model end-to-end and making it hardware-friendly with Minimal Human Intervention.

AutoML at its Heart: Humans are lazy, at least I am; hence, we want to get things done with Minimal Human Intervention. Sconce was built on this ideology that anyone with nominal knowledge of DL should be able to use this package. Drop your model into the package, call sconce.compress, and let it do the magic for you.
Compress the model through Pruning, Quantization, etc.
Bring your own dataset and let the Neural Architecture Search (NAS) find the best model that fits your deployment constraints.
Leverage Sparsity in the model and deploy/infer using Sparse Engines.
- Accelerate Inferencing and Reduce Memory Footprint, Inference Optimizations:
- CUDA Based:
Loop Unrolling
Loop Tiling
Loop Reordering
- Inference Based:
Im2Col Convolution
In-Place Depth-Wise Convolution
Winograd
Memory Layout
In addition, this package also supports Spiking Neural Networks(snnTorch) in this compression pipeline.
If you like this project, please consider starring ⭐ this repo as it is the easiest and best way to support it.
Let me know if you are using sconce in any interesting work, research or blogs, as we would love to hear more about it!
If you have issues, comments, or are looking for advice on training spiking neural networks, you can open an issue, a discussion, or chat in our discord channel. |
A Brief workflow is shown below:
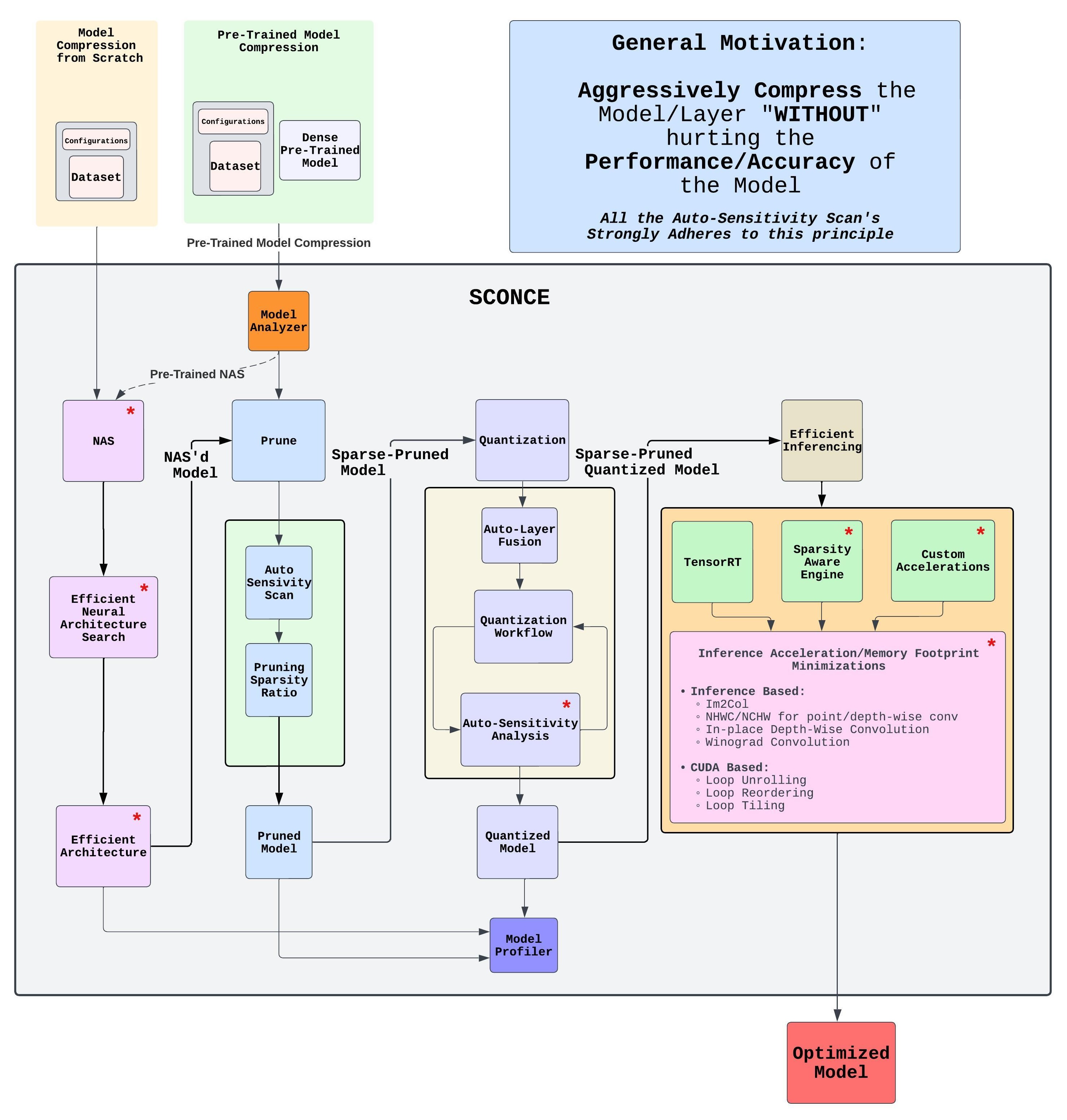
sconce is designed to be intuitively used with PyTorch, compression for Linear, Convolutional and Attention blocks are supported.
At present, I am working on adding support for more compression techniques and more models. kindly be patient for feature request/bug fixes.
The package envisions to be a one stop solution for all your compression needs and deployed on resource constrained devices. Provided that the network models and tensors are loaded onto CUDA, sconce takes advantage of GPU acceleration in the same way as PyTorch.
sconce is a work in progress, and we welcome contributions from the community. The current status of the package and future plans can be found here: sconce Roadmap.
Quickstart
Here are a few ways you can get started with sconce:
Quickstart:
Define Network:
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 8, 3)
self.bn1 = nn.BatchNorm2d(8)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(8, 16, 3)
self.bn2 = nn.BatchNorm2d(16)
self.fc1 = nn.Linear(16*6*6, 32)
self.fc2 = nn.Linear(32, 10)
def forward(self, x):
x = self.pool(self.bn1(F.relu(self.conv1(x))))
x = self.pool(self.bn2(F.relu(self.conv2(x))))
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return xMake a Dict for Dataloader
image_size = 32
transforms = {
"train": Compose([
RandomCrop(image_size, padding=4),
RandomHorizontalFlip(),
ToTensor(),
]),
"test": ToTensor(),
}
dataset = {}
for split in ["train", "test"]:
dataset[split] = CIFAR10(
root="data/cifar10",
train=(split == "train"),
download=True,
transform=transforms[split],
)
dataloader = {}
for split in ['train', 'test']:
dataloader[split] = DataLoader(
dataset[split],
batch_size=512,
shuffle=(split == 'train'),
num_workers=0,
pin_memory=True,
)Define your Configurations:
# Define all parameters
from sconce import sconce
sconces = sconce()
sconces.model= Net() # Model Definition
sconces.criterion = nn.CrossEntropyLoss() # Loss
sconces.optimizer= optim.Adam(sconces.model.parameters(), lr=1e-4)
sconces.scheduler = optim.lr_scheduler.CosineAnnealingLR(sconces.optimizer, T_max=200)
sconces.dataloader = dataloader
sconces.epochs = 5 #Number of time we iterate over the data
sconces.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sconces.experiment_name = "vgg-gmp" # Define your experiment name here
sconces.prune_mode = "CWP" #
# Note Sensitivity Analysis is applied before pruning: The tutorial explains this in detail: https://sconce.readthedocs.io/en/latest/tutorials/Pruning.html#lets-first-evaluate-the-accuracy-and-model-size-of-dense-model Look out for the header “Sensitivity Scan”.One Roof Solution:
sconces.compress()# Channel-Wise Pruning
+---------------------+----------------+--------------+-----------------+
| | Original Model | Pruned Model | Quantized Model |
+---------------------+----------------+--------------+-----------------+
| Latency (ms/sample) | 6.4 | 5.2 | 2.1 |
| Accuracy (%) | 93.136 | 91.303 | 91.222 |
| Params (M) | 9.23 | 7.14 | * |
| Size (MiB) | 36.949 | 28.581 | 7.196 |
| MAC (M) | 606 | 455 | * |
+---------------------+----------------+--------------+-----------------+sconces.prune_mode = "GMP"
sconces.compress()# Granular Magnitude Based Pruning
+---------------------+----------------+--------------+-----------------+
| | Original Model | Pruned Model | Quantized Model |
+---------------------+----------------+--------------+-----------------+
| Latency (ms/sample) | 6.4 | 6.4 | 2.3 |
| Accuracy (%) | 93.136 | 91.884 | 91.924 |
| Params (M) | 9.23 | 2.56 | * |
| Size (MiB) | 36.949 | 36.949 | 9.293 |
| MAC (M) | 606 | 606 | * |
+---------------------+----------------+--------------+-----------------+sconce Structure
sconce contains the following components:
Component |
Description |
|---|---|
a spiking neuron library like torch.nn, deeply integrated with autograd |
|
Compares the performance of two PyTorch models: an original dense model and a pruned and fine-tuned model. Prints a table of metrics including latency, MACs, and model size for both models and their reduction ratios. |
|
Currently supporting Gradual Magnitude Pruning(GMP), L1/L2 based Channel Wise Pruning(CWP), OBC, sparsegpt, etc… |
|
Quantize the computations of the model to make it more efficient for hardware Deployment/Inferences. |
|
Automated compression pipeline encompassing of Pruning, Quantization, and Sparsification. |
Requirements
The following packages need to be installed to use sconce:
torch >= 1.1.0
numpy >= 1.17
torchprofile
matplotlib
snntorch
They are automatically installed if sconce is installed using the pip command. Ensure the correct version of torch is installed for your system to enable CUDA compatibility.
✌️
Installation
Run the following to install:
$ python
$ pip install sconceTo install sconce from source instead:
$ git clone https://github.com/satabios/sconce $ cd sconce $ python setup.py install
API & Examples
A complete API is available here. Examples, tutorials and Colab notebooks are provided.
Contributing
If you’re ready to contribute to sconce, ping on discord channel.
Acknowledgments
sconce is solely being maintained by Sathyaprakash Narayanan.
Special Thanks:
Prof. and Mentor Jason K. Eshraghian and his pet snnTorch (extensively inspired from snnTorch to build and document sconce)
Prof. Song Han for his coursework MIT6.5940 and many other projects like torchsparse.
Neural Magic(Elias Frantar, Denis Kuznedelev, etc…) for OBC and sparseGPT.
License & Copyright
sconce source code is published under the terms of the MIT License. sconce’s documentation is licensed under a Creative Commons Attribution-Share Alike 3.0 Unported License (CC BY-SA 3.0).
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file sconce-0.99.1.tar.gz.
File metadata
- Download URL: sconce-0.99.1.tar.gz
- Upload date:
- Size: 32.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6bf62c5704fd43c10cddb5e4d61650c68ee2fb2fdcc56dc1d76566e93a3b6a5e
|
|
| MD5 |
3b24e0f72f5d68dacf8d47008e00aaf8
|
|
| BLAKE2b-256 |
39e7a52a992357d55f3db42d9a065f331007d3e75ccd873011cae2abf61a6aed
|
File details
Details for the file sconce-0.99.1-py2.py3-none-any.whl.
File metadata
- Download URL: sconce-0.99.1-py2.py3-none-any.whl
- Upload date:
- Size: 24.0 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
df8c5e4f59306d69b0cbedd257731af0842703c20006912dde490f2352200dc8
|
|
| MD5 |
b69c4840d572912f29ced2f522c61467
|
|
| BLAKE2b-256 |
58c5df5033784e7d8c6d162751031d35e48a3503614ce8851088ee928b78619a
|







