Scrape query definition intends to eliminate backend process of crawling and focus on xpath needed to get data. Library queries are developed using graphql-core library.

Project description
ScrapQD - Scraper Query Definition (beta)
ScrapQD consists of query definition created for scraping web data using GraphQL-Core which is port of GraphQL.js.
Library intends to focus on how to locate data from website and eliminate backend process of crawling. So people can just have xpath and get data right away.
It supports scraping using requests for traditional websites and selenium for modern websites (js rendering). Under selenium it supports Google Chrome and FireFox drivers.
ScrapQD library only uses lxml parser and xpath used to locate elements.




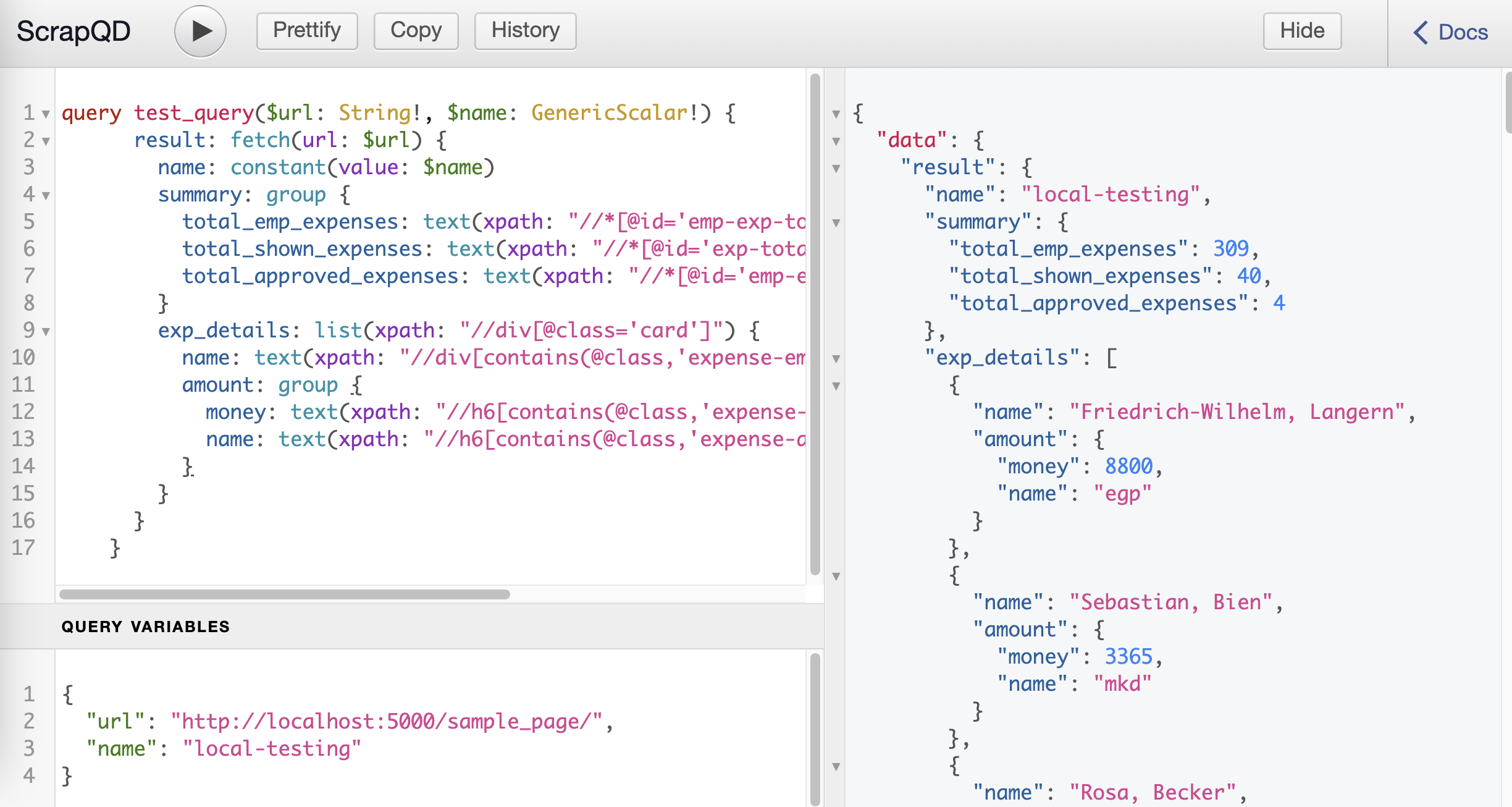
Getting Started
Query
Sample query is loaded to GraphQL UI and sample page is available within the server to practice.
query test_query($url: String!, $name: GenericScalar!) {
result: fetch(url: $url) {
name: constant(value: $name)
summary: group {
total_emp_expenses: text(xpath: "//*[@id='emp-exp-total']", data_type: INT)
total_shown_expenses: text(xpath: "//*[@id='exp-total']/span[2]", data_type: INT)
total_approved_expenses: text(xpath: "//*[@id='emp-exp-approved']/span[2]", data_type: INT)
}
exp_details: list(xpath: "//div[@class='card']") {
name: text(xpath: "//div[contains(@class,'expense-emp-name')]")
amount: group {
money: text(xpath: "//h6[contains(@class,'expense-amount')]/span[1]", data_type: INT)
name: text(xpath: "//h6[contains(@class,'expense-amount')]/span[2]")
}
}
}
}query variable
// url will be used in the above query
query_variables = {
"url": "http://localhost:5000/scrapqd/sample_page/",
"name": "local-testing"
}Result
{
"data": {
"result": {
"name": "local-testing",
"summary": {
"total_emp_expenses": 309,
"total_shown_expenses": 40,
"total_approved_expenses": 4
},
"exp_details": [
{
"name": "Friedrich-Wilhelm, Langern",
"amount": {
"money": 8800,
"name": "egp"
}
},
{
"name": "Sebastian, Bien",
"amount": {
"money": 3365,
"name": "mkd"
}
},
{
"name": "Rosa, Becker",
"amount": {
"money": 6700,
"name": "xof"
}
},
{
"name": "Ines, Gröttner",
"amount": {
"money": 8427,
"name": "npr"
}
}
]
}
}
}Executing with client
from scrapqd.client import execute_sync
query = r"""
query test_query($url: String!, $name: GenericScalar!) {
result: fetch(url: $url) {
name: constant(value: $name)
summary: group {
total_shown_expenses: regex(xpath: "//*[@id='exp-total']", pattern: "(\\d+)")
}
}
}"""
query_variables = {
"url": "http://localhost:5000/scrapqd/sample_page/",
"name": "local-testing"
}
result = execute_sync(self.query, query_variables)Integrating with existing Flask app
Sample Flask app
from flask import Flask
name = __name__
app = Flask(name)
@app.route("/")
def hello_world():
return "<p>Hello, World!</p>"Integrating scrapqd with existing app
from scrapqd.app import register_scrapqd
register_scrapqd(app,
register_sample_url=True,
redirect_root=True)app: Flask application
register_sample_url: False will not register sample page url to Flask application. Default is True
redirect_root: Redirect root url to graphql ui if this is set to True. This will not reflect, if there is already root route defined as above example.
Test (for development)
Clone the github repository
git clone https://github.com/dduraipandian/scrapqd.gitcreate virtual environment to work
pip3 install virtualenv virtualenv scrapqd_venv source scrapqd_venv/bin/activateinstall tox
pip install toxrun tox from the project root directory
current tox have four python version - py37,py38,py39,py310
check your python version
python3 --version # Python 3.9.10once you get your version (example: use py39 for 3.9) to run tox
tox -e py39
FAQs
How to copy query from graphql ui to python code.
you can normally copy code from ui to python code to execute using client.
if you hav regex query, patterns needs to escaped in the python code. In such, use python raw strings, where backslashes are treated as literal characters, as above example.
How to suppress webdriver logs
If you see webdriver logs like below, set WDM_LOG_LEVEL=0 as environment variable and run
[INFO] [97002] [2022-03-14T02:18:26+0530] [SCRAPQD] [/webdriver_manager/logger.py:log():26] [WDM] [Driver [/99.0.4844.51/chromedriver] ...]
How to change log level for scrapqd library
ERROR level is default logging. You can change this with SCRAPQD_LOG_LEVEL environment variable.
License
This project is licensed under the MIT License - see the LICENSE file for details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file scrapqd-1.0.1b0.tar.gz.
File metadata
- Download URL: scrapqd-1.0.1b0.tar.gz
- Upload date:
- Size: 61.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.63.0 importlib-metadata/4.11.3 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.10.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bb929aa9d2155f15b187460ce7d629c7bf94a8be907781d5f8991f431ac62ef4
|
|
| MD5 |
d38fc8bf571e2f53df4c6c3b823d361c
|
|
| BLAKE2b-256 |
92453766e6b7b471d4d545934419ec7c6fb5e033c3aa286e184f0cc177e252f6
|
File details
Details for the file scrapqd-1.0.1b0-py3-none-any.whl.
File metadata
- Download URL: scrapqd-1.0.1b0-py3-none-any.whl
- Upload date:
- Size: 62.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.63.0 importlib-metadata/4.11.3 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.10.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ca2a535a88705eff034432ab7acc4ccca6c5813225546d4a0ed5ac9dd0279037
|
|
| MD5 |
206397d312432520733a6935713d7700
|
|
| BLAKE2b-256 |
8d25fd22d5b1630f6da653a1cff2ebe1879a29f06c077f83ab1cf3edb14209ca
|







