A RNAseq pipeline from raw reads to feature counts


Project description




This is the RNA-seq pipeline from the Sequana project
- Overview:
RNASeq analysis from raw data to feature counts
- Input:
A set of Fastq Files and genome reference and annotation.
- Output:
MultiQC and HTML reports, BAM and bigwig files, feature Counts, script to launch differential analysis
- Status:
Production.
- Citation(sequana):
Cokelaer et al, (2017), ‘Sequana’: a Set of Snakemake NGS pipelines, Journal of Open Source Software, 2(16), 352, JOSS DOI doi:10.21105/joss.00352
- Citation(pipeline):
-

Installation
sequana_rnaseq is based on Python3, just install the package as follows:
pip install sequana_rnaseq --upgrade
You will need third-party software such as bowtie2/star. However, if you choose to use apptainer/singularity, then nothing to install except singularity itself ! See below for details.
Usage
sequana_rnaseq --help sequana_rnaseq --input-directory DATAPATH --genome-directory genome --aligner-choice star
This creates a directory with the pipeline and configuration file. You will then need to execute the pipeline:
cd rnaseq sh rnaseq.sh # for a local run
This launches a snakemake pipeline. If you are familiar with snakemake, you can retrieve the pipeline itself and its configuration files and then execute the pipeline yourself with specific parameters:
snakemake -s rnaseq.rules -c config.yaml --cores 4 --stats stats.txt
Or use sequanix interface.
Usage with apptainer:
With apptainer, initiate the working directory as follows:
sequana_rnaseq --apptainer-prefix ~/.sequana/apptainers
Images are downloaded in the directory once for all; and then:
cd rnaseq sh rnaseq.sh
if you decide to use snakemake manually, do not forget to add the apptainer-prefix options:
snakemake -s rnaseq.rules -c config.yaml --cores 4 --apptainer-prefix ~/.sequana/apptainers --apptainer-args "-B /home:/home"
Usage on cluster with no internet access
We use wrappers that are hosted on github: https://github.com/sequana/sequana-wrappers/ . They are copied locally in your home. However if you wish, you can download the repository locally before using the pipeline. For example:
export WRAPPERS=/home/user/Wrappers git clone git@github.com:sequana/sequana-wrappers.git $WRAPPERS
and define an environmental variable as follows (you should add it in your .profile or .bashrc for long term usage):
export SEQUANA_WRAPPERS=git+file://$WRAPPERS
Requirements
This pipelines requires lots of third-party executable(s). Here is a list that may change. A Message will inform you would you be missing an executable:
bowtie
bowtie2>=2.4.2
STAR
featureCounts (subread package)
picard
multiqc
samtools
Note that bowtie>=2.4.2 is set to ensure the pipeline can be used with python 3.7-3.8-3.9 and the sequana-wrappers that supports bowtie2 with option –threads only (not previous versions). See environment.yaml or conda.yaml for latest list of required third-party tools.
You can install most of the tools using damona:
damona create --name sequana_tools damona activate sequana_tools damona install sequana_tools
Or use the conda.yaml file available in this repository. If you start a new environment from scratch, those commands will create the environment and install all dependencies for you:
conda create --name sequana_env python 3.9 conda activate sequana_env conda install -c anaconda qt pyqt>5 pip install sequana pip install sequana_rnaseq conda install --file https://raw.githubusercontent.com/sequana/rnaseq/main/conda.yaml
For Linux users, we provide singularity images available through within the damona project (https://damona.readthedocs.io).
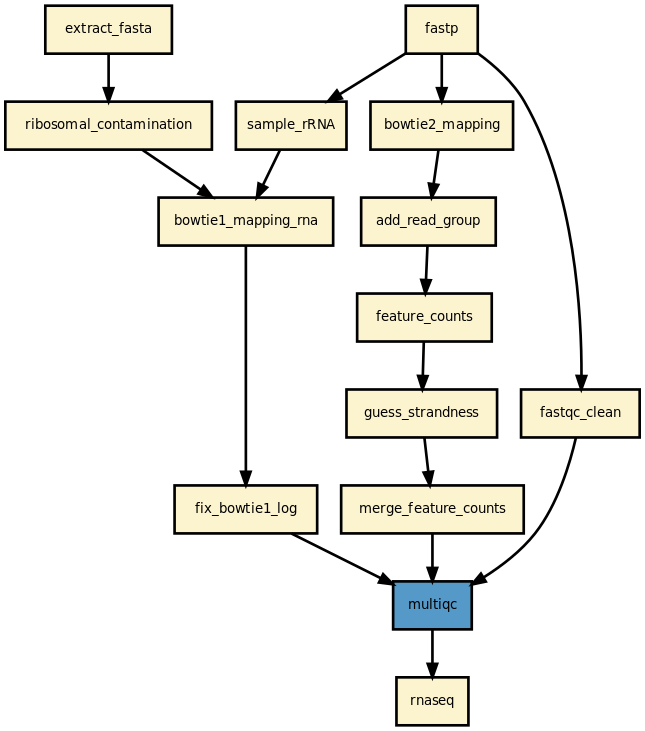
Details
This pipeline runs a RNA-seq analysis of sequencing data. It runs in parallel on a set of input FastQ files (paired or not). A brief HTML report is produced together with a MultiQC report.
This pipeline is complex and requires some expertise for the interpretation. Many online-resources are available and should help you deciphering the output.
Yet, it should be quite straightforward to execute it as shown above. The pipeline uses bowtie1 to look for ribosomal contamination (rRNA). Then, it cleans the data with cutapdat if you say so (your data may already be pre-processed). If no adapters are provided (default), reads are trimmed for low quality bases only. Then, mapping is performed with standard mappers such as star or bowtie2 (–aligner option). Finally, feature counts are extracted from the previously generated BAM files. We guess the strand and save the feature counts into the directory ./rnadiff/feature_counts.
The pipeline stops there. However, RNA-seq analyses are followed by a different analysis (DGE hereafter). Although the DGE is not part of the pipeline, you can perform it with standard tools using the data in ./rnadiff directory. One such tool is provided within our framework (based on the well known DEseq2 software).
Using our framework:
cd rnadiff
sequana rnadiff --design design.csv --features all_features.out --annotation ANNOT \
--feature-name FEAT --attribute-name ATTR
where ANNOT is the annotation file of your analysis, FEAT and ATTR the attribute and feature used in your analysis (coming from the annotation file).
This produces a HTML report summarizing your differential analysis.i
Note that you need DESEQ2 and other packages installed. You may also use this container: https://zenodo.org/records/5708856
Rules and configuration details
Here is the latest documented configuration file to be used with the pipeline. Each rule used in the pipeline may have a section in the configuration file.
Issues
In the context of eukaryotes, you will need 32G of memory most probably. If this is too much, you can try to restrict the memory. Check out the config.yaml file in the star section.
Changelog
Version |
Description |
|---|---|
0.21.0 |
|
0.20.2 |
|
0.20.1 |
|
0.20.0 |
|
0.19.3 |
|
0.19.2 |
|
0.19.1 |
|
0.19.0 |
|
0.18.1 |
|
0.18.0 |
|
0.17.2 |
|
0.17.1 |
|
0.17.0 |
|
0.16.1 |
|
0.16.0 |
|
0.15.2 |
|
0.15.1 |
|
0.15.0 |
|
0.14.2 |
|
0.14.1 |
|
0.14.0 |
|
0.13.0 |
|
0.12.1 |
|
0.12.0 |
|
0.11.0 |
|
0.10.0 |
|
0.9.20 |
|
0.9.19 |
|
0.9.18 |
|
0.9.17 |
|
0.9.16 |
|
0.9.15 |
|
0.9.14 |
|
0.9.13 |
|
0.9.12 |
|
0.9.11 |
|
0.9.10 |
|
0.9.9 |
|
0.9.8 |
|
0.9.7 |
|
0.9.6 |
|
0.9.5 |
|
0.9.4 |
|
0.9.3 |
if a fastq_screen.conf is provided, we switch the fastqc_screen section ON automatically |
0.9.0 |
Major refactorisation.
|
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file sequana_rnaseq-0.21.0.tar.gz.
File metadata
- Download URL: sequana_rnaseq-0.21.0.tar.gz
- Upload date:
- Size: 82.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ddf52d31bef6fcf14cd2c96068cbf1e2460b8728b306d80ffb19c55a83a5d70c
|
|
| MD5 |
1396cebd6b9fada0c24c95ca4ce125c5
|
|
| BLAKE2b-256 |
949d46de5f105f62a43a5b2cba6e70cae12f5a901a7ad816c6cb33b82c615c25
|
File details
Details for the file sequana_rnaseq-0.21.0-py3-none-any.whl.
File metadata
- Download URL: sequana_rnaseq-0.21.0-py3-none-any.whl
- Upload date:
- Size: 81.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
43ae32a2a23a92b826d0552f54398f2a10e63283ad192cc827277eb2949f8a17
|
|
| MD5 |
a6105eb4eb6b89b00ef523a1909261bf
|
|
| BLAKE2b-256 |
ef2a4f2041ed0104bcbe6633b3c51dccf55eafd634f14d4f8aa157e5245e9037
|







