Merlion: A Machine Learning Framework for Time Series Intelligence

Reason this release was yanked:
Deprecated package. Please install the package salesforce-merlion instead.
Project description





Merlion: A Machine Learning Library for Time Series
Table of Contents
- Introduction
- Installation
- Documentation
- Getting Started
- Evaluation and Benchmarking
- Technical Report and Citing Merlion
Introduction
Merlion is a Python library for time series intelligence. It provides an end-to-end machine learning framework that includes loading and transforming data, building and training models, post-processing model outputs, and evaluating model performance. It supports various time series learning tasks, including forecasting and anomaly detection for both univariate and multivariate time series. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs, and benchmark them across multiple time series datasets.
Merlion's key features are
- Standardized and easily extensible data loading & benchmarking for a wide range of forecasting and anomaly detection datasets.
- A library of diverse models for both anomaly detection and forecasting, unified undera shared interface. Models include classic statistical methods, tree ensembles, and deeplearning approaches. Advanced users may fully configure each model as desired.
- Abstract
DefaultDetectorandDefaultForecastermodels that are efficient, robustly achieve good performance, and provide a starting point for new users. - AutoML for automated hyperaparameter tuning and model selection.
- Practical, industry-inspired post-processing rules for anomaly detectors that make anomaly scores more interpretable, while also reducing the number of false positives.
- Easy-to-use ensembles that combine the outputs of multiple models to achieve more robust performance.
- Flexible evaluation pipelines that simulate the live deployment & re-training of a model in production, and evaluate performance on both forecasting and anomaly detection.
- Native support for visualizing model predictions.
The table below provides a visual overview of how Merlion's key features compare to other libraries for time series anomaly detection and/or forecasting.
| Merlion | Alibi Detect | Kats | statsmodels | GluonTS | RRCF | STUMPY | Greykite | Prophet | pmdarima | |
|---|---|---|---|---|---|---|---|---|---|---|
| Univariate Forecasting | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Multivariate Forecasting | ✅ | ✅ | ✅ | ✅ | ||||||
| Univariate Anomaly Detection | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Multivariate Anomaly Detection | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| AutoML | ✅ | ✅ | ✅ | ✅ | ||||||
| Ensembles | ✅ | ✅ | ||||||||
| Benchmarking | ✅ | ✅ | ||||||||
| Visualization | ✅ | ✅ | ✅ | ✅ |
Installation
Merlion consists of two sub-repos: merlion implements the library's core time series intelligence features,
and ts_datasets provides standardized data loaders for multiple time series datasets. These loaders load
time series as pandas.DataFrame s with accompanying metadata.
You can install merlion from PyPI by calling pip install sfdc-merlion. You may install from source by
cloning this repo, navigating to the root directory, and calling pip install ., or pip install -e . to
install in editable mode. You may install additional dependencies for plotting & visualization via
pip install sfdc-merlion[plot], or by calling pip install ".[plot]" from the root directory of this repo.
To install the data loading package ts_datasets, clone this repo, navigate to its root directory, and call
pip install -e ts_datasets/. This package must be installed in editable mode (i.e. with the -e flag)
if you don't want to manually specify the root directory of every dataset when initializing its data loader.
Note the following external dependencies:
-
Some of our forecasting models depend on OpenMP. If using
conda, pleaseconda install -c conda-forge lightgbmbefore installing our package. This will ensure that OpenMP is configured to work with thelightgbmpackage (one of our dependencies) in yourcondaenvironment. If using Mac, please install Homebrew and callbrew install libompso that the OpenMP libary is available for the model. -
Some of our anomaly detection models depend on the Java Development Kit (JDK). For Ubuntu, call
sudo apt-get install openjdk-11-jdk. For Mac OS, install Homebrew and callbrew tap adoptopenjdk/openjdk && brew install --cask adoptopenjdk11.
Documentation
For example code and an introduction to Merlion, see the Jupyter notebooks in
examples, and the guided walkthrough
here. You may find detailed API documentation (including the
example code) here. The
technical report outlines Merlion's overall architecture
and presents experimental results on time series anomaly detection & forecasting for both univariate and multivariate
time series.
Getting Started
Here, we provide some minimal examples using Merlion default models, to help you get started with both anomaly detection and forecasting.
Anomaly Detection
We begin by importing Merlion’s TimeSeries class and the data loader for the Numenta Anomaly Benchmark NAB.
We can then divide a specific time series from this dataset into training and testing splits.
from merlion.utils import TimeSeries
from ts_datasets.anomaly import NAB
# Data loader returns pandas DataFrames, which we convert to Merlion TimeSeries
time_series, metadata = NAB(subset="realKnownCause")[3]
train_data = TimeSeries.from_pd(time_series[metadata.trainval])
test_data = TimeSeries.from_pd(time_series[~metadata.trainval])
test_labels = TimeSeries.from_pd(metadata.anomaly[~metadata.trainval])
We can then initialize and train Merlion’s DefaultDetector, which is an anomaly detection model that
balances performance with efficiency. We also obtain its predictions on the test split.
from merlion.models.defaults import DefaultDetectorConfig, DefaultDetector
model = DefaultDetector(DefaultDetectorConfig())
model.train(train_data=train_data)
test_pred = model.get_anomaly_label(time_series=test_data)
Next, we visualize the model's predictions.
from merlion.plot import plot_anoms
import matplotlib.pyplot as plt
fig, ax = model.plot_anomaly(time_series=test_data)
plot_anoms(ax=ax, anomaly_labels=test_labels)
plt.show()
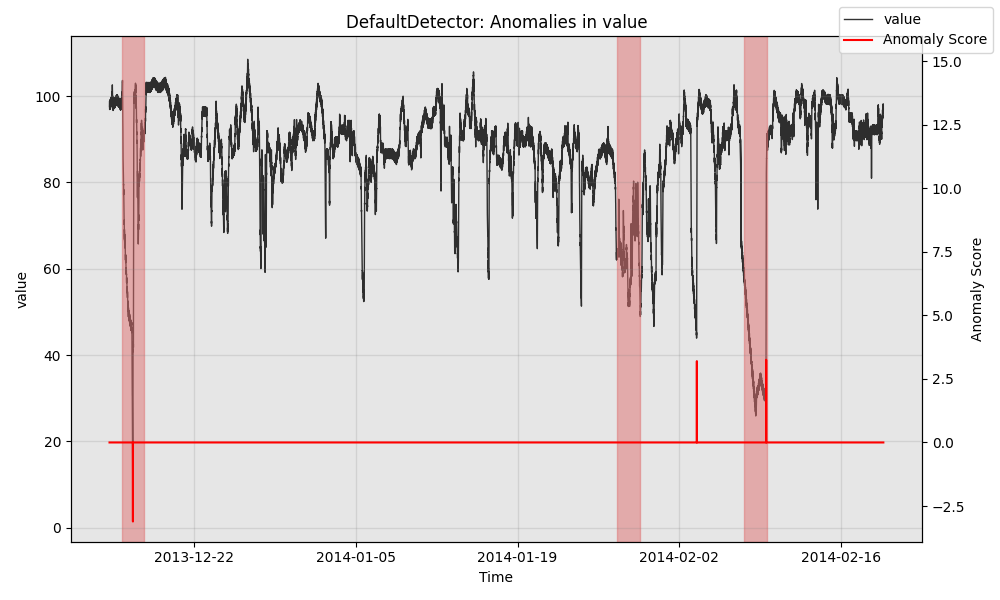
Finally, we can quantitatively evaluate the model. The precision and recall come from the fact that the model fired 3 alarms, with 2 true positives, 1 false negative, and 1 false positive. We also evaluate the mean time the model took to detect each anomaly that it correctly detected.
from merlion.evaluate.anomaly import TSADMetric
p = TSADMetric.Precision.value(ground_truth=test_labels, predict=test_pred)
r = TSADMetric.Recall.value(ground_truth=test_labels, predict=test_pred)
f1 = TSADMetric.F1.value(ground_truth=test_labels, predict=test_pred)
mttd = TSADMetric.MeanTimeToDetect.value(ground_truth=test_labels, predict=test_pred)
print(f"Precision: {p:.4f}, Recall: {r:.4f}, F1: {f1:.4f}\n"
f"Mean Time To Detect: {mttd}")
Precision: 0.6667, Recall: 0.6667, F1: 0.6667
Mean Time To Detect: 1 days 10:30:00
Forecasting
We begin by importing Merlion’s TimeSeries class and the data loader for the M4 dataset. We can then divide a
specific time series from this dataset into training and testing splits.
from merlion.utils import TimeSeries
from ts_datasets.forecast import M4
# Data loader returns pandas DataFrames, which we convert to Merlion TimeSeries
time_series, metadata = M4(subset="Hourly")[0]
train_data = TimeSeries.from_pd(time_series[metadata.trainval])
test_data = TimeSeries.from_pd(time_series[~metadata.trainval])
We can then initialize and train Merlion’s DefaultForecaster, which is an forecasting model that balances
performance with efficiency. We also obtain its predictions on the test split.
from merlion.models.defaults import DefaultForecasterConfig, DefaultForecaster
model = DefaultForecaster(DefaultForecasterConfig())
model.train(train_data=train_data)
test_pred, test_err = model.forecast(time_stamps=test_data.time_stamps)
Next, we visualize the model’s predictions.
import matplotlib.pyplot as plt
fig, ax = model.plot_forecast(time_series=test_data, plot_forecast_uncertainty=True)
plt.show()
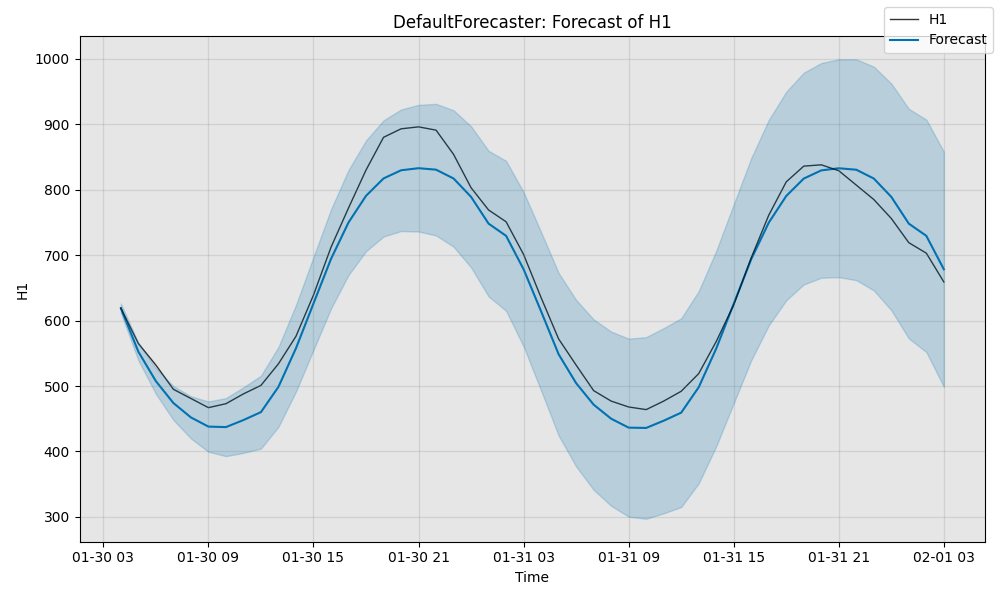
Finally, we quantitatively evaluate the model. sMAPE measures the error of the prediction on a scale of 0 to 100 (lower is better), while MSIS evaluates the quality of the 95% confidence band on a scale of 0 to 100 (lower is better).
# Evaluate the model's predictions quantitatively
from scipy.stats import norm
from merlion.evaluate.forecast import ForecastMetric
# Compute the sMAPE of the predictions (0 to 100, smaller is better)
smape = ForecastMetric.sMAPE.value(ground_truth=test_data, predict=test_pred)
# Compute the MSIS of the model's 95% confidence interval (0 to 100, smaller is better)
lb = TimeSeries.from_pd(test_pred.to_pd() + norm.ppf(0.025) * test_err.to_pd().values)
ub = TimeSeries.from_pd(test_pred.to_pd() + norm.ppf(0.975) * test_err.to_pd().values)
msis = ForecastMetric.MSIS.value(ground_truth=test_data, predict=test_pred,
insample=train_data, lb=lb, ub=ub)
print(f"sMAPE: {smape:.4f}, MSIS: {msis:.4f}")
sMAPE: 6.2855, MSIS: 19.1584
Evaluation and Benchmarking
One of Merlion's key features is an evaluation pipeline that simulates the live deployment of a model on historical data. This enables you to compare models on the datasets relevant to them, under the conditions that they may encounter in a production environment. Our evaluation pipeline proceeds as follows:
- Train an initial model on recent historical training data (designated as the training split of the time series)
- At a regular interval (e.g. once per day), retrain the entire model on the most recent data. This can be either the entire history of the time series, or a more limited window (e.g. 4 weeks).
- Obtain the model's predictions (anomaly scores or forecasts) for the time series values that occur between re-trainings. You may customize whether this should be done in batch (predicting all values at once), streaming (updating the model's internal state after each data point without fully re-training it), or some intermediate cadence.
- Compare the model's predictions against the ground truth (labeled anomalies for anomaly detection, or the actual time series values for forecasting), and report quantitative evaluation metrics.
We provide scripts that allow you to use this pipeline to evaluate arbitrary models on arbitrary datasets. For example, invoking
python benchmark_anomaly.py --dataset NAB_realAWSCloudwatch --model IsolationForest --retrain_freq 1d
will evaluate the anomaly detection performance of the IsolationForest (retrained once a day) on the
"realAWSCloudwatch" subset of the NAB dataset. Similarly, invoking
python benchmark_forecast.py --dataset M4_Hourly --model ETS
will evaluate the batch forecasting performance (i.e. no retraining) of ETS on the "Hourly" subset of the M4 dataset.
You can find the results produced by running these scripts in the Experiments section of the
technical report.
Technical Report and Citing Merlion
You can find more details in our technical report: https://arxiv.org/abs/2109.09265
If you're using Merlion in your research or applications, please cite using this BibTeX:
@article{bhatnagar2021merlion,
title={Merlion: A Machine Learning Library for Time Series},
author={Aadyot Bhatnagar and Paul Kassianik and Chenghao Liu and Tian Lan and Wenzhuo Yang
and Rowan Cassius and Doyen Sahoo and Devansh Arpit and Sri Subramanian and Gerald Woo
and Amrita Saha and Arun Kumar Jagota and Gokulakrishnan Gopalakrishnan and Manpreet Singh
and K C Krithika and Sukumar Maddineni and Daeki Cho and Bo Zong and Yingbo Zhou
and Caiming Xiong and Silvio Savarese and Steven Hoi and Huan Wang},
year={2021},
eprint={2109.09265},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file sfdc-merlion-1.0.0.tar.gz.
File metadata
- Download URL: sfdc-merlion-1.0.0.tar.gz
- Upload date:
- Size: 480.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e17dd88b7307ec4c5152f10d6bc0437c77d4f394171d72b87d7b0866cdfc35a6
|
|
| MD5 |
93eb88a135a4ce4f406fd57dfe791052
|
|
| BLAKE2b-256 |
2cc4eb99394a32b3481c23cc077fb66a979eca58b99697ed14f67f6f988c0001
|
File details
Details for the file sfdc_merlion-1.0.0-py3-none-any.whl.
File metadata
- Download URL: sfdc_merlion-1.0.0-py3-none-any.whl
- Upload date:
- Size: 522.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f4a62b1a5010948a2bc35059ea130c4159d4b8069d70003fdadf83292a587747
|
|
| MD5 |
e467a7a42b10ae1be5c3446ba1e72dd8
|
|
| BLAKE2b-256 |
35fd3d3b68652c4d30f896a8c9520370059b1c6928edf99fcfc24070e50822ee
|







