Tools for simple inference testing using TensorRT, CUDA and OpenVINO CPU/GPU and CPU providers. Simple Inference Test for ONNX.

Project description
sit4onnx
Tools for simple inference testing using TensorRT, CUDA and OpenVINO CPU/GPU and CPU providers. Simple Inference Test for ONNX.
https://github.com/PINTO0309/simple-onnx-processing-tools





ToDo
- Add an interface to allow arbitrary test data to be specified as input parameters.
- numpy.ndarray
- numpy file
- Allow static fixed shapes to be specified when dimensions other than batch size are undefined.
- Returns numpy.ndarray of the last inference result as a return value when called from a Python script.
- Add
--output_numpy_fileoption. Output the final inference results to a numpy file. - Add
--non_verboseoption.
1. Setup
1-1. HostPC
### option
$ echo export PATH="~/.local/bin:$PATH" >> ~/.bashrc \
&& source ~/.bashrc
### run
$ pip install -U onnx \
&& pip install -U sit4onnx
1-2. Docker
https://github.com/PINTO0309/simple-onnx-processing-tools#docker
2. CLI Usage
$ sit4onnx -h
usage:
sit4onnx [-h]
-if INPUT_ONNX_FILE_PATH
[-b BATCH_SIZE]
[-fs DIM0 [DIM1 DIM2 ...]]
[-tlc TEST_LOOP_COUNT]
[-oep {tensorrt,cuda,openvino_cpu,openvino_gpu,cpu}]
[-pro]
[-iont INTRA_OP_NUM_THREADS]
[-ifp INPUT_NUMPY_FILE_PATHS_FOR_TESTING]
[-ofp]
[-n]
optional arguments:
-h, --help
show this help message and exit.
-if, --input_onnx_file_path INPUT_ONNX_FILE_PATH
Input onnx file path.
-b, --batch_size BATCH_SIZE
Value to be substituted if input batch size is undefined.
This is ignored if the input dimensions are all of static size.
Also ignored if input_numpy_file_paths_for_testing
or numpy_ndarrays_for_testing or fixed_shapes is specified.
-fs, --fixed_shapes DIM0 [DIM1 DIM2 ...]
Input OPs with undefined shapes are changed to the specified shape.
This parameter can be specified multiple times depending on
the number of input OPs in the model.
Also ignored if input_numpy_file_paths_for_testing is specified.
e.g.
--fixed_shapes 1 3 224 224
--fixed_shapes 1 5
--fixed_shapes 1 1 224 224
-tlc, --test_loop_count TEST_LOOP_COUNT
Number of times to run the test.
The total execution time is divided by the number of times the test is executed,
and the average inference time per inference is displayed.
-oep, --onnx_execution_provider {tensorrt,cuda,openvino_cpu,openvino_gpu,cpu}
ONNX Execution Provider.
-iont, --intra_op_num_threads INTRA_OP_NUM_THREADS
Sets the number of threads used to parallelize the execution within nodes.
Default is 0 to let onnxruntime choose.
-pro, --enable_profiling
Outputs performance profiling result to a .json file
-ifp, --input_numpy_file_paths_for_testing INPUT_NUMPY_FILE_PATHS_FOR_TESTING
Use an external file of numpy.ndarray saved using np.save as input data for testing.
This parameter can be specified multiple times depending on the number of input OPs
in the model.
If this parameter is specified, the value specified for batch_size and fixed_shapes
are ignored.
e.g.
--input_numpy_file_paths_for_testing aaa.npy
--input_numpy_file_paths_for_testing bbb.npy
--input_numpy_file_paths_for_testing ccc.npy
-ofp, --output_numpy_file
Outputs the last inference result to an .npy file.
-n, --non_verbose
Do not show all information logs. Only error logs are displayed.
3. In-script Usage
>>> from sit4onnx import inference
>>> help(inference)
Help on function inference in module sit4onnx.onnx_inference_test:
inference(
input_onnx_file_path: str,
batch_size: Union[int, NoneType] = 1,
fixed_shapes: Union[List[int], NoneType] = None,
test_loop_count: Union[int, NoneType] = 10,
onnx_execution_provider: Union[str, NoneType] = 'tensorrt',
intra_op_num_threads: Optional[int] = 0,
enable_profiling: Optional[bool] = False,
input_numpy_file_paths_for_testing: Union[List[str], NoneType] = None,
numpy_ndarrays_for_testing: Union[List[numpy.ndarray], NoneType] = None,
output_numpy_file: Union[bool, NoneType] = False,
non_verbose: Union[bool, NoneType] = False
) -> List[numpy.ndarray]
Parameters
----------
input_onnx_file_path: str
Input onnx file path.
batch_size: Optional[int]
Value to be substituted if input batch size is undefined.
This is ignored if the input dimensions are all of static size.
Also ignored if input_numpy_file_paths_for_testing or
numpy_ndarrays_for_testing is specified.
Default: 1
fixed_shapes: Optional[List[int]]
Input OPs with undefined shapes are changed to the specified shape.
This parameter can be specified multiple times depending on the number of input OPs
in the model.
Also ignored if input_numpy_file_paths_for_testing or numpy_ndarrays_for_testing
is specified.
e.g.
[
[1, 3, 224, 224],
[1, 5],
[1, 1, 224, 224],
]
Default: None
test_loop_count: Optional[int]
Number of times to run the test.
The total execution time is divided by the number of times the test is executed,
and the average inference time per inference is displayed.
Default: 10
onnx_execution_provider: Optional[str]
ONNX Execution Provider.
"tensorrt" or "cuda" or "openvino_cpu" or "openvino_gpu" or "cpu"
Default: "tensorrt"
intra_op_num_threads: Optional[int]
Sets the number of threads used to parallelize the execution within nodes.
Default is 0 to let onnxruntime choose.
enable_profiling: Optional[bool]
Outputs performance profiling result to a .json file
Default: False
input_numpy_file_paths_for_testing: Optional[List[str]]
Use an external file of numpy.ndarray saved using np.save as input data for testing.
If this parameter is specified, the value specified for batch_size and fixed_shapes
are ignored.
numpy_ndarray_for_testing Cannot be specified at the same time.
For models with multiple input OPs, specify multiple numpy file paths in list format.
e.g. ['aaa.npy', 'bbb.npy', 'ccc.npy']
Default: None
numpy_ndarrays_for_testing: Optional[List[np.ndarray]]
Specify the numpy.ndarray to be used for inference testing.
If this parameter is specified, the value specified for batch_size and fixed_shapes
are ignored.
input_numpy_file_paths_for_testing Cannot be specified at the same time.
For models with multiple input OPs, specify multiple numpy.ndarrays in list format.
e.g.
[
np.asarray([[[1.0],[2.0],[3.0]]], dtype=np.float32),
np.asarray([1], dtype=np.int64),
]
Default: None
output_numpy_file: Optional[bool]
Outputs the last inference result to an .npy file.
Default: False
non_verbose: Optional[bool]
Do not show all information logs. Only error logs are displayed.
Default: False
Returns
-------
final_results: List[np.ndarray]
Last Reasoning Results.
4. CLI Execution
$ sit4onnx \
--input_onnx_file_path osnet_x0_25_msmt17_Nx3x256x128.onnx \
--batch_size 10 \
--test_loop_count 10 \
--onnx_execution_provider tensorrt
5. In-script Execution
from sit4onnx import inference
inference(
input_onnx_file_path="osnet_x0_25_msmt17_Nx3x256x128.onnx",
batch_size=10,
test_loop_count=10,
onnx_execution_provider="tensorrt",
)
6. Sample
$ pip install -U sit4onnx
$ sit4onnx \
--input_onnx_file_path osnet_x0_25_msmt17_Nx3x256x128.onnx \
--batch_size 10 \
--test_loop_count 10 \
--onnx_execution_provider tensorrt
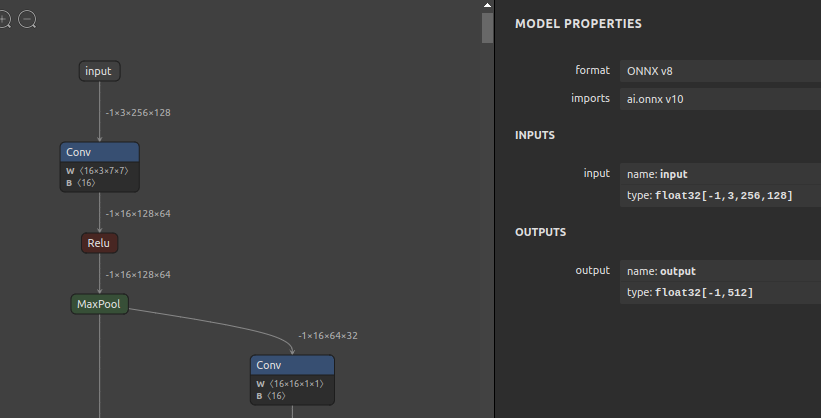

$ pip install -U sit4onnx
$ sit4onnx \
--input_onnx_file_path sci_NxHxW.onnx \
--fixed_shapes 100 3 224 224 \
--onnx_execution_provider tensorrt
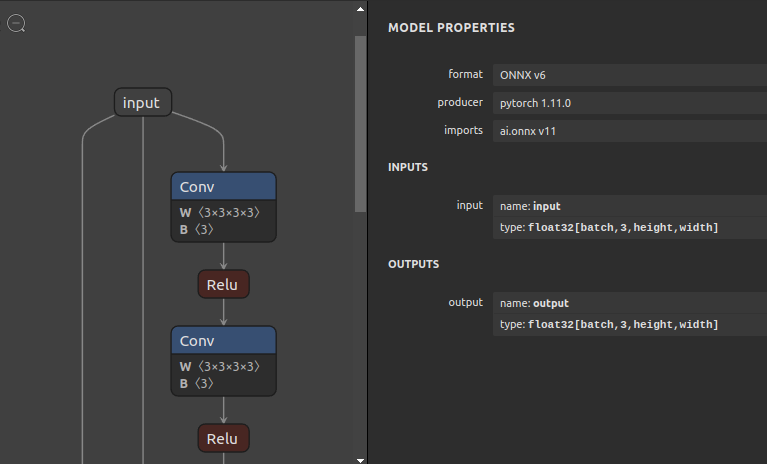

https://github.com/daquexian/onnx-simplifier/issues/178
$ pip install -U sit4onnx
$ sit4onnx \
--input_onnx_file_path hitnet_xl_sf_finalpass_from_tf_720x1280_cast.onnx \
--onnx_execution_provider tensorrt
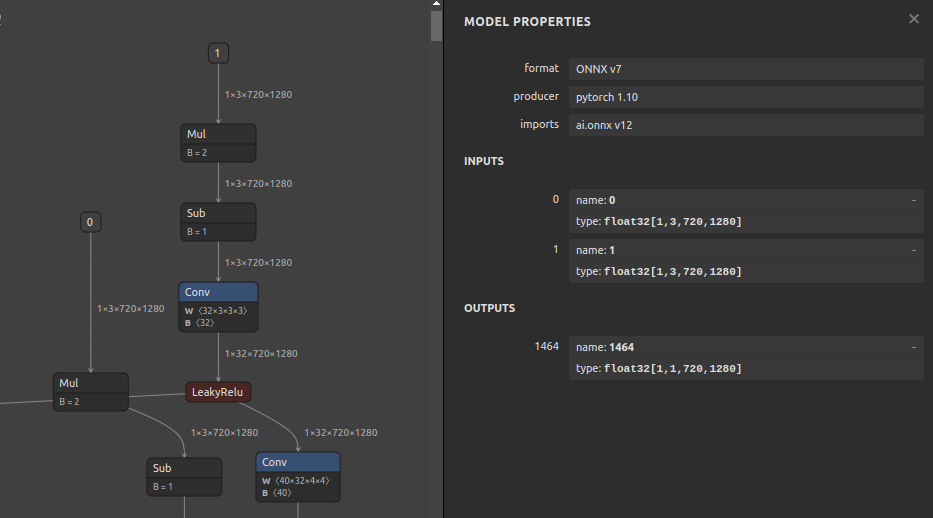

7. TensorRT Installation Example
export OS=ubuntu2204
export CUDAVER=11.8
export CUDNNVER=8.9
export TENSORRTVER=8.5.3
export PYCUDAVER=2022.2
export ONNXVER=1.14.0
export CUDA_HOME=/usr/local/cuda
export PATH=${PATH}:${CUDA_HOME}/bin
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:${CUDA_HOME}/lib64
# Install TensorRT
# https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html
sudo dpkg -i nv-tensorrt-local-repo-${OS}-${TENSORRTVER}-cuda-${CUDAVER}_1.0-1_amd64.deb \
&& sudo cp /var/nv-tensorrt-local-repo-${OS}-${TENSORRTVER}-cuda-${CUDAVER}/*-keyring.gpg /usr/share/keyrings/ \
&& sudo apt-get update \
&& sudo apt-get install -y --no-install-recommends \
tensorrt=${TENSORRTVER}.1-1+cuda${CUDAVER} \
tensorrt-dev=${TENSORRTVER}.1-1+cuda${CUDAVER} \
tensorrt-libs=${TENSORRTVER}.1-1+cuda${CUDAVER} \
uff-converter-tf=${TENSORRTVER}-1+cuda${CUDAVER} \
python3-libnvinfer-dev=${TENSORRTVER}-1+cuda${CUDAVER} \
python3-libnvinfer=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvparsers-dev=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvparsers8=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvonnxparsers-dev=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvonnxparsers8=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvinfer-samples=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvinfer-plugin-dev=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvinfer-plugin8=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvinfer-dev=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvinfer-bin=${TENSORRTVER}-1+cuda${CUDAVER} \
libnvinfer8=${TENSORRTVER}-1+cuda${CUDAVER} \
graphsurgeon-tf=${TENSORRTVER}-1+cuda${CUDAVER} \
onnx-graphsurgeon=${TENSORRTVER}-1+cuda${CUDAVER} \
libprotobuf-dev \
protobuf-compiler \
&& rm nv-tensorrt-local-repo-${OS}-${TENSORRTVER}-cuda-${CUDAVER}_1.0-1_amd64.deb \
&& cd /usr/src/tensorrt/samples/trtexec \
&& sudo make \
&& sudo apt clean
# Install onnx-tensorrt
cd ${HOME} \
&& git clone -b release/8.5-GA --recursive https://github.com/onnx/onnx-tensorrt onnx-tensorrt \
&& pushd onnx-tensorrt \
&& mkdir build \
&& pushd build \
&& cmake .. -DTENSORRT_ROOT=/usr/src/tensorrt \
&& make -j$(nproc) \
&& sudo make install \
&& popd \
&& popd \
&& pip install onnx==${ONNXVER} \
&& pip install pycuda==${PYCUDAVER} \
&& pushd onnx-tensorrt \
&& python setup.py install --user \
&& popd \
&& echo 'export CUDA_MODULE_LOADING=LAZY' >> ~/.bashrc \
&& echo 'export PATH=${PATH}:/usr/src/tensorrt/bin:${HOME}/onnx-tensorrt/build' >> ~/.bashrc \
&& source ~/.bashrc
8. Build onnxruntime-gpu for TensorRT
# Get the latest release version
git clone -b v1.15.1 https://github.com/microsoft/onnxruntime.git \
&& cd onnxruntime
# Check the version of TensorRT installed on the host PC
dpkg -l | grep TensorRT
ii graphsurgeon-tf 8.5.3-1+cuda11.8 amd64 GraphSurgeon for TensorRT package
ii libnvinfer-bin 8.5.3-1+cuda11.8 amd64 TensorRT binaries
ii libnvinfer-dev 8.5.3-1+cuda11.8 amd64 TensorRT development libraries and headers
ii libnvinfer-plugin-dev 8.5.3-1+cuda11.8 amd64 TensorRT plugin libraries
ii libnvinfer-plugin8 8.5.3-1+cuda11.8 amd64 TensorRT plugin libraries
ii libnvinfer-samples 8.5.3-1+cuda11.8 all TensorRT samples
ii libnvinfer8 8.5.3-1+cuda11.8 amd64 TensorRT runtime libraries
ii libnvonnxparsers-dev 8.5.3-1+cuda11.8 amd64 TensorRT ONNX libraries
ii libnvonnxparsers8 8.5.3-1+cuda11.8 amd64 TensorRT ONNX libraries
ii libnvparsers-dev 8.5.3-1+cuda11.8 amd64 TensorRT parsers libraries
ii libnvparsers8 8.5.3-1+cuda11.8 amd64 TensorRT parsers libraries
ii onnx-graphsurgeon 8.5.3-1+cuda11.8 amd64 ONNX GraphSurgeon for TensorRT package
ii python3-libnvinfer 8.5.3-1+cuda11.8 amd64 Python 3 bindings for TensorRT
ii python3-libnvinfer-dev 8.5.3-1+cuda11.8 amd64 Python 3 development package for TensorRT
ii tensorrt 8.5.3.1-1+cuda11.8 amd64 Meta package for TensorRT
ii tensorrt-dev 8.5.3.1-1+cuda11.8 amd64 Meta package for TensorRT development libraries
ii tensorrt-libs 8.5.3.1-1+cuda11.8 amd64 Meta package for TensorRT runtime libraries
ii uff-converter-tf 8.5.3-1+cuda11.8 amd64 UFF converter for TensorRT package
# Grant execution rights to scripts and install cmake
sudo chmod +x build.sh
pip install cmake --upgrade
# Build
./build.sh \
--config Release \
--cudnn_home /usr/lib/x86_64-linux-gnu/ \
--cuda_home /usr/local/cuda \
--use_tensorrt \
--use_cuda \
--tensorrt_home /usr/src/tensorrt/ \
--enable_pybind \
--build_wheel \
--parallel $(nproc) \
--compile_no_warning_as_error \
--skip_tests
# Check the path of the generated installer
find . -name "*.whl"
./build/Linux/Release/dist/onnxruntime_gpu-1.15.1-cp310-cp310-linux_x86_64.whl
# Install
pip uninstall onnxruntime onnxruntime-gpu
pip install ./build/Linux/Release/dist/onnxruntime_gpu-1.15.1-cp310-cp310-linux_x86_64.whl
9. Reference
- https://github.com/onnx/onnx/blob/main/docs/Operators.md
- https://docs.nvidia.com/deeplearning/tensorrt/onnx-graphsurgeon/docs/index.html
- https://github.com/NVIDIA/TensorRT/tree/main/tools/onnx-graphsurgeon
- https://github.com/PINTO0309/simple-onnx-processing-tools
- https://github.com/PINTO0309/PINTO_model_zoo
10. Issues
https://github.com/PINTO0309/simple-onnx-processing-tools/issues
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file sit4onnx-1.0.10.tar.gz.
File metadata
- Download URL: sit4onnx-1.0.10.tar.gz
- Upload date:
- Size: 13.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.23
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
075f3545a4f3f200cbdc2b7e993f0eef812a22142a182717ba0c085a9485a9c3
|
|
| MD5 |
b98b02e97c4c1937249c02a205c512f6
|
|
| BLAKE2b-256 |
b989e49f3ea38335ab8c34503dc9bd91319c654688df4c6402ce8cc4bec9c2fc
|
File details
Details for the file sit4onnx-1.0.10-py3-none-any.whl.
File metadata
- Download URL: sit4onnx-1.0.10-py3-none-any.whl
- Upload date:
- Size: 11.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.23
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e6ebb0e9cd79692ee53bfdb973ccd5282bdbbe5a71d3bfcfcf46e56ae4e39a48
|
|
| MD5 |
552b0cba628dbe13b861275f114bbfa0
|
|
| BLAKE2b-256 |
cedba0be70c6786b3c2e4f4a0b66976e7a3acfd95ef777977bf60d846871737f
|







