Visualization package for Spark NLP



Project description
spark-nlp-display
A library for the simple visualization of different types of Spark NLP annotations.
Supported Visualizations:
- Dependency Parser
- Named Entity Recognition
- Entity Resolution
- Relation Extraction
- Assertion Status
Complete Tutorial

https://github.com/JohnSnowLabs/spark-nlp-display/blob/main/tutorials/Spark_NLP_Display.ipynb
Requirements
- spark-nlp
- ipython
- svgwrite
- pandas
- numpy
Installation
pip install spark-nlp-display
How to use
Databricks
For all modules, pass in the additional parameter "return_html=True" in the display function and use Databrick's function displayHTML() to render visualization as explained below:
from sparknlp_display import NerVisualizer
ner_vis = NerVisualizer()
## To set custom label colors:
ner_vis.set_label_colors({'LOC':'#800080', 'PER':'#77b5fe'}) #set label colors by specifying hex codes
pipeline_result = ner_light_pipeline.fullAnnotate(text) ##light pipeline
#pipeline_result = ner_full_pipeline.transform(df).collect()##full pipeline
vis_html = ner_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
label_col='entities', #specify the entity column
document_col='document', #specify the document column (default: 'document')
labels=['PER'], #only allow these labels to be displayed. (default: [] - all labels will be displayed)
return_html=True)
displayHTML(vis_html)

Jupyter
To save the visualization as html, provide the export file path: save_path='./export.html' for each visualizer.
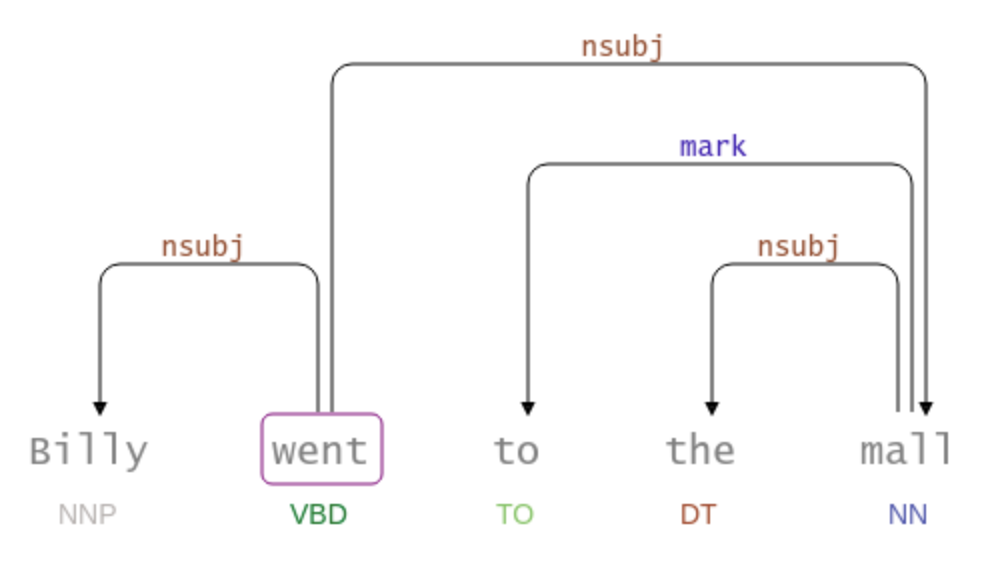
Dependency Parser
from sparknlp_display import DependencyParserVisualizer
dependency_vis = DependencyParserVisualizer()
pipeline_result = dp_pipeline.fullAnnotate(text)
#pipeline_result = dp_full_pipeline.transform(df).collect()##full pipeline
dependency_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe.
pos_col = 'pos', #specify the pos column
dependency_col = 'dependency', #specify the dependency column
dependency_type_col = 'dependency_type', #specify the dependency type column
save_path='./export.html' # optional - to save viz as html. (default: None)
)
Named Entity Recognition
from sparknlp_display import NerVisualizer
ner_vis = NerVisualizer()
pipeline_result = ner_light_pipeline.fullAnnotate(text)
#pipeline_result = ner_full_pipeline.transform(df).collect()##full pipeline
ner_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
label_col='entities', #specify the entity column
document_col='document', #specify the document column (default: 'document')
labels=['PER'], #only allow these labels to be displayed. (default: [] - all labels will be displayed)
save_path='./export.html' # optional - to save viz as html. (default: None)
)
## To set custom label colors:
ner_vis.set_label_colors({'LOC':'#800080', 'PER':'#77b5fe'}) #set label colors by specifying hex codes
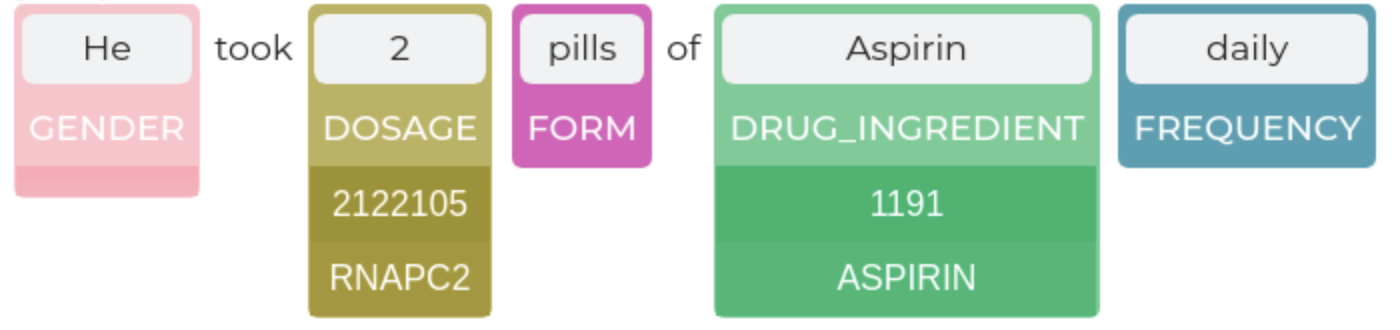
Entity Resolution
from sparknlp_display import EntityResolverVisualizer
er_vis = EntityResolverVisualizer()
pipeline_result = er_light_pipeline.fullAnnotate(text)
er_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
label_col='entities', #specify the ner result column
resolution_col = 'resolution',
document_col='document', #specify the document column (default: 'document')
save_path='./export.html' # optional - to save viz as html. (default: None)
)
## To set custom label colors:
er_vis.set_label_colors({'TREATMENT':'#800080', 'PROBLEM':'#77b5fe'}) #set label colors by specifying hex codes
Relation Extraction
from sparknlp_display import RelationExtractionVisualizer
re_vis = RelationExtractionVisualizer()
pipeline_result = re_light_pipeline.fullAnnotate(text)
re_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
relation_col = 'relations', #specify relations column
document_col = 'document', #specify document column
show_relations=True, #display relation names on arrows (default: True)
save_path='./export.html' # optional - to save viz as html. (default: None)
)

Assertion Status
from sparknlp_display import AssertionVisualizer
assertion_vis = AssertionVisualizer()
pipeline_result = ner_assertion_light_pipeline.fullAnnotate(text)
assertion_vis.display(pipeline_result[0],
label_col = 'entities', #specify the ner result column
assertion_col = 'assertion', #specify assertion column
document_col = 'document', #specify the document column (default: 'document')
save_path='./export.html' # optional - to save viz as html. (default: None)
)
## To set custom label colors:
assertion_vis.set_label_colors({'TREATMENT':'#008080', 'problem':'#800080'}) #set label colors by specifying hex codes

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file spark-nlp-display-5.0.tar.gz.
File metadata
- Download URL: spark-nlp-display-5.0.tar.gz
- Upload date:
- Size: 85.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
46faa77553d3eb3fc968eb434303752f7baf39b39b03f17cd0934466b6a86620
|
|
| MD5 |
c9951302ea8858ac8a19e46692cacd90
|
|
| BLAKE2b-256 |
9445c5b0fa0b31675946a13859fd2bad8a6816bdb08f30e64d8379820e67e409
|
File details
Details for the file spark_nlp_display-5.0-py3-none-any.whl.
File metadata
- Download URL: spark_nlp_display-5.0-py3-none-any.whl
- Upload date:
- Size: 95.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ede785f68cd4299d4a93e389d26be90eeb0e24372de99d30b107ad19464c87e0
|
|
| MD5 |
28ac92b19ddfff122e3a21d0db9b2b1b
|
|
| BLAKE2b-256 |
401e41eb41a6c69df8cb6a2906d7f44672118834af10cdb5b8f0f360e82ac988
|







