Jupyter Notebook & Lab extension to monitor Apache Spark jobs from a notebook
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Project description
SparkMonitor
SparkMonitor is a Jupyter extension for monitoring Apache Spark jobs launched from notebooks. It displays live Spark metrics directly in the notebook interface, making it easier to understand, debug, and profile Spark workloads as they run.
It supports JupyterLab and classic Jupyter Notebook with PySpark 3.x and 4.x.
About

|
+ |

|
= |

|
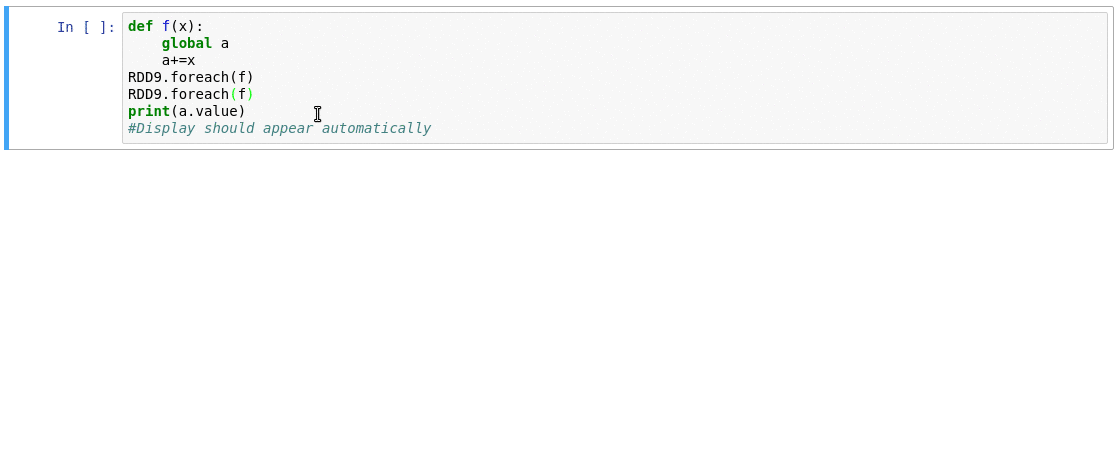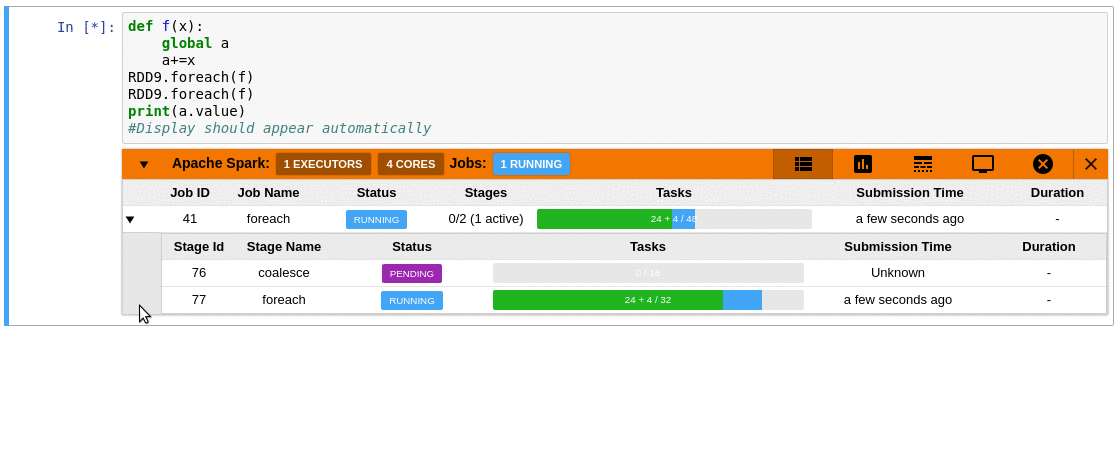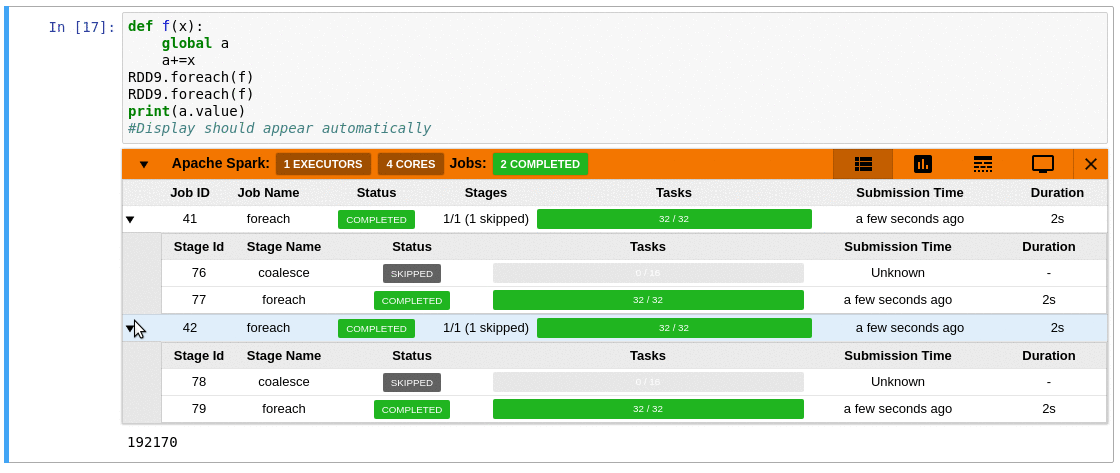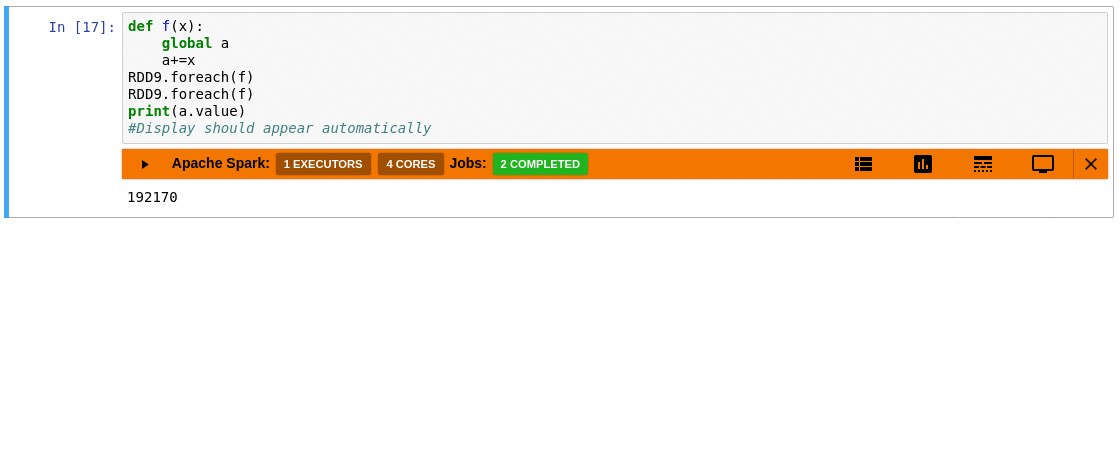
SparkMonitor adds an interactive monitoring panel below notebook cells that trigger Spark jobs, so you can inspect execution progress without leaving the notebook.
Requirements
- Python 3.x
- PySpark 3.x or 4.x
- JupyterLab 4.x or classic Jupyter Notebook 4.4.0 or later
- Spark Classic API mode
- SparkMonitor works with the traditional Spark driver model used by PySpark.
- It is not compatible with Spark Connect.
Features
- Live monitoring of Spark jobs launched from a notebook cell
- Job and stage table with progress bars and execution details
- Timeline view showing jobs, stages, and tasks over time
- Resource graphs for active tasks and executor core usage

|

|

|
Quick Start
Installation
Create and activate a virtual environment:
python -m venv venv
source venv/bin/activate
Install SparkMonitor together with PySpark and a notebook frontend.
For JupyterLab
pip install sparkmonitor pyspark jupyterlab
Enable the SparkMonitor IPython kernel extension:
ipython profile create
echo "c.InteractiveShellApp.extensions.append('sparkmonitor.kernelextension')" >> "$(ipython profile locate default)/ipython_kernel_config.py"
This only needs to be done once per IPython profile.
Using SparkMonitor in a Notebook
To use SparkMonitor, create your Spark session with the SparkMonitor listener enabled.
This requires two Spark configurations:
| Configuration | Purpose |
|---|---|
spark.extraListeners |
Registers the SparkMonitor listener that collects Spark job metrics |
spark.driver.extraClassPath |
Points to the SparkMonitor listener JAR bundled with the sparkmonitor package |
Example with a manually specified listener JAR path
If you already know the exact path to the matching SparkMonitor
listener JAR in your current environment, you can set
spark.driver.extraClassPath directly:
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.config(
"spark.extraListeners",
"sparkmonitor.listener.JupyterSparkMonitorListener",
)
.config(
"spark.driver.extraClassPath",
# Put the path to the matching SparkMonitor listener JAR here.
"venv/lib/python3.13/site-packages/sparkmonitor/listener_spark4_2.13.jar",
)
.getOrCreate()
)
Example with automatic listener JAR detection
The most robust approach is to resolve the listener JAR path
dynamically from the installed Python package instead of hardcoding the
full environment path. The example below first checks SPARK_HOME and
then falls back to the pyspark package layout used by
pip install pyspark, where SPARK_HOME is often not set:
import os
from pathlib import Path
import pyspark
import sparkmonitor
from pyspark.sql import SparkSession
def iter_spark_jar_dirs() -> list[Path]:
candidates = []
spark_home = os.environ.get("SPARK_HOME")
if spark_home:
candidates.append(Path(spark_home) / "jars")
candidates.append(Path(pyspark.__file__).resolve().parent / "jars")
return [path for path in candidates if path.exists()]
def resolve_listener_jar(sparkmonitor_dir: Path) -> Path:
for jars_dir in iter_spark_jar_dirs():
for jar in jars_dir.glob("spark-core_*.jar"):
# spark-core_2.13-3.5.8.jar => scala=2.13, spark_major=3
scala_ver, spark_ver = jar.name.split("_")[1].split("-")[:2]
spark_major = spark_ver.split(".")[0]
if spark_major == "3" and scala_ver == "2.12":
return sparkmonitor_dir / "listener_spark3_2.12.jar"
if spark_major == "3" and scala_ver == "2.13":
return sparkmonitor_dir / "listener_spark3_2.13.jar"
if spark_major == "4" and scala_ver == "2.13":
return sparkmonitor_dir / "listener_spark4_2.13.jar"
raise RuntimeError(
"Could not detect Spark/Scala version from SPARK_HOME or the pyspark installation"
)
sparkmonitor_dir = Path(sparkmonitor.__file__).resolve().parent
listener_jar = resolve_listener_jar(sparkmonitor_dir)
spark = (
SparkSession.builder.config(
"spark.extraListeners",
"sparkmonitor.listener.JupyterSparkMonitorListener",
)
.config("spark.driver.extraClassPath", str(listener_jar))
.getOrCreate()
)
Important
The correct listener JAR depends on:
- the location of your Python environment
- your Spark major version and Scala version
- how Spark is installed (
SPARK_HOMEvspip install pyspark)
You can inspect the installed package location with:
import sparkmonitor
print(sparkmonitor.__path__)
Then locate the corresponding listener JAR in that package directory:
listener_spark3_2.12.jarfor Spark 3 + Scala 2.12listener_spark3_2.13.jarfor Spark 3 + Scala 2.13listener_spark4_2.13.jarfor Spark 4 + Scala 2.13
If needed, you can also build the listener JAR yourself with sbt, as
described in the development section below.
Development
To work on SparkMonitor locally:
# Install the package in editable mode
pip install -e .
# Build the frontend (see package.json for available scripts)
yarn run build:<action>
# Link the JupyterLab extension into your local Jupyter environment
jupyter labextension develop --overwrite .
# Watch frontend files for changes
yarn run watch
# Build the Spark listener JARs
cd scalalistener_spark3 # Spark 3 / Scala 2.12 and 2.13
sbt +package
cd ../scalalistener_spark4 # Spark 4 / Scala 2.13
sbt package
Troubleshooting
SparkMonitor panel does not appear
Check the following:
sparkmonitoris installed in the same Python environment as your notebook kernelpysparkis installedjupyterlabornotebookis installed- the IPython kernel extension is enabled
- your Spark session includes
spark.extraListeners spark.driver.extraClassPathpoints to a valid listener JAR- you are using Spark Classic, not Spark Connect
Wrong listener JAR selected
The listener JAR must match both your Spark major version and Scala version:
Spark 3 + Scala 2.12 -> listener_spark3_2.12.jar
Spark 3 + Scala 2.13 -> listener_spark3_2.13.jar
Spark 4 + Scala 2.13 -> listener_spark4_2.13.jar
Using the wrong listener JAR may prevent the listener from loading correctly.
Hardcoded virtual environment path does not work
Avoid hardcoding paths when possible. Environment-specific paths vary across systems, Python versions, and virtual environments. The dynamic path resolution example above is usually more portable.
SPARK_HOME is not set
This is expected in some setups, especially when Spark comes from
pip install pyspark. In that case, use the pyspark package location
to find the bundled Spark JARs instead of assuming SPARK_HOME/jars
exists.
Project History
- The first version of SparkMonitor was written by krishnan-r as a Google Summer of Code project with the SWAN Notebook Service team at CERN.
- Further fixes and improvements were made by the CERN team and community contributors in swan-cern/jupyter-extensions/tree/master/SparkMonitor.
- Jafer Haider updated the extension for JupyterLab during an internship at Yelp.
- Work from the jupyterlab-sparkmonitor fork was later merged into this repository so that both JupyterLab and Jupyter Notebook are supported from a single package.
- Ongoing maintenance and development continue through the SWAN team at CERN and the community.
References
- PyPI package: sparkmonitor
- Releases: swan-cern/sparkmonitor releases
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file sparkmonitor-3.3.0.tar.gz.
File metadata
- Download URL: sparkmonitor-3.3.0.tar.gz
- Upload date:
- Size: 3.5 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
df94a90579effc61b35a39c320319d1f34c64baf6848658201ace80c07178cf9
|
|
| MD5 |
6659c5017d4d8dfdf273cc2cfcf2baa6
|
|
| BLAKE2b-256 |
29ed306503e3a343c496bc680146cd58f1cc70da76846b3d0aa591528a1d7192
|
Provenance
The following attestation bundles were made for sparkmonitor-3.3.0.tar.gz:
Publisher:
publish.yml on swan-cern/sparkmonitor
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
sparkmonitor-3.3.0.tar.gz -
Subject digest:
df94a90579effc61b35a39c320319d1f34c64baf6848658201ace80c07178cf9 - Sigstore transparency entry: 1203018110
- Sigstore integration time:
-
Permalink:
swan-cern/sparkmonitor@c4d762565f7b055ee99758aad74a763bd6f48408 -
Branch / Tag:
refs/tags/v3.3.0 - Owner: https://github.com/swan-cern
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@c4d762565f7b055ee99758aad74a763bd6f48408 -
Trigger Event:
push
-
Statement type:
File details
Details for the file sparkmonitor-3.3.0-py3-none-any.whl.
File metadata
- Download URL: sparkmonitor-3.3.0-py3-none-any.whl
- Upload date:
- Size: 3.4 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
48751a8fdd223595a57f41aa39b8534b8749db810f1ecaa1410f180084f6354b
|
|
| MD5 |
bec76bc39f6e6419f87b94449d70cdc5
|
|
| BLAKE2b-256 |
265bc2ab7d66684940492bf3678f7f4590ee4e65bae335cc734ac754f8402d5b
|
Provenance
The following attestation bundles were made for sparkmonitor-3.3.0-py3-none-any.whl:
Publisher:
publish.yml on swan-cern/sparkmonitor
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
sparkmonitor-3.3.0-py3-none-any.whl -
Subject digest:
48751a8fdd223595a57f41aa39b8534b8749db810f1ecaa1410f180084f6354b - Sigstore transparency entry: 1203018221
- Sigstore integration time:
-
Permalink:
swan-cern/sparkmonitor@c4d762565f7b055ee99758aad74a763bd6f48408 -
Branch / Tag:
refs/tags/v3.3.0 - Owner: https://github.com/swan-cern
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@c4d762565f7b055ee99758aad74a763bd6f48408 -
Trigger Event:
push
-
Statement type:







