Stroke and rule analyzer for stenography

Project description
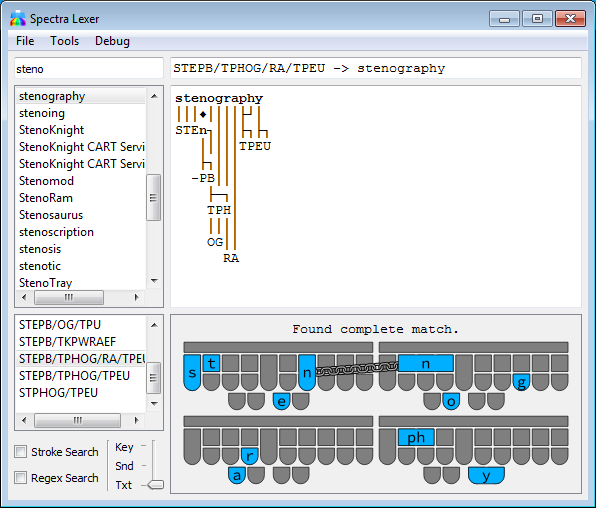
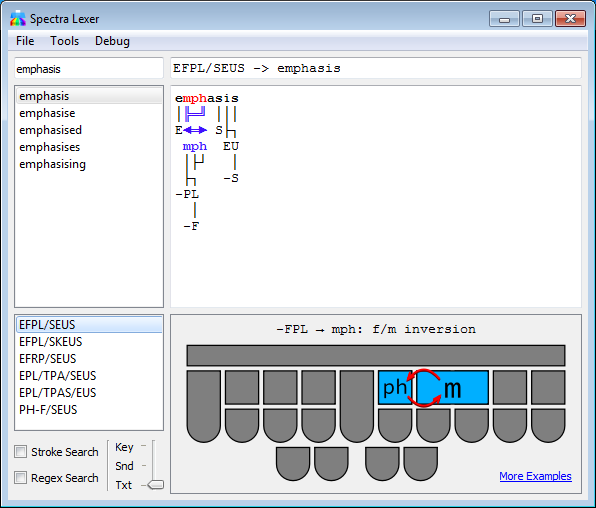
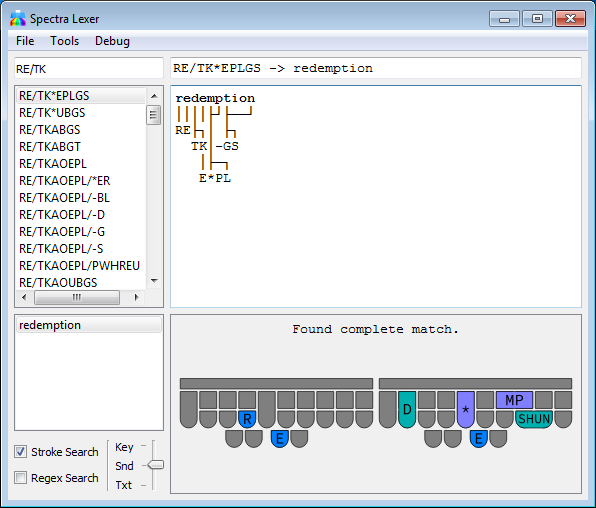
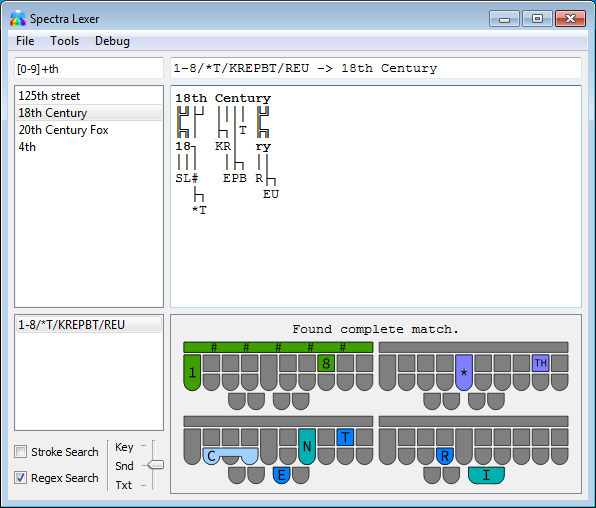
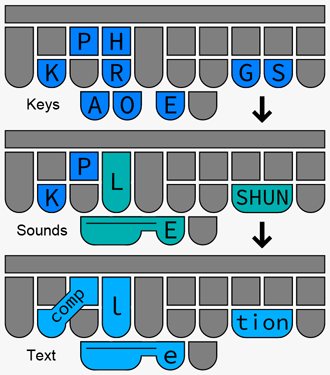
The Spectra Steno Lexer is an experimental tool for analyzing and matching patterns of steno keys against the text they produce using various rules from steno theories (mostly Plover theory). It also has advanced search functions for steno dictionaries as well as a highly capable SVG generator for steno board diagrams.
Installation
Spectra was originally designed as a plugin for Plover. If you have installed the latest binary release of Plover (4.0.0.dev8 as of this writing), the plugins manager should be able to find this program in the PyPI database and set it up automatically for you.
If you have built and installed Plover from source, it is not likely to have the plugins manager by default. In this case it is possible to install Spectra through pip like any other Python package. Plover searches through all available Python paths to find plugins; so long as it ends up in the same general place that Plover looks for its other dependencies, it should find it just fine.
To run this software on its own from source, you must have a correctly installed Python distribution (3.6 or greater). Download or clone the source into a new directory, change to that directory in a terminal and type:
python3 setup.py install
This will install it to your Python distribution with all features.
Operation
When opened from the main toolbar in Plover, Spectra will automatically load Plover’s dictionaries for manual searching and will also attempt to analyze strokes sent from Plover as you type. On first start, you will be asked if you want to create an index of steno rules from your Plover dictionary. With an index, not only will you be able to see the rules that make up any given translation, but you will also be able to search for other translations that use the same rule from a link on the steno board diagram. The initial index is restricted in size in order to keep load times down, but if you want rule comparisons against more complicated words, you can create a larger index from the Tools menu if you want. Please be aware that this isn’t without tradeoffs; a large index will increase startup time significantly.
The most advanced stuff is available only in the console. The following supported modes are:
spectra_lexer gui
Runs the program as a standalone PyQt GUI desktop application. This operates identically to the plugin in all respects except that it cannot decipher strokes in real-time. By default, the program will look for your Plover dictionaries in the default user app data directory for your platform. It may not find them if you have them somewhere else, or have a strange user configuration. In any case, you can load dictionaries manually from the menu bar.
spectra_lexer http [--http-addr=IP_ADDRESS] [--http-port=PORT]
Runs the program as an HTTP AJAX web service, bound to IP_ADDRESS:PORT (default is localhost:80). While the service is running, you may access the web app from the root path (most likely http://127.0.0.1/ in your web browser will work). It does require elevated privileges to bind to network sockets, but as the service is composed of custom Python code, most port scanners and spambots won’t even know what to do with it. No security guarantees are made (but this is Python, so what did you expect?).
spectra_lexer index [--translations=FILE_IN1 [FILE_IN2 ...]] [--index=FILE_OUT] [--size=SIZE]
Creates a JSON rule examples index from JSON steno translations. This is used to generate the lists of translations found when you click the “More Examples” link. SIZE is a number between 1-20, with 20 including every possible translation that the program could find for any given rule.
spectra_lexer console
Starts an interactive Python console with Spectra’s components directly exposed as top-level objects. Some examination of the Python source may be necessary to see everything that can be done.
Configuration
Add the switch -h in front of any console command from the above section to see all available command-line options. In addition, the program reads/writes the following files in the user home directory under spectra_lexer’s app data folder:
config.cfg - Contains all user configuration options that aren’t command-line switches.
index.json - JSON rule examples index. Required for “More Examples” functionality.
status.log - Log of all exceptions (and web traffic in HTTP mode). May be useful for troubleshooting errors.
Anything that isn’t a command-line switch is usually configured from the menu bar in the desktop app. The following options may be manually activated by users of the HTTP service by adding them in the URL query string:
graph_compressed_layout=0 - Generate graphs with items laid out in a longer, cascaded manner.
graph_compatibility_mode=1 - Generate graphs with explicitly forced monospacing using HTML tables.
More Details
This software is currently experimental with many rules unaccounted for, so do not rely on it to figure out the rules of stenography with 100% accuracy. Depending on the config setting, if it cannot match every single steno key to letters in the word, it may not return a result at all (to avoid guessing wrong) or may return an incomplete guess on the first part of the word. Inversions and asterisks are particularly troublesome here; inversions of steno order violate the strict left-to-right parsing that lexers rely on, and oftentimes there is not enough context to figure out the meaning of an asterisk from just a stroke and the word it makes in the absence of other information. Briefs are often constructed by keeping only the most important parts or sounds of a word, and Spectra can usually match these, but briefs relying on strange phonetics or arbitrary sequences of keys simply cannot be matched without pre-programmed custom rules (which are included for some of the most common briefs, but not many).
When searching from the lookup tool, if a word is chosen and there is more than one stroke entry for it, the lexer will analyze each one and select the one that has the best possibility of being “correct” (i.e. not a misstroke). This choice is based on, in order of importance: the number of steno keys matched to rules, the number of letters those rules cover, the number of “unusual” rules involved, and if all else fails, the total number of keys in the stroke.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file spectra_lexer-16.1.0.tar.gz.
File metadata
- Download URL: spectra_lexer-16.1.0.tar.gz
- Upload date:
- Size: 201.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.3.1 pkginfo/1.5.0.1 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5384a41c3eabf90785d696e9162ba2cc9272306b51ae47006c8b1a2067f4722a
|
|
| MD5 |
183f3a3f7ac759f99e66b55bfa52a03e
|
|
| BLAKE2b-256 |
3ba2e9c0ef96aaf5362f147526c65d8ffc1214295d7572d9b2910526271f0add
|
File details
Details for the file spectra_lexer-16.1.0-py3-none-any.whl.
File metadata
- Download URL: spectra_lexer-16.1.0-py3-none-any.whl
- Upload date:
- Size: 230.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.3.1 pkginfo/1.5.0.1 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
77cf503d9e4228cac56034c20dbc37a2284a547140a6760e21044ecb8530c41f
|
|
| MD5 |
0ec23b1ae21e640d6c7b023e91236d5e
|
|
| BLAKE2b-256 |
a2adc22bc9d53cc39c993707dcd5ccbc42a41d446bba4d9739e57b39bc4564d0
|







