A Scalable Framework for Unsupervised Outlier Detection (Anomaly Detection)

Project description
Deployment & Documentation & Stats






Build Status & Coverage & Maintainability & License



News: SUOD is now integrated into PyOD. It can be easily invoked in PyOD by following the SUOD example. In a nutshell, we could easily initialize a few outlier detectors and then use SUOD for collective training and prediction!
from pyod.models.suod import SUOD
# initialized a group of outlier detectors for acceleration
detector_list = [LOF(n_neighbors=15), LOF(n_neighbors=20),
LOF(n_neighbors=25), LOF(n_neighbors=35),
COPOD(), IForest(n_estimators=100),
IForest(n_estimators=200)]
# decide the number of parallel process, and the combination method
# then clf can be used as any outlier detection model
clf = SUOD(base_estimators=detector_list, n_jobs=2, combination='average',
verbose=False)Background: Outlier detection (OD) is a key data mining task for identifying abnormal objects from general samples with numerous high-stake applications including fraud detection and intrusion detection. Due to the lack of ground truth labels, practitioners often have to build a large number of unsupervised models that are heterogeneous (i.e., different algorithms and hyperparameters) for further combination and analysis with ensemble learning, rather than relying on a single model. However, this yields severe scalability issues on high-dimensional, large datasets.
SUOD (Scalable Unsupervised Outlier Detection) is an acceleration framework for large-scale unsupervised heterogeneous outlier detector training and prediction. It focuses on three complementary aspects to accelerate (dimensionality reduction for high-dimensional data, model approximation for complex models, and execution efficiency improvement for taskload imbalance within distributed systems), while controlling detection performance degradation.
Since its inception in Sep 2019, SUOD has been successfully used in various academic researches and industry applications with more than 700,000 downloads, including PyOD [2] and IQVIA medical claim analysis.
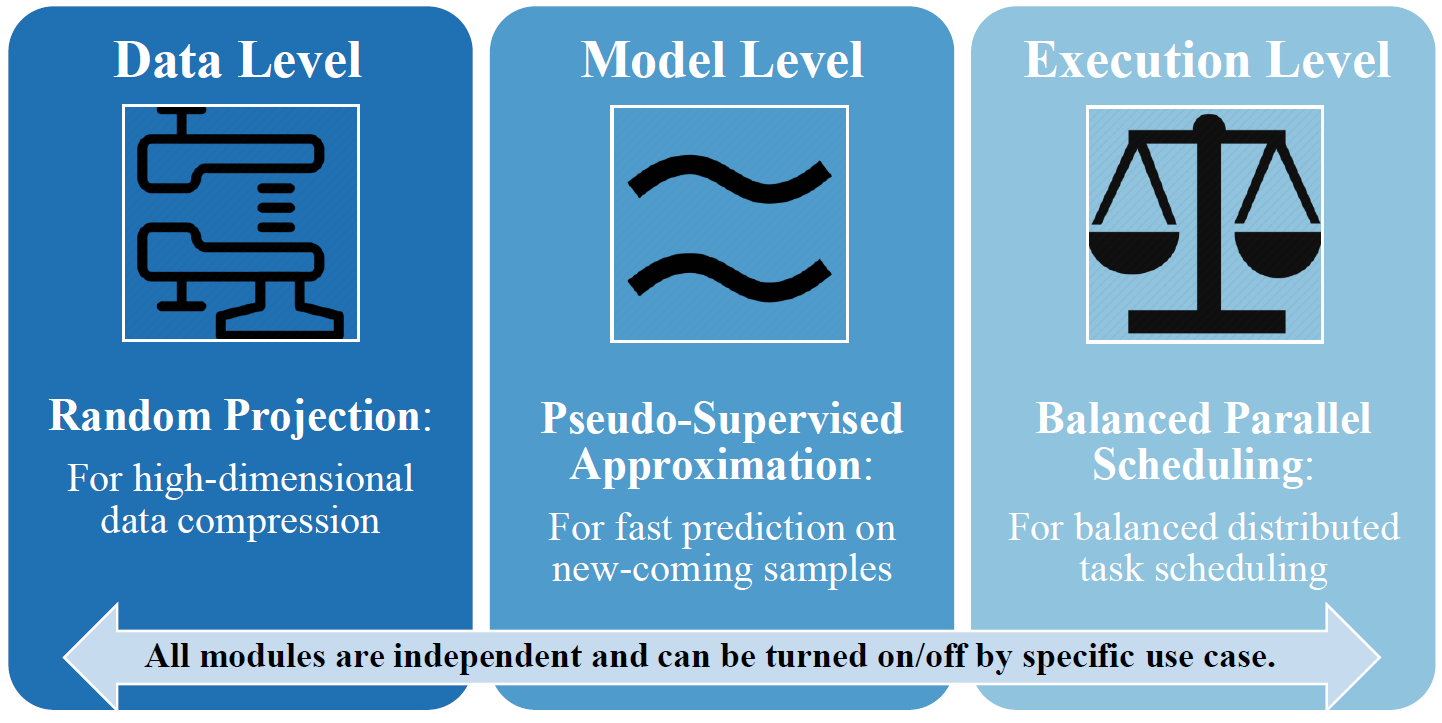
SUOD is featured for:
Unified APIs, detailed documentation, and examples for the easy use.
Optimized performance with JIT and parallelization when possible, using numba and joblib.
Fully compatible with the models in PyOD.
Customizable modules and flexible design: each module may be turned on/off or totally replaced by custom functions.
Roadmap:
Provide more choices of distributed schedulers (adapted for SUOD), e.g., batch sampling, Sparrow (SOSP’13), Pigeon (SoCC’19) etc.
Enable the flexibility of selecting data projection methods.
API Demo:
from suod.models.base import SUOD
# initialize a set of base outlier detectors to train and predict on
base_estimators = [
LOF(n_neighbors=5, contamination=contamination),
LOF(n_neighbors=15, contamination=contamination),
LOF(n_neighbors=25, contamination=contamination),
HBOS(contamination=contamination),
PCA(contamination=contamination),
OCSVM(contamination=contamination),
KNN(n_neighbors=5, contamination=contamination),
KNN(n_neighbors=15, contamination=contamination),
KNN(n_neighbors=25, contamination=contamination)]
# initialize a SUOD model with all features turned on
model = SUOD(base_estimators=base_estimators, n_jobs=6, # number of workers
rp_flag_global=True, # global flag for random projection
bps_flag=True, # global flag for balanced parallel scheduling
approx_flag_global=False, # global flag for model approximation
contamination=contamination)
model.fit(X_train) # fit all models with X
model.approximate(X_train) # conduct model approximation if it is enabled
predicted_labels = model.predict(X_test) # predict labels
predicted_scores = model.decision_function(X_test) # predict scores
predicted_probs = model.predict_proba(X_test) # predict outlying probabilityThe corresponding paper is published in Conference on Machine Learning Systems (MLSys). See https://mlsys.org/ for more information.
If you use SUOD in a scientific publication, we would appreciate citations to the following paper:
@inproceedings{zhao2021suod,
title={SUOD: Accelerating Large-scale Unsupervised Heterogeneous Outlier Detection},
author={Zhao, Yue and Hu, Xiyang and Cheng, Cheng and Wang, Cong and Wan, Changlin and Wang, Wen and Yang, Jianing and Bai, Haoping and Li, Zheng and Xiao, Cao and others},
journal={Proceedings of Machine Learning and Systems},
year={2021}
}
Zhao, Y., Hu, X., Cheng, C., Wang, C., Wan, C., Wang, W., Yang, J., Bai, H., Li, Z., Xiao, C. and Wang, Y., 2021. SUOD: Accelerating Large-scale Unsupervised Heterogeneous Outlier Detection. Proceedings of Machine Learning and Systems (MLSys).
Table of Contents:
Installation
It is recommended to use pip for installation. Please make sure the latest version is installed, as suod is updated frequently:
pip install suod # normal install
pip install --upgrade suod # or update if needed
pip install --pre suod # or include pre-release version for new featuresAlternatively, you could clone and run setup.py file:
git clone https://github.com/yzhao062/suod.git
cd suod
pip install .Required Dependencies:
Python 3.8+
joblib
numpy>=1.13
pandas (optional for building the cost forecast model)
pyod
scipy>=0.19.1
scikit_learn>=1.0
API Cheatsheet & Reference
Full API Reference: (https://suod.readthedocs.io/en/latest/api.html).
fit(X, y): Fit estimator. y is optional for unsupervised methods.
approximate(X): Use supervised models to approximate unsupervised base detectors. Fit should be invoked first.
predict(X): Predict on a particular sample once the estimator is fitted.
predict_proba(X): Predict the probability of a sample belonging to each class once the estimator is fitted.
Examples
All three modules can be executed separately and the demo codes are in /examples/module_examples/{M1_RP, M2_BPS, and M3_PSA}. For instance, you could navigate to /M1_RP/demo_random_projection.py. Demo codes all start with “demo_*.py”.
The examples for the full framework can be found under /examples folder; run “demo_base.py” for a simplified example. Run “demo_full.py” for a full example.
It is noted the best performance may be achieved with multiple cores available.
Model Save & Load
SUOD takes a similar approach of sklearn regarding model persistence. See model persistence for clarification.
In short, we recommend to use joblib or pickle for saving and loading SUOD models. See “examples/demo_model_save_load.py” for an example. In short, it is simple as below:
from joblib import dump, load
# save the fitted model
dump(model, 'model.joblib')
# load the model
model = load('model.joblib')More to come… Last updated on Jan 14th, 2021.
Feel free to star and watch for the future update :)
References
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file suod-0.1.4.tar.gz.
File metadata
- Download URL: suod-0.1.4.tar.gz
- Upload date:
- Size: 172.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6ed58b7b1b1a97930d10a5a402705b851829eba112240444fcff89b36863cb56
|
|
| MD5 |
c0d9092946a1de712ecc77aa09ff07ec
|
|
| BLAKE2b-256 |
8335e8fe2a2d265d4cbbe6529b183d392e103a9b48574af3423f4a4b885efe13
|







