Text Machina: Seamless Generation of Machine-Generated Text Datasets

Project description





Unifying strategies to build MGT datasets in a single framework

- 🔎 Detection: detect whether a text has been generated by an LLM.
- 🕵️♂️ Attribution: identify what LLM has generated a text.
- 🚧 Boundary detection: find the boundary between human and generated text.
- 🎨 Mixcase: ascertain whether specific text spans are human-written or generated by LLMs.
-
🦜 LLM integrations: easily integrates any LLM provider. Currently,
-
✍️ Prompt templating: just write your prompt template with placeholders and let
-
🔒 Constrained decoding: automatically infer LLM decoding hyper-parameters from the human texts to improve the quality and reduce the biases of your MGT datasets. See constrainers to implement your own constrainers.
-
🛠️ Post-processing: post-process functions aimed to improve the quality of any MGT dataset and prevent common biases and artifacts. See postprocessing to add new postprocess functions.
-
🌈 Bias mitigation:
-
📊 Dataset exploration: explore the generated datasets and quantify its quality with a set of metrics. See metrics and interactive to implement your own metrics and visualizations.
The following diagram depicts the

🔧 Installation
You can install all the dependencies with pip:
pip install text-machina[all]
or just with specific dependencies for an specific LLM provider or development dependencies (see setup.py):
pip install text-machina[anthropic,dev]
You can also install directly from source:
pip install .[all]
If you're planning to modify the code for specific use cases, you can install
pip install -e .[dev]
👀 Quick Tour
Once installed, you are ready to use
📟 Using the CLI
The first step is to define a YAML configuration file or a directory tree containing YAML files. Read the examples/learning files to learn how to define configuration using different providers and extractors for different tasks. Take a look to examples/use_cases to see configurations for specific use cases.
Then, we can call the explore and generate endpoints of
text-machina explore --config-path etc/examples/xsum_gpt-3-5-turbo-instruct_openai.yaml \
--task-type detection \
--metrics-path etc/metrics.yaml \
--max-generations 10
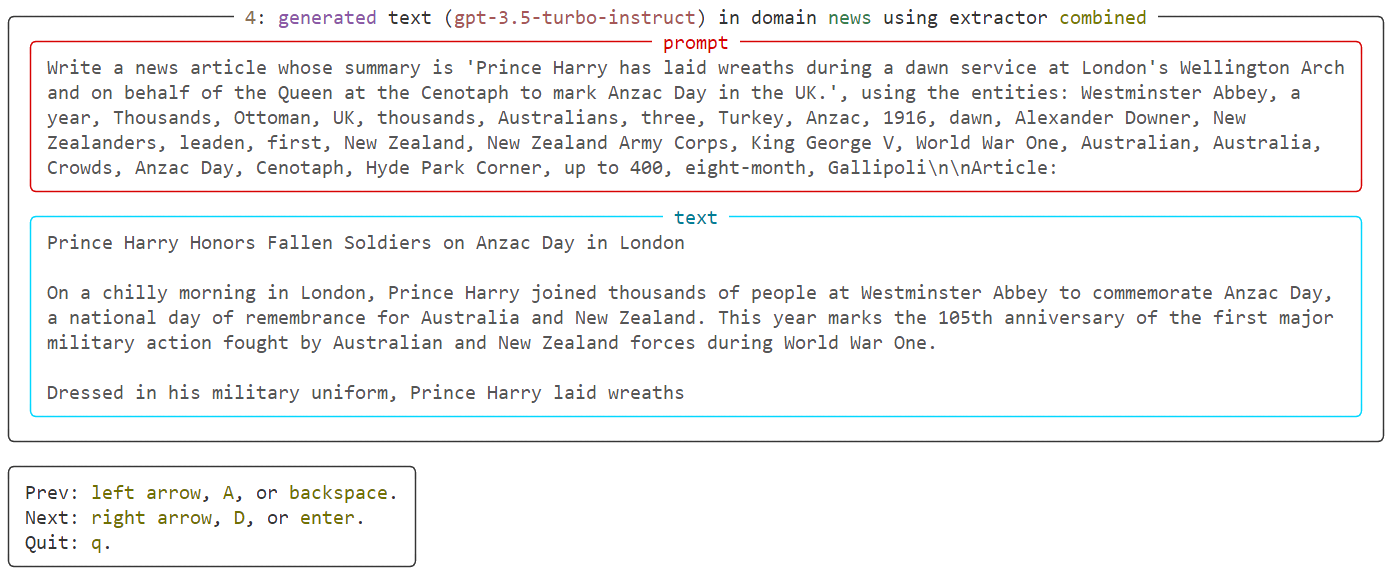
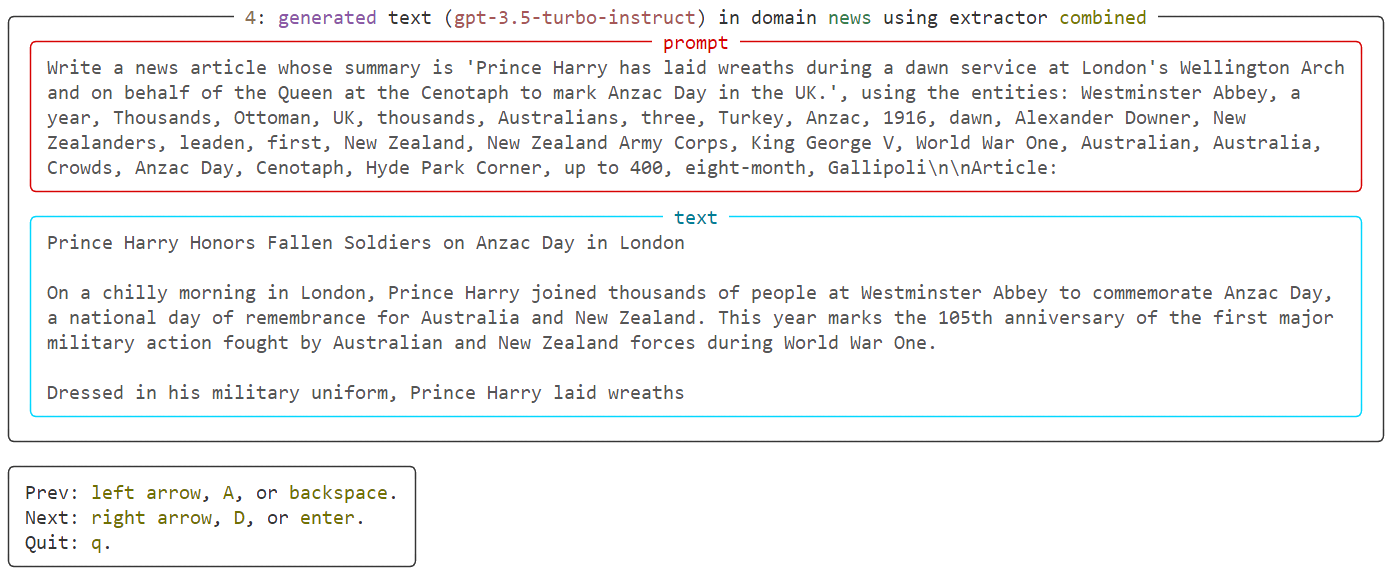
Great! Our dataset seems to look great, no artifacts, no biases, and high-quality text using this configuration. Let's now generate a whole dataset for MGT detection using that config file. The generate endpoint allows you to do that:
text-machina generate --config-path etc/examples/xsum_gpt-3-5-turbo-instruct_openai.yaml \
--task-type detection
A run name will be assigned to your execution and --run-name <run-name> to recover the progress and continue generating your dataset.
👩💻 Programmatically
You can also use
from text_machina import get_generator
from text_machina import Config, InputConfig, ModelConfig
input_config = InputConfig(
domain="news",
language="en",
quantity=10,
random_sample_human=True,
dataset="xsum",
dataset_text_column="document",
dataset_params={"split": "test"},
template=(
"Write a news article whose summary is '{summary}'"
"using the entities: {entities}\n\nArticle:"
),
extractor="combined",
extractors_list=["auxiliary.Auxiliary", "entity_list.EntityList"],
max_input_tokens=256,
)
model_config = ModelConfig(
provider="openai",
model_name="gpt-3.5-turbo-instruct",
api_type="COMPLETION",
threads=8,
max_retries=5,
timeout=20,
)
generation_config = {"temperature": 0.7, "presence_penalty": 1.0}
config = Config(
input=input_config,
model=model_config,
generation=generation_config,
task_type="detection",
)
generator = get_generator(config)
dataset = generator.generate()
🛠️ Supported tasks

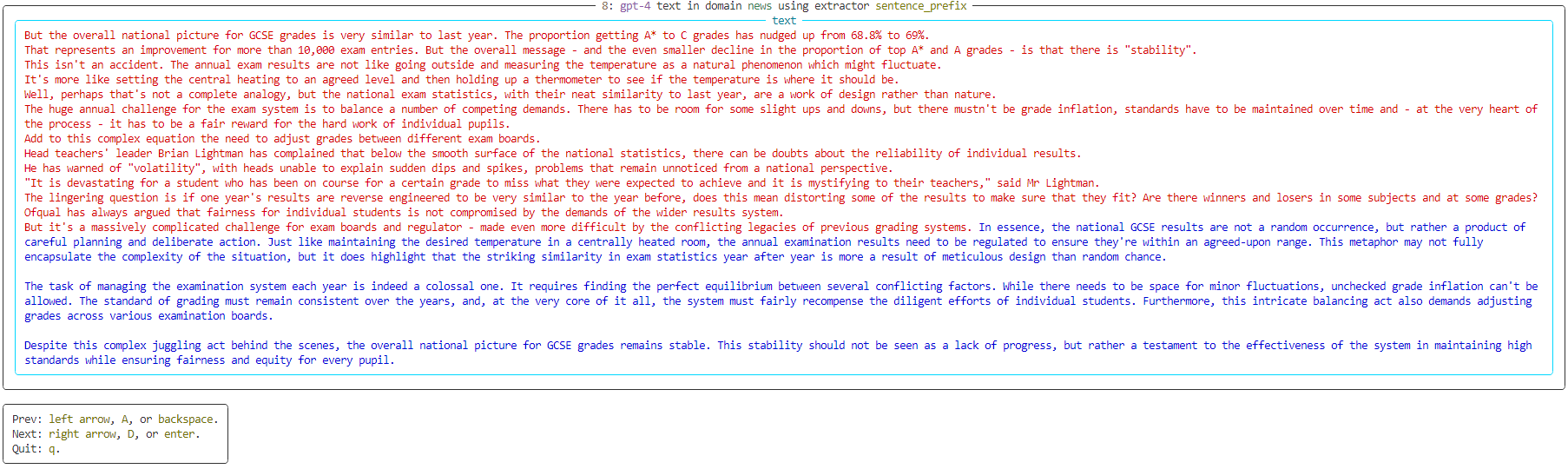
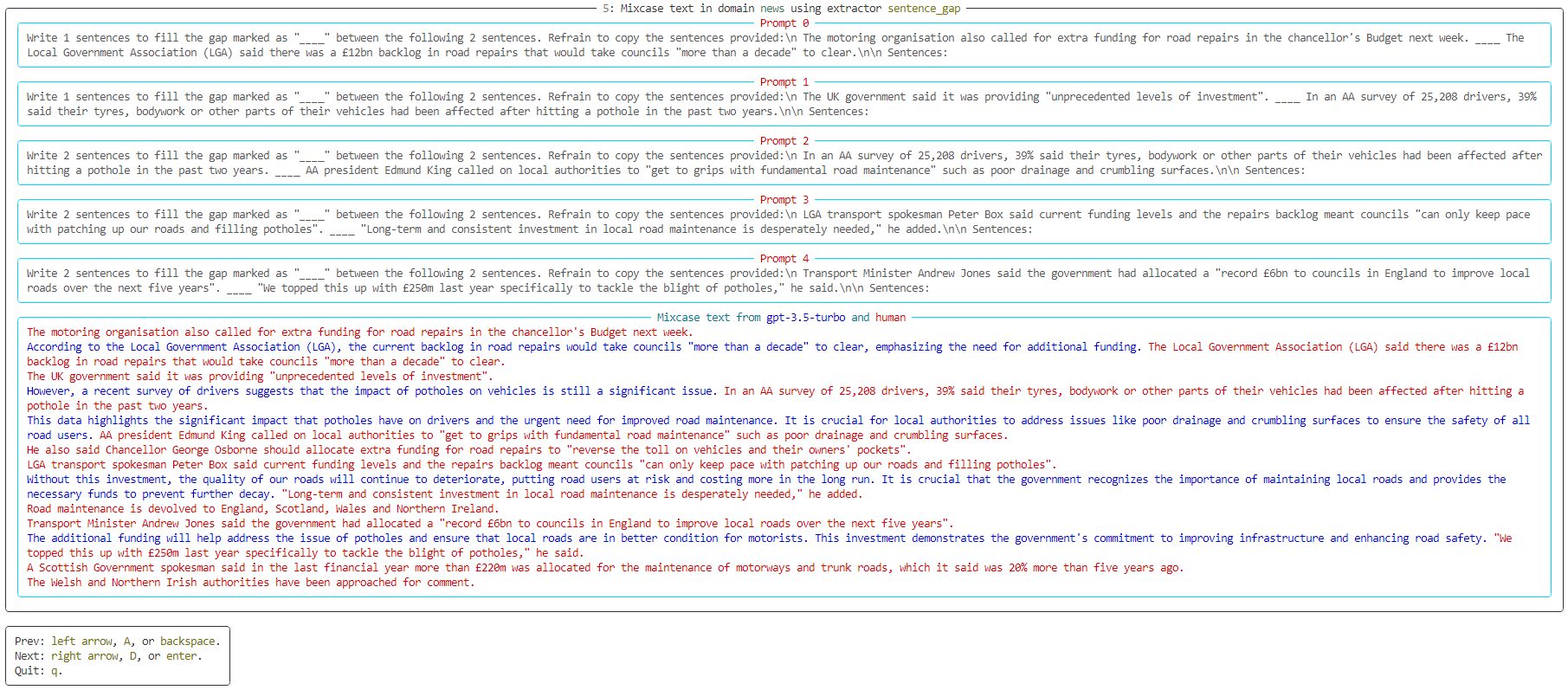

However, the users can build datasets for other tasks not included in
🔄 Common Use Cases
There is a set of common use cases with
| Use case | Command |
|---|---|
| Explore a dataset of 10 samples for MGT detection and show metrics | text-machina explore \ |
| Explore an existing dataset for MGT detection and show metrics | text-machina explore \ |
| Generate a dataset for MGT detection | text-machina generate \ |
| Generate a dataset for MGT attribution | text-machina generate \ |
| Generate a dataset for boundary detection | text-machina generate \ |
| Generate a dataset for mixcase detection | text-machina generate \ |
| Generate a dataset for MGT detection using config files in a directory tree | text-machina generate \ |
💾 Caching
--run-name <run-name> to continue from interrupted runs.
The default cache dir used by /tmp/text_machina_cache.
It can be modified by setting TEXT_MACHINA_CACHE_DIR to a different path.
⚠️ Notes and Limitations
-
Although you can use any kind of extractor to build boundary detection datasets, it is highly recommended to use the sentence_prefix or word_prefix extractors with a random number of sentences/words to avoid biases that lead boundary detection models to just count sentences or words.
-
-
Generating multilingual datasets is not well supported yet. At this moment, we recommend to generate independent datasets for each language and combine them together out of
-
Generating machine-generated code datasets is not well supported yet.
📖 Citation
@misc{sarvazyan2024textmachina,
title={TextMachina: Seamless Generation of Machine-Generated Text Datasets},
author={Areg Mikael Sarvazyan and José Ángel González and Marc Franco-Salvador},
year={2024},
eprint={2401.03946},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
🤝 Contribute
Feel free to contribute to
Please install and use the dev-tools for correctly formatting the code when contributing to this repo.
🏭 Commercial Purposes
Please, contact stuart.winter-tear@genaios.ai and marc.franco@genaios.ai if you are interested in using TextMachina for commercial purposes.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file text_machina-0.2.12.tar.gz.
File metadata
- Download URL: text_machina-0.2.12.tar.gz
- Upload date:
- Size: 66.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b479a65c129f679e280f91b3f673b3a9ba97f7d257a66588b533aeac7002e48b
|
|
| MD5 |
976d195e979b7bd558bef1ed2608231c
|
|
| BLAKE2b-256 |
58e659797c07a5b1cea075622da0a9d39082ae30ff3e9d73c131174ed32c9ce7
|
File details
Details for the file text_machina-0.2.12-py3-none-any.whl.
File metadata
- Download URL: text_machina-0.2.12-py3-none-any.whl
- Upload date:
- Size: 97.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
db1a144c09123f05d5d74cfd2ec1db15a3c37dfc72406b2ac8e920f33ce0d734
|
|
| MD5 |
3bfdb8d791085328b1ac4084e3d2199f
|
|
| BLAKE2b-256 |
a2ce5229d0cff2bb15ce441f674932f472150aa38a8b6b840c750f0ca2f69936
|







