A library for building text graphs for the application of Graph Neural Networks (GNN), in the context of text classification in natural language processing

Project description

Text for GCN
GCN applied in a text classification context.





Table of Contents
Abstract
Text4GCN is an open-source python framework that simplifies the generation of text-based graph data to be applied as input to graph neural network architectures. Text4GCN's core is the ability to build memory-optimized text graphs, using different text representations to create their relationships and define the weights used for edges.
This project aims to exam the text classification problem with novel approaches Graph Convolutional Networks and Graph Attention Networks using Deep Learning algorithms and Natural Language Processing Techniques.
The main contribution of this work is to provide a flexible framework, capable of performing syntactic and semantic filters that make text graphs smaller and more representative. This framework offers an alternative and powerful tool for the study of Convolutional Graph Networks applied in the text classification task.
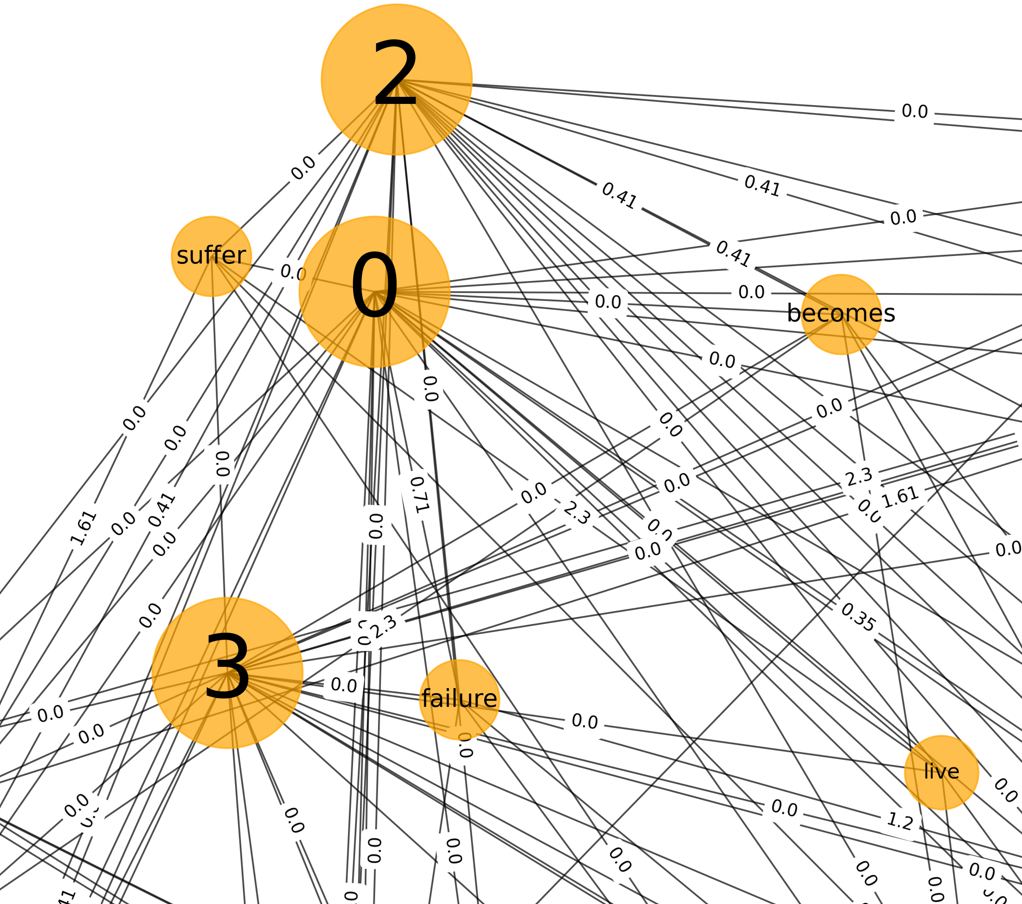
Text graph
Installation
Text4GCN is available at PyPI:
pip install text4gcn
Also, Text4GCN can be cloned directly from GitHub (https://github.com/vitormeriat/text4gcn) and run as a Python script.
Functionalities
- Datasets: Module responsible for downloading model datasets, used in benchmark tasks for text classification.
- Preprocess: It performs dataset processing, applies natural language processing to process the information and generates the files necessary for the construction of text graphs.
- Build Adjacency: Creates the adjacency matrix based on a specific representation.
- Models: Provides a two-tier GCN built with PyTorch for document classification task.
Examples
Get data
from text4gcn.datasets import data
# List of all available datasets
data.list()
# Download sample data for a specific folder
data.R8(path=path)
data.R52(path=path)
data.AG_NEWS(path=path)
Available Datasets:
- R8 (Reuters News Dataset with 8 labels)
- R52 (Reuters News Dataset with 52 labels)
- 20ng (Newsgroup Dataset)
coming soonOhsumed (Cardiovascular Diseases Abstracts Dataset)coming soonMR (Movie Reviews Dataset)coming soonCora (Citation Dataset)coming soonCiteseer (Citation Dataset)coming soonPubmed (Citation Dataset)
Datasets Description:
| Dataset | Docs | Training | Test | Words | Nodes | Classes | Average Length |
|---|---|---|---|---|---|---|---|
| 20NG | 18,846 | 11,314 | 7,532 | 42,757 | 61,603 | 20 | 221.26 |
| R8 | 7,674 | 5,485 | 2,189 | 7,688 | 15,362 | 8 | 65.72 |
| R52 | 9,100 | 6,532 | 2,568 | 8,892 | 17,992 | 52 | 69.82 |
| MR | 10,662 | 7,108 | 3,554 | 18,764 | 29,426 | 2 | 20.39 |
| Ohsumed | 7,400 | 3,357 | 4,043 | 14,157 | 21,557 | 23 | 135.82 |
Text Pipeline
from text4gcn.preprocess import TextPipeline
# Create a text pipeline for processing a dataset
pipe = TextPipeline(
dataset_name="R8",
rare_count=5,
dataset_path="my_folder",
language="english"
)
# Run the created pipeline
pipe.execute()
Frequency Adjacency
from text4gcn.builder import FrequencyAdjacency
# Create the adjacency matrix based on a specific builder
freq = FrequencyAdjacency(
dataset_name="R8",
dataset_path="my_folder"
)
# Run the created pipeline
freq.build()
Available Builders:
- Liwc Linguistic Inquiry and Word Count to extract a dependency relationship
- Frequency
- Embedding Based on Word2vec, applied due to its ability to capture semantic information for word representations
- CosineSimilarity
- DependencyParsing Based on the Syntactic Dependency Tree extracted with Stanford CoreNLP
coming soonConstituencyParsing
GCN
from text4gcn.models import Builder as bd
from text4gcn.models import Layer as layer
from text4gcn.models import GNN
gnn = GNN(
dataset="R8", # Dataset to train
path="my_folder", # Dataset path
log_dir="examples/log", # Log path
layer=layer.GCN, # Layer Type
epoches=200, # Number of traing epoches
dropout=0.5, # Dropout rate
val_ratio=0.1, # Train data used to validation
early_stopping=10, # Stop early technique
lr=00.2, # Initial learing rate
nhid=200, # Dimensions of hidden layers
builder=bd.Embedding # Type of Filtered Text Graph
)
gnn.fit()
Contributing
Contributions are greatly appreciated. If you want to help us improve this software, please fork the repo and create a new pull request. Don't forget to give the project a star! Thanks!
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Alternatively, you can make suggestions or report bugs by opening a new issue with the appropriate tag ("feature" or "bug") and following our Contributing template.
License
Distributed under the MIT License. See LICENSE.txt for more information.
References
- [Kipf and Welling, 2017] Semi-supervised Classification with Graph Convolutional Networks
- [Liang Yao, Chengsheng Mao, Yuan Luo, 2018] Graph Convolutional Networks for Text Classification
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file text4gcn-1.0.0.tar.gz.
File metadata
- Download URL: text4gcn-1.0.0.tar.gz
- Upload date:
- Size: 36.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
36cfb52f0922c9050dddf96615de2fcd8c17e744baab177dc9bec323fb0174ee
|
|
| MD5 |
a90dbe84e0e1c12cda593143586e3b31
|
|
| BLAKE2b-256 |
0a00ab0c4bff4041d39b59fb09ef4b53857e37f7cc2f61204f2ef6b41b360cbf
|
File details
Details for the file text4gcn-1.0.0-py3-none-any.whl.
File metadata
- Download URL: text4gcn-1.0.0-py3-none-any.whl
- Upload date:
- Size: 43.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
46e9e895d6f22999a229a807451f093d754915367d7e5f650ed740435438b28a
|
|
| MD5 |
7f499d241cc8126842de3d65ffe8b099
|
|
| BLAKE2b-256 |
8f7233befea46155beef3043ab1b80ea729f5d3ef1f9c069fb284a267c856791
|







