A library for augmenting text for natural language processing applications.

Project description
TextAugment: Improving Short Text Classification through Global Augmentation Methods








You have just found TextAugment.
TextAugment is a Python 3 library for augmenting text for natural language processing applications. TextAugment stands on the giant shoulders of NLTK, Gensim, and Googletrans and plays nicely with them.
Acknowledgements
Cite this paper when using this library. Arxiv Version
@inproceedings{marivate2020improving,
title={Improving short text classification through global augmentation methods},
author={Marivate, Vukosi and Sefara, Tshephisho},
booktitle={International Cross-Domain Conference for Machine Learning and Knowledge Extraction},
pages={385--399},
year={2020},
organization={Springer}
}
Table of Contents
- Features
- Citation Paper
- Easy data augmentation (EDA)
- An easier data augmentation (AEDA)
- Mixup augmentation
- Acknowledgements
Features
- Generate synthetic data for improving model performance without manual effort
- Simple, lightweight, easy-to-use library.
- Plug and play to any machine learning frameworks (e.g. PyTorch, TensorFlow, Scikit-learn)
- Support textual data
Citation Paper
Improving short text classification through global augmentation methods.
Requirements
- Python 3
The library installs its core dependencies automatically. Optional extras can be installed for additional augmenters.
$ pip install numpy nltk
$ pip install textaugment
The following code downloads NLTK corpus for wordnet.
nltk.download('wordnet')
The following code downloads NLTK tokenizer. This tokenizer divides a text into a list of sentences by using an unsupervised algorithm to build a model for abbreviation words, collocations, and words that start sentences.
nltk.download('punkt')
The following code downloads default NLTK part-of-speech tagger model. A part-of-speech tagger processes a sequence of words, and attaches a part of speech tag to each word.
nltk.download('averaged_perceptron_tagger')
Use gensim to load a pre-trained word2vec model. Like Google News from Google drive.
import gensim
model = gensim.models.KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin', binary=True)
You can also use gensim to load Facebook's Fasttext English and Multilingual models
import gensim
model = gensim.models.fasttext.load_facebook_model('./cc.en.300.bin.gz')
Or training one from scratch using your data or the following public dataset:
Installation
Install from pip [Recommended]
$ pip install textaugment
or install latest release
$ pip install git+https://github.com/dsfsi/textaugment.git
Install from source
$ git clone git@github.com:dsfsi/textaugment.git
$ cd textaugment
$ python setup.py install
How to use
There are three types of augmentations which can be used:
- word2vec
from textaugment import Word2vec
- fasttext
from textaugment import Fasttext
- wordnet
from textaugment import Wordnet
- translate (This will require internet access)
from textaugment import Translate
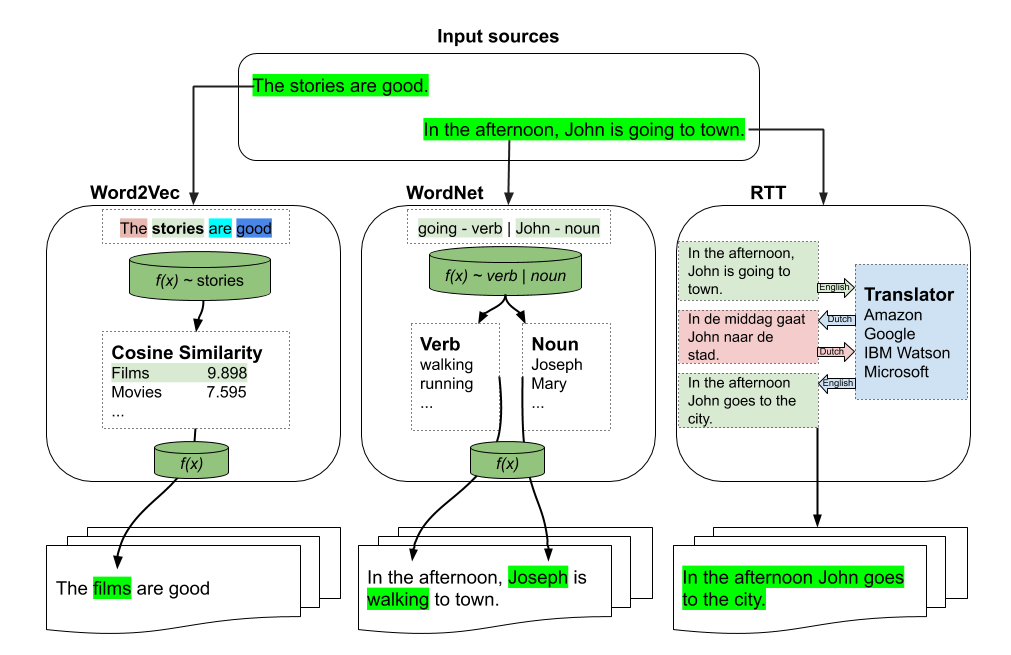
Fasttext/Word2vec-based augmentation
See this notebook for an example
Basic example
>>> from textaugment import Word2vec, Fasttext
>>> t = Word2vec(model='path/to/gensim/model'or 'gensim model itself')
>>> t.augment('The stories are good')
The films are good
>>> t = Fasttext(model='path/to/gensim/model'or 'gensim model itself')
>>> t.augment('The stories are good')
The films are good
Advanced example
>>> runs = 1 # By default.
>>> v = False # verbose mode to replace all the words. If enabled runs is not effective. Used in this paper (https://www.cs.cmu.edu/~diyiy/docs/emnlp_wang_2015.pdf)
>>> p = 0.5 # The probability of success of an individual trial. (0.1<p<1.0), default is 0.5. Used by Geometric distribution to selects words from a sentence.
>>> word = Word2vec(model='path/to/gensim/model'or'gensim model itself', runs=5, v=False, p=0.5)
>>> word.augment('The stories are good', top_n=10)
The movies are excellent
>>> fast = Fasttext(model='path/to/gensim/model'or'gensim model itself', runs=5, v=False, p=0.5)
>>> fast.augment('The stories are good', top_n=10)
The movies are excellent
WordNet-based augmentation
Basic example
>>> import nltk
>>> nltk.download('punkt')
>>> nltk.download('wordnet')
>>> from textaugment import Wordnet
>>> t = Wordnet()
>>> t.augment('In the afternoon, John is going to town')
In the afternoon, John is walking to town
Advanced example
>>> v = True # enable verbs augmentation. By default is True.
>>> n = False # enable nouns augmentation. By default is False.
>>> runs = 1 # number of times to augment a sentence. By default is 1.
>>> p = 0.5 # The probability of success of an individual trial. (0.1<p<1.0), default is 0.5. Used by Geometric distribution to selects words from a sentence.
>>> t = Wordnet(v=False ,n=True, p=0.5)
>>> t.augment('In the afternoon, John is going to town', top_n=10)
In the afternoon, Joseph is going to town.
RTT-based augmentation
Example
>>> src = "en" # source language of the sentence
>>> to = "fr" # target language
>>> from textaugment import Translate
>>> t = Translate(src="en", to="fr")
>>> t.augment('In the afternoon, John is going to town')
In the afternoon John goes to town
EDA: Easy data augmentation techniques for boosting performance on text classification tasks
This is the implementation of EDA by Jason Wei and Kai Zou.
https://www.aclweb.org/anthology/D19-1670.pdf
See this notebook for an example
Synonym Replacement
Randomly choose n words from the sentence that are not stop words. Replace each of these words with one of its synonyms chosen at random.
Basic example
>>> from textaugment import EDA
>>> t = EDA()
>>> t.synonym_replacement("John is going to town", top_n=10)
John is give out to town
Random Deletion
Randomly remove each word in the sentence with probability p.
Basic example
>>> from textaugment import EDA
>>> t = EDA()
>>> t.random_deletion("John is going to town", p=0.2)
is going to town
Random Swap
Randomly choose two words in the sentence and swap their positions. Do this n times.
Basic example
>>> from textaugment import EDA
>>> t = EDA()
>>> t.random_swap("John is going to town")
John town going to is
Random Insertion
Find a random synonym of a random word in the sentence that is not a stop word. Insert that synonym into a random position in the sentence. Do this n times
Basic example
>>> from textaugment import EDA
>>> t = EDA()
>>> t.random_insertion("John is going to town")
John is going to make up town
AEDA: An easier data augmentation technique for text classification
This is the implementation of AEDA by Karimi et al, a variant of EDA. It is based on the random insertion of punctuation marks.
https://aclanthology.org/2021.findings-emnlp.234.pdf
Implementation
See this notebook for an example
Random Insertion of Punctuation Marks
Basic example
>>> from textaugment import AEDA
>>> t = AEDA()
>>> t.punct_insertion("John is going to town")
! John is going to town
Mixup augmentation
This is the implementation of mixup augmentation by Hongyi Zhang, Moustapha Cisse, Yann Dauphin, David Lopez-Paz adapted to NLP.
Used in Augmenting Data with Mixup for Sentence Classification: An Empirical Study.
Mixup is a generic and straightforward data augmentation principle. In essence, mixup trains a neural network on convex combinations of pairs of examples and their labels. By doing so, mixup regularises the neural network to favour simple linear behaviour in-between training examples.
Implementation
See this notebook for an example
Built with ❤ on
Authors
Acknowledgements
Cite this paper when using this library. Arxiv Version
@inproceedings{marivate2020improving,
title={Improving short text classification through global augmentation methods},
author={Marivate, Vukosi and Sefara, Tshephisho},
booktitle={International Cross-Domain Conference for Machine Learning and Knowledge Extraction},
pages={385--399},
year={2020},
organization={Springer}
}
Licence
MIT licensed. See the bundled LICENCE file for more details.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file textaugment-3.0.0.tar.gz.
File metadata
- Download URL: textaugment-3.0.0.tar.gz
- Upload date:
- Size: 21.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e5ab89dbcc25907426a8bf523558a082311d4ef77cd135373ffa916badc6a864
|
|
| MD5 |
4345532d4f7818edf2607547cb809ba5
|
|
| BLAKE2b-256 |
e5b57469d072a457594bf6fcecf8f8018cd80bfe7f22572687193c2e90bd5ce1
|
File details
Details for the file textaugment-3.0.0-py3-none-any.whl.
File metadata
- Download URL: textaugment-3.0.0-py3-none-any.whl
- Upload date:
- Size: 20.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
385ecd6173bb1c0ac3cde87fb97b8f76c6b05a3572dec8d93ea48362cad00cd1
|
|
| MD5 |
d18c5fc0433a9dc7638aef31cdb7807f
|
|
| BLAKE2b-256 |
88d74b2851dbbd865798528337da2eccf791201d5228397cde9664a46d922e38
|







