TextDirectory allows you to combine multiple text files into one. While doing this, filters and transformations can be applied.

Project description
TextDirectory



TextDirectory allows you to combine multiple text files into one aggregated file. TextDirectory also supports matching files for certain criteria and applying transformations to the aggregated text.
TextDirectory can be used as a mere tool (via the CLI) and as a Python library.
Of course, everything TextDirectory does could be achieved in bash or PowerShell. However, there are certain use cases (e.g., when used as a library) in which it might be useful.
Free software: MIT license
Documentation: https://textdirectory.readthedocs.io.
Features
Aggregating multiple text files
Filtering documents/texts based on various parameters such as length, content, and random sampling
Filtering and transforming text files
Transforming the aggregated text (e.g., transforming the text to lowercase)
Version |
Filters |
Transformations |
|---|---|---|
0.1.0 |
filter_by_max_chars(n int); filter_by_min_chars(n int); filter_by_max_tokens(n int); filter_by_min_tokens(n int); filter_by_contains(str); filter_by_not_contains(str); filter_by_random_sampling(n int; replace=False) |
transformation_lowercase |
0.1.1 |
filter_by_chars_outliers(n sigmas int) |
transformation_remove_nl |
0.1.2 |
filter_by_filename_contains(contains str) |
transformation_usas_en_semtag; transformation_uppercase; transformation_postag(spacy_model str) |
0.1.3 |
filter_by_similar_documents(reference_file str; threshold float) |
transformation_remove_non_ascii; transformation_remove_non_alphanumerical |
0.2.0 |
filter_by_max_filesize(max_kb int); filter_by_min_filesize(min_kb int) |
transformation_to_leetspeak; transformation_crude_spellchecker(language model str) |
0.2.1 |
None |
transformation_remove_stopwords(stopwords_source str; stopwords str [en]; spacy_model str; custom_stopwords str); transformation_remove_htmltags |
0.3.0 |
None |
transformation_remove_weird_tokens(spaCy model; remove_double_space=False); transformation_lemmatizer(spaCy model) |
0.3.2 |
None |
transformation_expand_english_contractions |
0.3.3 |
filter_by_filenames(filenames list); filter_by_filename_not_contains(not_contains str) |
transformation_eebop4_to_plaintext; transformation_replace_digits(replacement_character str); transformation_ftfy |
Quickstart
Install TextDirectory via pip: pip install textdirectory
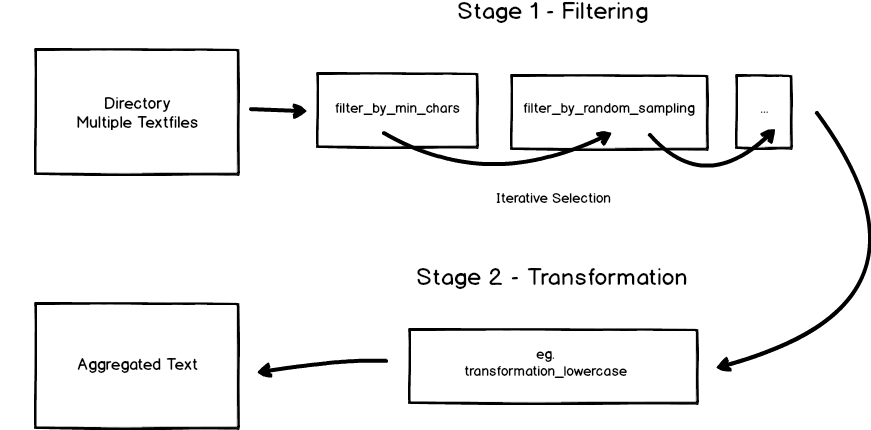
TextDirectory, as exemplified below, works with a two-stage model. After loading in your data (directory) you can, by applying filters, iteratively select the files you want to process. In a second step you can perform transformations on the text before finally aggregating it to either a file or memory.
As a Command-Line Tool
TextDirectory comes equipped with a CLI.
The syntax for both the filters and tranformations works similarly. They are chained by adding slashes (/) and parameters are passed via commas (,): filter_by_min_tokens,5/filter_by_random_sampling,2.
Example 1: A Very Simple Aggregation
textdirectory --directory testdata --output_file aggregated.txt
This will take all files (.txt) in testdata and then aggregates the files into a file called aggregated.txt.
You could also use ‘*’ as a wildcard for filetype if you need to include all files and not just .txt.
textdirectory --directory testdata --output_file aggregated.txt --filetype *
Example 2: Applying Filters and Transformations
In this example, we want to filter the files based on their token count, perform a random sampling and finally transform all text to lowercase.
textdirectory --directory testdata --output_file aggregated.txt --filters filter_by_min_tokens,5/filter_by_random_sampling,2 --transformations transformation_lowercase
After passing two filters (filter_by_min_tokens and filter_by_random_sampling) we’ve applied the transform_lowercase transformation.
The resulting file will contain the content of two files that each have at least five tokens.
As a Python Library
In order to demonstrate TextDirectory as a Python library, we’ll recreate the second example from above:
import textdirectory
td = textdirectory.TextDirectory(directory='testdata')
td.load_files(recursive=False, filetype='txt', sort=True)
td.filter_by_min_tokens(5)
td.filter_by_random_sampling(2)
td.stage_transformation(['transformation_lowercase'])
td.aggregate_to_file('aggregated.txt')If we don’t have special requirements, we can also call td = textdirectory.TextDirectory(directory='testdata', autoload=True) to skip manually calling load_files. If we wanted to keep working with the actual aggregated text, we could have called text = td.aggregate_to_memory() instead of aggregate_to_file.
import textdirectory
td = textdirectory.TextDirectory(directory='testdata', autoload=True)
td.get_text(0)Sometimes we might want to get the actual text of a given file. This can be achieved as seen above. The get_text method will return the transformed text if it is available. Otherwise, it will simply read the file and return the text.
Every applied filter will create a state (i.e., a checkpoint). If we want to go back to a previous state, we can print all states by calling td.print_saved_states(). Previous states can then be loaded by calling td.load_aggregation_state(state=0).
It’s also possible to pass arguments to the individual transformations. In order to do this (at the moment) you have to adhere to the correct order of arguments.
# def transformation_remove_stopwords(text, stopwords_source='internal', stopwords='en', spacy_model='en_core_web_sm', custom_stopwords=None, *args)
td.stage_transformation(['transformation_remove_stopwords', 'internal', 'en', 'en_core_web_sm', 'dolor'])In the above example, we are adding additional custom stopwords to the transformer.
You also might not always want to aggregate texts into one file in many cases but filter and transform them.
import textdirectory
td = textdirectory.TextDirectory(directory='input')
td.load_files()
td.filter_by_max_chars(480)
td.stage_transformation(['transformation_to_leetspeak'])
td.transform_to_files('output')In the example above, we are loading all files in input. After filtering and transforming, the modified files will be written to output.
In addition, there are a few simple examples in the repository for you to look at.
Special Transformations
transformation_eebop4_to_plaintext
This is a highly specific transformation that will extract the plain text from an EEBO-TCP P4 corpus file. Both the header as well as all XML tags will be removed during this transformation.
transformation_ftfy
This transformation simply applies ftfy.fix_text to the text. It is highly recommended to use ftfy as a first transformation if you are working with messy Unicode text.
Notes for Developers
If you want to run tests, please use python setup.py test (or make test). To build the docs, run make docs.
Behavior
We are not holding the actual texts in memory. This leads to much more disk read activity (and time inefficiency), but saves memory. Of course, this is not the case when using aggregate_to_memory.
transformation_usas_en_semtag relies on the web version of Paul Rayson’s USAS Tagger. Don’t use this transformation for large amounts of text, give credit, and consider using their commercial product Wmatrix.
If you are working with a lot of files, it might be wise to use load_files(fast=True, skip_checkpoint=True). This will load files much quicker but skip collecting metadata. This will limit the filters that you can use.
Credits
This package is based on the audreyr/cookiecutter-pypackage coockiecutter template. The crude spellchecker (transformation) is implemented following Peter Norvig’s excellent tutorial.
History
0.1.0 (2018-04-26)
Initial release
First release on PyPI.
0.1.1 (2018-04-27)
added filter_by_chars_outliers
added transformation_remove_nl
0.1.2 (2018-04-29)
added transformation_postag
added transformation_usas_en_semtag
added transformation_uppercase
added filter_by_filename_contains
added parameter support for transformations
0.1.3 (2018-04-30)
filter_by_random_sampling now has a “replacement” option
changed from tabulate to an embedded function
added transformation_remove_non_ascii
added transformation_remove_non_alphanumerical
added filter_by_similar_documents
0.1.4 (2018-04-02)
fixed an object mutation problem in the tabulate function
0.2.0 (2018-05-13)
added transform_to_memory() function
added transformation_to_leetspeak() function
added transformation_crude_spellchecker
added filter_by_max_filesize
added filter_by_min_filesize
fixed a bug where load_files() would fail if there were no files
0.2.1 (2019-06-13)
added transformation_remove_stopwords
added transformation_remove_htmltags
fixed some minor bugs
0.2.2 (2019-06-13)
changed the data packaging
0.3.0 (2020-01-19)
added transformation_remove_weird_tokens
added transformation_lemmatizer
fixed some minor bugs
added a function to revert applied filters
added a function that prints the current pipeline
added a function that clears all transformations
added helper functions to list available filters and transformations
fixed a bug in which tabulate_flat_list_of_dicts would fail if the dictionary was empty
self.aggregation does not hold a copy of the files anymore but references to self.files
transformations relying on spaCy are now estimating a max_length based on available memory
TextDirectory objects are now iterable
0.3.1 (2020-01-20)
added long_description_content_type to setup.py
0.3.2 (2021-01-10)
added transformation_expand_english_contractions
fixed some minor bugs
added __str__ method to TextDirectory
added filename to __str__ output
added get_text method
0.3.3 (2022-09-25)
added filter_by_filenames
added filter_by_filename_not_contains
added transform_to_files
added transformation_eebop4_to_plaintext
added transformation_replace_digits
added transformation_ftfy
added fast and skip_checkpoint options to load_files
added __repr__ method to TextDirectory
added examples
upgraded to spaCy 3
improved the test suite
fixed some minor bugs
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file textdirectory-0.3.3.tar.gz.
File metadata
- Download URL: textdirectory-0.3.3.tar.gz
- Upload date:
- Size: 6.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c6bc7871ea3aae6e652713c7f097221cad0563653270ec0a49c7f4e6ea44547f
|
|
| MD5 |
b67b2ab9996275be235e8c3c3b6a05c8
|
|
| BLAKE2b-256 |
1c368806267b33d23d327ad1d91cc9dc6b2efa6bfe39c1fbf9f6a25a74a0f391
|
File details
Details for the file textdirectory-0.3.3-py2.py3-none-any.whl.
File metadata
- Download URL: textdirectory-0.3.3-py2.py3-none-any.whl
- Upload date:
- Size: 6.2 MB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
24ba0b1f77d00e9e5da5ae1e2e15ae390d7e03110465342df26064c3763e66b5
|
|
| MD5 |
8bf564121aefe5261e124914f6a1d720
|
|
| BLAKE2b-256 |
5d77c41ae22f8479aa50adf4a4cd9db1f88d63c44ceef91a6fbaf3b5262e869a
|







