Text preprocessing, representation and visualization from zero to hero.

Project description






Text preprocessing, representation and visualization from zero to hero.
From zero to hero • Installation • Getting Started • Examples • API • FAQ • Contributions
From zero to hero
Texthero is a python toolkit to work with text-based dataset quickly and effortlessly. Texthero is very simple to learn and designed to be used on top of Pandas. Texthero has the same expressiveness and power of Pandas and is extensively documented. Texthero is modern and conceived for programmers of the 2020 decade with little knowledge if any in linguistic.
You can think of Texthero as a tool to help you understand and work with text-based dataset. Given a tabular dataset, it's easy to grasp the main concept. Instead, given a text dataset, it's harder to have quick insights into the underline data. With Texthero, preprocessing text data, map it into vectors and visualize the obtained vector space takes just a couple of lines.
Texthero include tools for:
- Preprocess text data: it offers both out-of-the-box solutions but it's also flexible for custom-solutions.
- Natural Language Processing: keyphrases and keywords extraction, and named entity recognition.
- Text representation: TF-IDF, term frequency, and custom word-embeddings (wip)
- Vector space analysis: clustering (K-means, Meanshift, DBSAN and Hierarchical), topic modelling (wip) and interpretation.
- Text visualization: vector space visualization, place localization on maps (wip).
Texthero is free, open source and well documented (and that's what we love most by the way!).
We hope you will find pleasure working with Texthero as we had during his development.
Hablas español?
Texthero has been developed for the whole NLP community. We know of hard is to deal with different NLP tools (NLTK, SpaCy, Gensim, TextBlob, Sklearn): that's why we developed Texthero, to simplify things.
Now, the next main milestone is to provide multilingual support and for this big step, we need the help of all of you. ¿Hablas español? Sie sprechen Deutsch? 你会说中文? 日本語が話せるのか? Fala português? Parli Italiano? Вы говорите по-русски? If yes or you speak another language not mentioned, then you might help us develop multilingual support! Even if you haven't contributed before or you just started with NLP contact us or open a Github issue, there is always a first time :) We promise you will learn a lot, and, ... who knows? It might help you find your new job as an NLP-developer!
For improving the python toolkit and provide an even better experience, your aid and feedback are crucial. If you have any problem or suggestion please open a Github issue, we will be glad to support you and help you.
Installation
Install texthero via pip:
pip install texthero
☝️Under the hoods, Texthero makes use of multiple NLP and machine learning toolkits such as Gensim, NLTK, SpaCy and scikit-learn. You don't need to install them all separately, pip will take care of that.
For fast performance, make sure you have installed Spacy version >= 2.2. Also, make sure you have a recent version of python, the higher, the best.
Getting started
The best way to learn Texthero is through the Getting Started docs.
In case you are an advanced python user, then help(texthero) should do the work.
Examples
1. Text cleaning, TF-IDF representation and visualization
import texthero as hero
import pandas as pd
df = pd.read_csv(
"https://github.com/jbesomi/texthero/raw/master/dataset/bbcsport.csv"
)
df['pca'] = (
df['text']
.pipe(hero.clean)
.pipe(hero.tfidf)
.pipe(hero.pca)
)
hero.scatterplot(df, 'pca', color='topic', title="PCA BBC Sport news")

2. Text preprocessing, TF-IDF, K-means and visualization
import texthero as hero
import pandas as pd
df = pd.read_csv(
"https://github.com/jbesomi/texthero/raw/master/dataset/bbcsport.csv"
)
df['tfidf'] = (
df['text']
.pipe(hero.clean)
.pipe(hero.tfidf)
)
df['kmeans_labels'] = (
df['tfidf']
.pipe(hero.kmeans, n_clusters=5)
.astype(str)
)
df['pca'] = df['tfidf'].pipe(hero.pca)
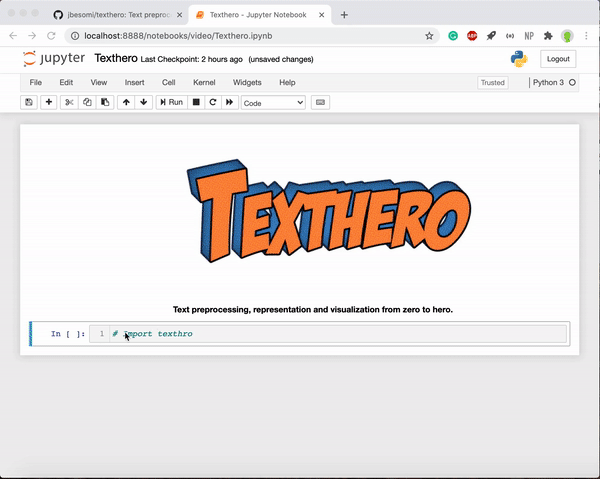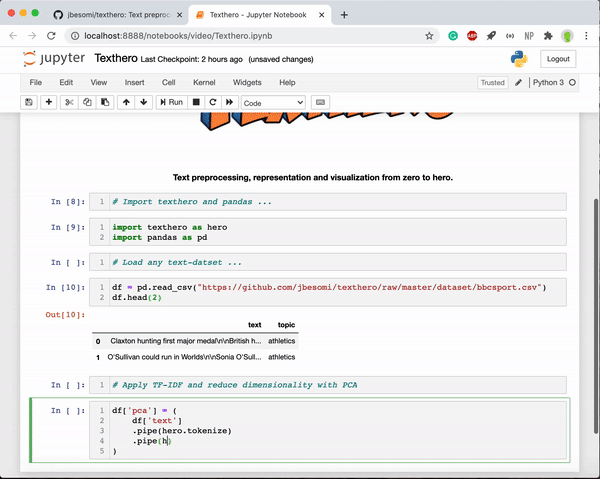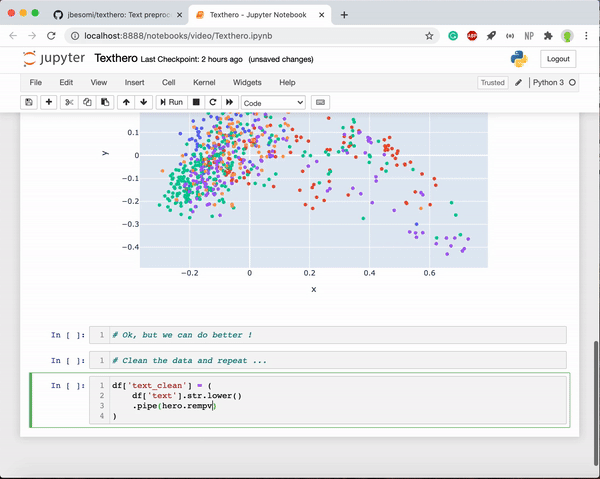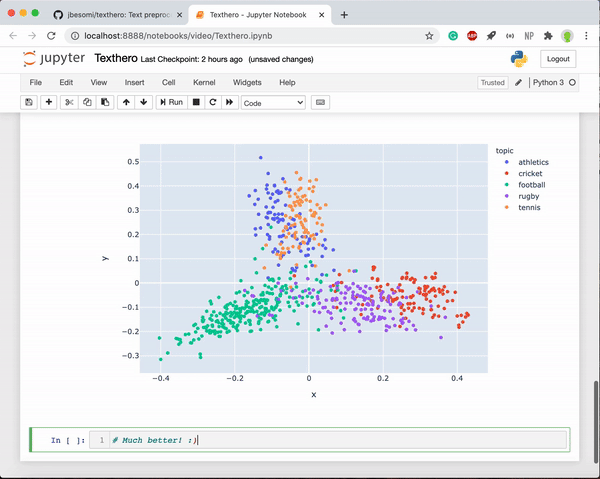
hero.scatterplot(df, 'pca', color='kmeans_labels', title="K-means BBC Sport news")

3. Simple pipeline for text cleaning
>>> import texthero as hero
>>> import pandas as pd
>>> text = "This sèntencé (123 /) needs to [OK!] be cleaned! "
>>> s = pd.Series(text)
>>> s
0 This sèntencé (123 /) needs to [OK!] be cleane...
dtype: object
Remove all digits:
>>> s = hero.remove_digits(s)
>>> s
0 This sèntencé ( /) needs to [OK!] be cleaned!
dtype: object
Remove digits replace only blocks of digits. The digits in the string "hello123" will not be removed. If we want to remove all digits, you need to set only_blocks to false.
Remove all type of brackets and their content.
>>> s = hero.remove_brackets(s)
>>> s
0 This sèntencé needs to be cleaned!
dtype: object
Remove diacritics.
>>> s = hero.remove_diacritics(s)
>>> s
0 This sentence needs to be cleaned!
dtype: object
Remove punctuation.
>>> s = hero.remove_punctuation(s)
>>> s
0 This sentence needs to be cleaned
dtype: object
Remove extra white-spaces.
>>> s = hero.remove_whitespace(s)
>>> s
0 This sentence needs to be cleaned
dtype: object
Sometimes we also wants to get rid of stop-words.
>>> s = hero.remove_stopwords(s)
>>> s
0 This sentence needs cleaned
dtype: object
API
Texthero is composed of four modules: preprocessing.py, nlp.py, representation.py and visualization.py.
1. Preprocessing
Scope: prepare text data for further analysis.
Full documentation: preprocessing
2. NLP
Scope: provide classic natural language processing tools such as named_entity and noun_phrases.
Full documentation: nlp
2. Representation
Scope: map text data into vectors and do dimensionality reduction.
Supported representation algorithms:
- Term frequency (
count) - Term frequency-inverse document frequency (
tfidf)
Supported clustering algorithms:
- K-means (
kmeans) - Density-Based Spatial Clustering of Applications with Noise (
dbscan) - Meanshift (
meanshift)
Supported dimensionality reduction algorithms:
- Principal component analysis (
pca) - t-distributed stochastic neighbor embedding (
tsne) - Non-negative matrix factorization (
nmf)
Full documentation: representation
3. Visualization
Scope: summarize the main facts regarding the text data and visualize it. This module is opinionable. It's handy for anyone that needs a quick solution to visualize on screen the text data, for instance during a text exploratory data analysis (EDA).
Supported functions:
- Text scatterplot (
scatterplot) - Most common words (
top_words)
Full documentation: visualization
FAQ
Why Texthero
Sometimes we just want things done, right? Texthero help with that. It helps makes things easier and give to the developer more time to focus on his custom requirements. We believe that start cleaning text should just take a minute. Same for finding the most important part of a text and same for representing it.
In a very pragmatic way, texthero has just one goal: make the developer spare time. Working with text data can be a pain and in most cases, a default pipeline can be quite good to start. There is always the time to come back and improve the preprocessing pipeline.
Contributions
Pull requests are amazing and most welcome. Start by fork this repository and open an issue.
Texthero is also looking for maintainers and contributors. In case of interest, just drop a line at jonathanbesomi__AT__gmail.com
Contributors (in chronological order)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file texthero-1.1.0.tar.gz.
File metadata
- Download URL: texthero-1.1.0.tar.gz
- Upload date:
- Size: 24.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.23.0 setuptools/41.2.0 requests-toolbelt/0.9.1 tqdm/4.46.0 CPython/3.7.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b2a213884b3365bee3a5f4bf6e9fdc8f341a636026b57eb02954b00c39454131
|
|
| MD5 |
ee5d6a6cebe34a8fcf510727b3183981
|
|
| BLAKE2b-256 |
006b90e53fc4daf79ae1b8ce11c43d57ac70ea8334794e1510ccd92c813fa5fc
|
File details
Details for the file texthero-1.1.0-py3-none-any.whl.
File metadata
- Download URL: texthero-1.1.0-py3-none-any.whl
- Upload date:
- Size: 24.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.23.0 setuptools/41.2.0 requests-toolbelt/0.9.1 tqdm/4.46.0 CPython/3.7.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
404f865b927551123d590176b1c178156dd49a5781420a81989b8a2c0d19c149
|
|
| MD5 |
150da56cdc73434f6ce5d9425e69f449
|
|
| BLAKE2b-256 |
4882643a2ecd63884fa174ab2d8b5d7422d09b2c71450f11e5cfe32b928b97ef
|







