A tf.keras implementation of the MADGRAD optimization algorithm

Project description
MADGRAD Optimization Algorithm For Tensorflow
This package implements the MadGrad Algorithm proposed in Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization (Aaron Defazio and Samy Jelassi, 2021).





Table of Contents
About The Project
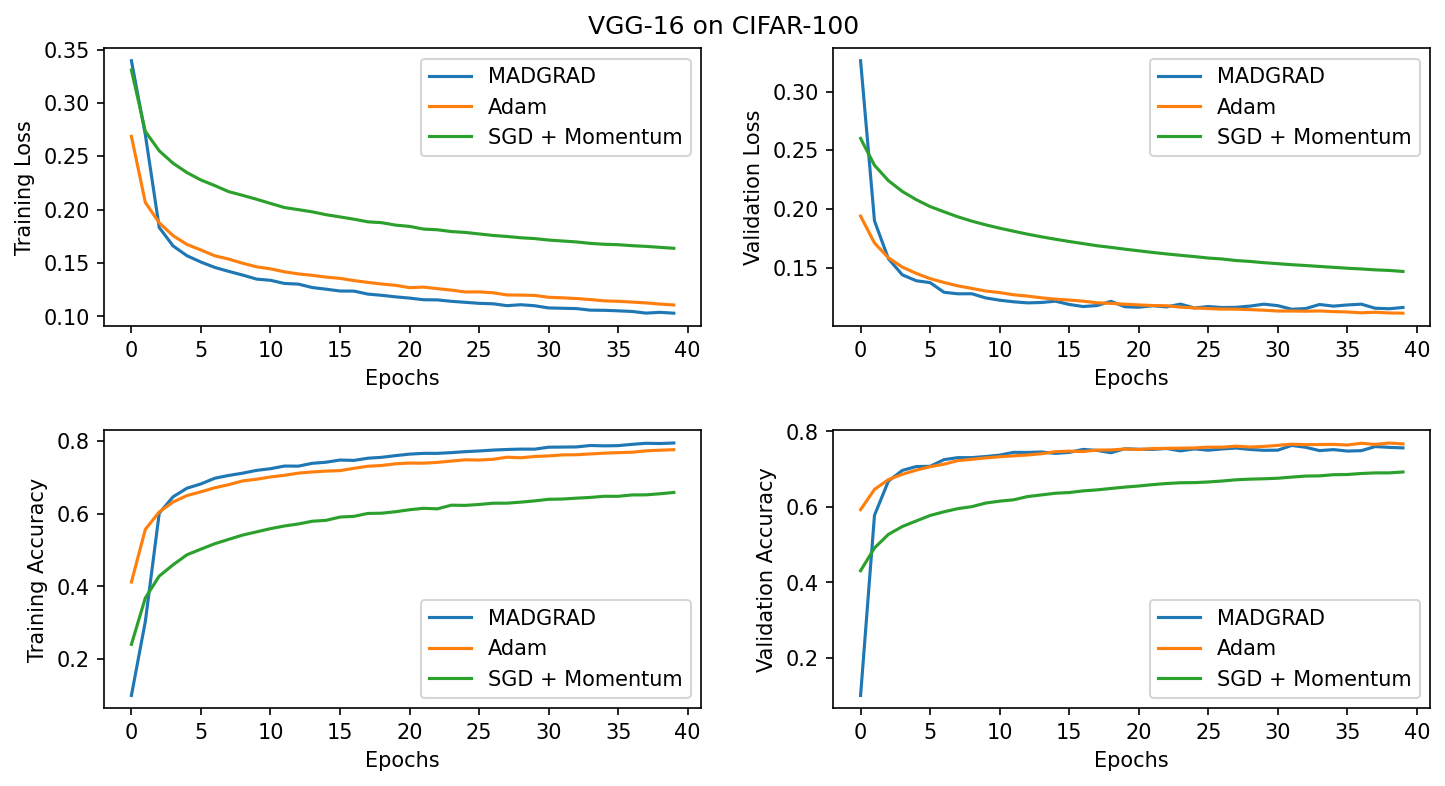
The MadGrad algorithm of optimization uses Dual averaging of gradients along with momentum based adaptivity to attain results that match or outperform Adam or SGD + momentum based algorithms. This project offers a Tensorflow implementation of the algorithm along with a few usage examples and tests.
Prerequisites
Prerequisites can be installed separately through the requirements.txt file as below
pip install -r requirements.txt
Installation
This project is built with Python 3 and can be pip installed directly
pip install tf-madgrad
Usage

To use the optimizer in any tf.keras model, you just need to import and instantiate the MadGrad optimizer from the tf_madgrad package.
from madgrad import MadGrad
# Create the architecture
inp = tf.keras.layers.Input(shape=shape)
...
op = tf.keras.layers.Dense(classes, activation=activation)
# Instantiate the model
model = tf.keras.models.Model(inp, op)
# Pass the MadGrad optimizer to the compile function
model.compile(optimizer=MadGrad(lr=0.01), loss=loss)
# Fit the keras model as normal
model.fit(...)
This implementation is also supported for distributed training using tf.strategy
See a MNIST example here
Contributing
Any and all contributions are welcome. Please raise an issue if the optimizer gives incorrect results or crashes unexpectedly during training.
License
Distributed under the MIT License. See LICENSE for more information.
Contact
Feel free to reach out for any issues or requests related to this implementation
Darshan Deshpande - Email | LinkedIn
Citations
@misc{defazio2021adaptivity,
title={Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization},
author={Aaron Defazio and Samy Jelassi},
year={2021},
eprint={2101.11075},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tf-madgrad-1.0.2.tar.gz.
File metadata
- Download URL: tf-madgrad-1.0.2.tar.gz
- Upload date:
- Size: 8.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ece312faa7ec6154b6c78d3783e6b09dec6c96d84c708808c6b9050491376aea
|
|
| MD5 |
c928ac50a9c5109673116da5dd44ffe7
|
|
| BLAKE2b-256 |
ccc504a2c26f9770003fd84d9abc72542465f3252d6c93f7503d498896b386d0
|
File details
Details for the file tf_madgrad-1.0.2-py3.7.egg.
File metadata
- Download URL: tf_madgrad-1.0.2-py3.7.egg
- Upload date:
- Size: 8.1 kB
- Tags: Egg
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
88746a64d05b9ee36b6aaa58700d18b74e6f7a857c943ba9c584f397b08cc4a3
|
|
| MD5 |
cad294c2510486353f4546a8eb413476
|
|
| BLAKE2b-256 |
70241f15ef8f9f3f8f0a4c5ab736880a7734453dc1fb437070cda1750e6cdd50
|
File details
Details for the file tf_madgrad-1.0.2-py3-none-any.whl.
File metadata
- Download URL: tf_madgrad-1.0.2-py3-none-any.whl
- Upload date:
- Size: 5.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1eec9f64ac4fe7fe47baa89cc99694a1a6b662ef732fd31c45194487bf657570
|
|
| MD5 |
1f19ce5d1f44e796bd4fb539078fd92b
|
|
| BLAKE2b-256 |
70396923007b65809314c0a153d4b4b882e7d04f0b1d8694ef1192e7b4228a81
|







