Theseus is a library of tools to use in marketing analysis

Project description
Theseus

Theseus provides straightforward tools for cohort analysis and general marketing performance analysis. Theseus was created by Eric Benjamin Seufert of Heracles.
Theseus is an open source library that provides a set of common functions for use in doing analysis related to product growth: building retention profiles, projecting DAU levels, combining cohorts, segmenting cohorts by age, etc. Theseus can be used for marketing budgeting planning, scenario analysis, marketing campaign analysis, revenue projections, and in a media mix model.
Theseus is designed to be used for standalone analysis projects as well as in programmatic business intelligence environments.
Theseus is provided as open source software under the MIT license.
Note that Theseus is in a beta state; bugs are to be expected.
Documentation
The documentation for Theseus can be found in this QuantMar thread.
Installation
Use the package manager pip to install Theseus.
pip install theseus_growth
Usage
Include the theseus_growth library
import theseus_growth as th
Instantiate a Theseus object
th = th.theseus()
Working with Theseus involves using retention profiles to build cohort projections. To get started with analysis, you'll first build a retention profile using days and retention values, where each day value corresponds to a retention value, starting from Day 1 (ie. the day after a user has entered the product). Retention values should be provided as whole numbers (not decimals), eg. 30% retention for some given day would be represented as 30 and not .30.
The retention and day values are provided as lists, the lengths of which must match. Theseus uses the index of the values in the days list to associate with a value from the retention list, so no need to order the lists.
Here's an example:
x_data = [ 1, 3, 7, 14, 30, 60, 90, 180 ]
y_data = [ 80, 70, 55, 50, 30, 22, 10, 8 ]
facebook = th.create_profile( days = x_data, retention_values = y_data )
print( facebook )
In this example, Day 1 retention is set to 80, Day 3 retention is set to 70, Day 7 retention is set to 55, etc. Then, these lists are supplied to the create_profile function to generate a retention profile (in this case, for Facebook, as per the variable name).
The curve fit to the retention data is decided by iterating over a number of different function forms to find the one that fits best with the smallest error. The functions tested are: [ 'log', 'exp', 'linear', 'quad', 'weibull', 'power', 'interpolate' ]. A specific function can be forced onto the data by using the form parameter with the create_profile function; when the form parameter is not set, create_profile defaults to finding the best fit function.
If you print the facebook variable, the output will reveal a number of pieces of information about the retention profile:
{'x': [1, 3, 7, 14, 30, 60, 90, 180], 'y': [80, 70, 55, 50, 30, 22, 10, 8], 'y_collapsed': [80.0, 70.0, 55.0, 50.0, 30.0, 22.0, 10.0, 8.0], 'x_collapsed': [1, 3, 7, 14, 30, 60, 90, 180], 'interpolation_f': <scipy.interpolate.interpolate.interp1d object at 0x10c6234f8>, 'interpolation_s': <scipy.interpolate.fitpack2.InterpolatedUnivariateSpline object at 0x10c638588>, 'params': {'log': array([11.69432981, 0.85932489, 91.18858849]), 'exp': array([6.81055507e+01, 4.01937193e-02, 1.00786302e+01]), 'linear': array([-0.36314103, 58.10116222]), 'quad': array([ 4.23356783e-03, -1.09641452e+00, 6.94411850e+01]), 'weibull': array([136.70664663, 0.99893803]), 'power': array([88.3002565, 0.3123284]), 'interpolate': None}, 'errors': {'log': 61.1068291195336, 'exp': 101.38898207577283, 'linear': 1412.367783723572, 'quad': 364.49321231183075, 'weibull': 12824.82253493541, 'power': 440.6176923037875}, 'best_fit': 'log', 'retention_profile': 'best_fit', 'retention_projection': (array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39,
40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52,
53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65,
66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78,
79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91,
92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104,
105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117,
118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130,
131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143,
144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156,
157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169,
170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180]), [100.0, 80.72474913359267, 73.46379035522745, 68.40395854720839, 64.51667685670971, 61.35945860038563, 58.70096154455828, 56.40491084756263, 54.384231538266555, 52.579888860453295, 50.95000745540398, 49.46380467615453, 48.097988591666066, 46.834508880262675, 45.65909322498185, 44.56026139229167, 43.52864131907821, 42.55648257398489, 41.63730255356898, 40.76562419809498, 39.936778210530946, 39.14675163202042, 38.392070317383634, 37.669706592412716, 36.97700588336105, 36.3116278251625, 35.67149854953705, 35.054771699032194, 34.459796319341784, 33.88509022316152, 33.32931774346239, 32.79127103579817, 32.269854271186304, 31.764070199363758, 31.273008668265803, 30.79583676761319, 30.331790328468763, 29.88016656089222, 29.440317651599635, 29.01164517522338, 28.593595198171947, 28.185653974577036, 27.78734415043222, 27.398221405576763, 27.017871474283382, 26.645907494353807, 26.281967642193266, 25.92571301762287, 25.576825747436132, 25.235007281103094, 24.899976855723068, 24.57147011044914, 24.24923783325221, 23.933044825140172, 23.622668868865617, 23.317899790794513, 23.01853860601659, 22.724396737987817, 22.43529530504138, 22.15106446700662, 21.87154282596005, 21.59657687581418, 21.326020496044592, 21.059734485374676, 20.79758613169244, 20.539448814872614, 20.285201639528808, 20.034729095029036, 19.787920740381438, 19.544670911838594, 19.30487845128266, 19.06844645364413, 18.835282031775264, 18.605296097351072, 18.378403156503964, 18.154521119018952, 17.933571120024055, 17.715477353206225, 17.500166914670615, 17.287569656638155, 17.07761805024684, 16.870247056785416, 16.66539400674492, 16.462998486125443, 16.263002229482055, 16.065349019235967, 15.86998459081596, 15.676856543229135, 15.485914254692815, 15.297108802987182, 15.11039289021575, 14.925720771683615, 14.743048188626403, 14.562332304542082, 14.383531644896777, 14.206606039992167, 14.031516570797578, 13.858225517564094, 13.686696311050966, 13.516893486206541, 13.34878263815699, 13.18233038036621, 13.01750430483952, 12.854272944252656, 12.692605735895398, 12.53247298732623, 12.373845843641718, 12.216696256270339, 12.060996953206299, 11.90672141060432, 11.753843825661477, 11.602339090716569, 11.452182768502269, 11.30335106848878, 11.15582082426181, 11.009569471881221, 10.86457502916953, 10.720816075882823, 10.578271734719507, 10.436921653124443, 10.296745985849213, 10.157725378230722, 10.019840950153323, 9.883074280660807, 9.747407393187231, 9.612822741376846, 9.47930319546505, 9.346832029194132, 9.215392907238623, 9.084969873116748, 8.955547337565534, 8.827110067358433, 8.69964317454533, 8.573132106096097, 8.447562633929394, 8.322920845309952, 8.199193133597916, 8.076366189334905, 7.954426991652241, 7.833362799987498, 7.713161146095985, 7.5938098263449945, 7.475296894278529, 7.357610653441469, 7.240739650452227, 7.124672668313735, 7.009398719952898, 6.8949070419793514, 6.781187088654434, 6.668228526062208, 6.556021226474144, 6.444555262900209, 6.33382090381852, 6.223808608077022, 6.114509019960167, 6.005912964414506, 5.898011442426906, 5.790795626549496, 5.684256856566179, 5.578386635294848, 5.473176624520619, 5.368618641055164, 5.264704652917132, 5.16142677562982, 5.058777268631218, 4.95674853179267, 4.8553331020422945, 4.754523650089098, 4.65431297724453, 4.554694012337748, 4.455659808721521, 4.357203541365507, 4.259318504033715, 4.161998106543535, 4.065235872103301, 3.969025434725765, 3.873360536714898, 3.778235026223541, 3.6836428548796363, 3.5895780754783857])}
You won't ever actually interact directly with a retention profile variable, but you can see that it contains:
- The original X and Y (the
daysandretentionlists) data provided; - A projection (in the
retention_projectionvariable); - Two
_collapsedvariables that contain the average values for each of thedaysandretentionlists (in this example, only one value was provided for each day, so they_collapsedlist is the same as theylist, which was provided); - A
paramsdict that contains coefficients for a number of different shape functions; - Some other miscellaneous data, like interpolation models;
With the Facebook retention profile created, cohort projections can be generated from it. First, the profile can be visualized with the plot_retention function:
th.plot_retention( facebook )
Which should output a graph that looks like this:
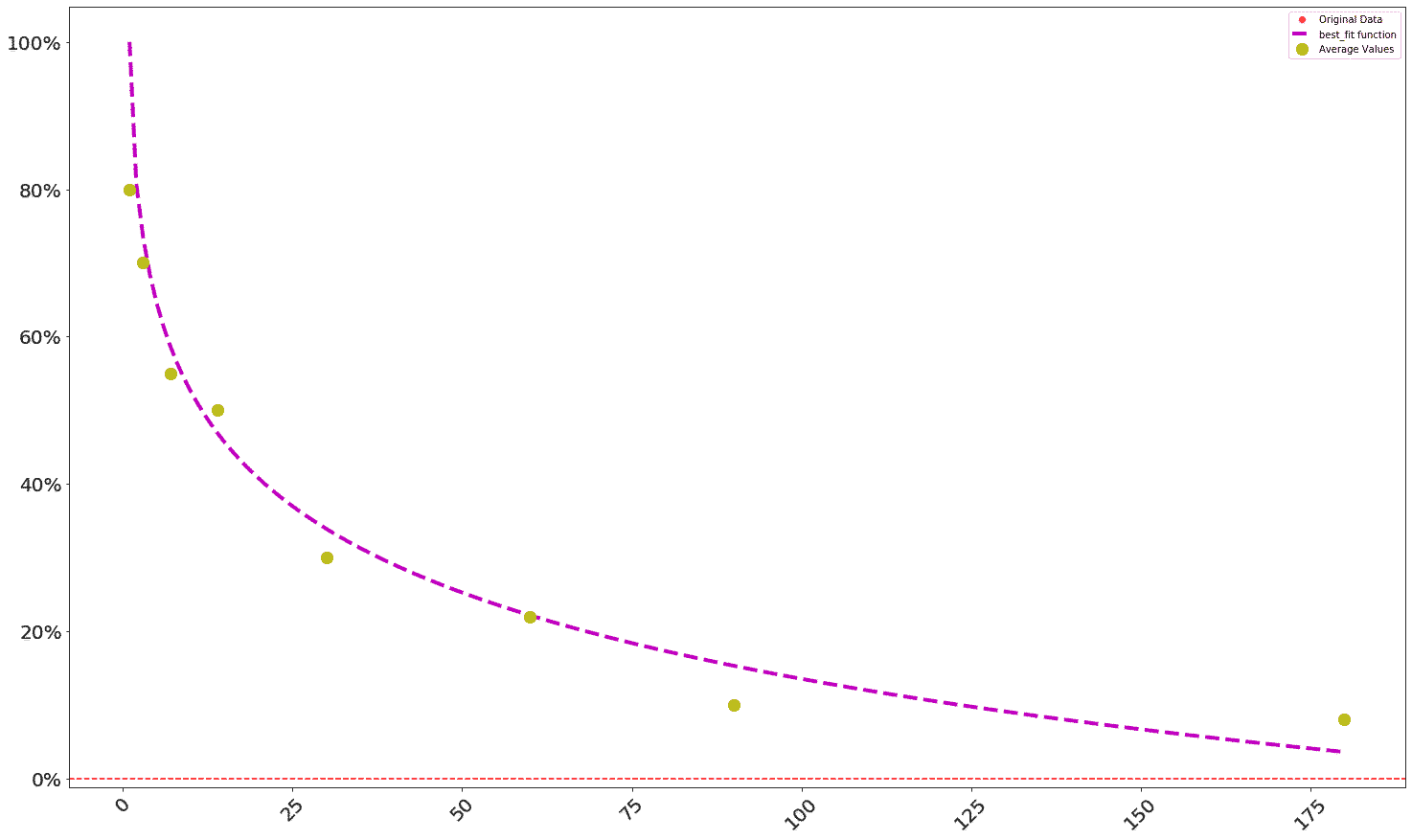
Now a DAU projection based on cohorts can be generated -- in the Theseus library, this is called a forward DAU projection. First, we'll create a list of cohorts, meaning a list containing the numbers of new users that joined the product on a daily basis, with each number representing a sequential day.
Then, the project_cohorted_DAU function can be used to create a Pandas DataFrame containing the number of DAU present in the product, given the new users that joined via the cohorts, on the basis of the facebook retention profile. In this example, the function will take 4 inputs:
profile: the retention profile to use;periods: the number of periods to project forwardcohorts: a list of new user valuesstart_date: the date at which the cohorts are added and from which the projection is made
#cohorts are daily new user values, eg. the number of new users
#joining the product on a given day
cohorts = [1000, 1000, 1000, 1000, 1000 ]
facebook_DAU = th.project_cohorted_DAU( profile = facebook, periods = 50,
cohorts = cohorts, start_date = 1 )
print( facebook_DAU )
The output of this should look like:
1 2 3 4 5 6 7 8 9 10 ... 41 \
cohort_date ...
1 1000 807 734 684 645 613 587 564 543 525 ... 285
2 0 1000 807 734 684 645 613 587 564 543 ... 290
3 0 0 1000 807 734 684 645 613 587 564 ... 294
4 0 0 0 1000 807 734 684 645 613 587 ... 298
5 0 0 0 0 1000 807 734 684 645 613 ... 303
42 43 44 45 46 47 48 49 50
cohort_date
1 281 277 273 270 266 262 259 255 252
2 285 281 277 273 270 266 262 259 255
3 290 285 281 277 273 270 266 262 259
4 294 290 285 281 277 273 270 266 262
5 298 294 290 285 281 277 273 270 266
[5 rows x 50 columns]
This DataFrame table shows how many of the original cohorts are present on any given day; the cohort numbers run down the Y axis and the days run across the X axis.
To see this as a total, the DAU_total function can be used:
facebook_total = th.DAU_total( facebook_DAU )
print( facebook_total )
The output of which should look like:
1 2 3 4 5 6 7 8 9 10 ... 41 \
Value ...
DAU 1000 808 1734 2491 3186 4548 5911 7274 8637 10000 ... 4312
42 43 44 45 46 47 48 49 50
Value
DAU 4246 4182 4119 4058 3999 3941 3888 3831 3779
[1 rows x 50 columns]
This table represents the total number of DAU present in the product from those five cohorts over the course of a 50-period timeline.
The project_cohorted_DAU can be used to project DAU out given some set of cohorts and a retention profile, but it can also be used to generate the number of new users needed to reach a DAU target over a timeline, given some existing set of cohorts.
In this example, the cohorts list contains five cohorts of 1000 new users each. If a marketing analyst wanted to know how many additional cohorts, and of what size, would be needed in order to get the user base to 10,000 DAU, then they could use project_cohorted_DAU to do that by adding two parameters: DAU_target and DAU_target_timeline. DAU_target is the targeted number of DAU, and DAU_target_timeline is the number of days over which the additional new users will be added.
In action:
facebook_DAU = th.project_cohorted_DAU( profile = facebook, periods = 50, cohorts = cohorts,
DAU_target = 10000, DAU_target_timeline = 10, start_date = 1 )
print( facebook_DAU )
Should produce the following output:
1 2 3 4 5 6 7 8 9 10 ... \
cohort_date ...
1 1000 807 734 684 645 613 587 564 543 525 ...
2 0 1000 807 734 684 645 613 587 564 543 ...
3 0 0 1000 807 734 684 645 613 587 564 ...
4 0 0 0 1000 807 734 684 645 613 587 ...
5 0 0 0 0 1000 807 734 684 645 613 ...
6 0 0 0 0 0 1613 1302 1184 1103 1040 ...
7 0 0 0 0 0 0 1757 1418 1290 1201 ...
8 0 0 0 0 0 0 0 1853 1495 1361 ...
9 0 0 0 0 0 0 0 0 1934 1561 ...
10 0 0 0 0 0 0 0 0 0 2005 ...
41 42 43 44 45 46 47 48 49 50
cohort_date
1 285 281 277 273 270 266 262 259 255 252
2 290 285 281 277 273 270 266 262 259 255
3 294 290 285 281 277 273 270 266 262 259
4 298 294 290 285 281 277 273 270 266 262
5 303 298 294 290 285 281 277 273 270 266
6 496 489 481 474 467 461 454 448 441 435
7 549 541 532 524 517 509 502 495 488 481
8 588 579 570 562 553 545 537 529 522 514
9 624 614 604 595 586 577 569 561 553 545
10 657 647 636 627 617 608 599 590 581 573
[10 rows x 50 columns]
This table reveals that the additional DNU needed to get to 10,000 overall DAU within the 10-period timeframe is: 1613, 1757, 1853, 1934, 2005. Note that this approach seeks to minimize the number of total DNU added on any given day within the timeline.
To get only the DNU (new users) values from a forward DAU projection, the get_DNU function can be used:
#get DNU from a DAU projection
facebook_DNU = th.get_DNU( facebook_DAU )
print( facebook_DNU )
The output of which should look like:
cohort_date 1 2 3 4 5 6 7 \
Value
DNU 1000 1.0 1000.0 1000.0 1000.0 1710.0 1881.0 1994.0
8 9 ... 41 42 43 44 45 46 47 48 49 50
Value ...
DNU 2090.0 2171.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
[1 rows x 51 columns]
And to reduce facebook_DAU to only the total DAU values over the projection timeline, the DAU_total function can be used again:
1 2 3 4 5 6 7 8 9 10 ... 41 \
DAU ...
0 1000 1807 2541 3225 3870 5096 6322 7548 8774 10000 ... 4384
42 43 44 45 46 47 48 49 50
DAU
0 4318 4250 4188 4126 4067 4009 3953 3897 3842
[1 rows x 50 columns]
Note that this shows DAU reaching 10,000 by Day 10.
The Facebook forward DAU projection can be visualized with the plot_forward_DAU_stacked, which takes three required parameters:
forward_DAU: the forward DAU projection being visualized (in this case, thefacebook_DAUvariable);forward_DAU_labels: a list of the cohort names as labels for the stacked bars. The length of this list needs to match the number of cohorts in the forward DAU projection;forward_DAU_dates: a list of dates as labels for the X axis. The length of this list needs to match the number of periods in the forward DAU projection;
To visualize the Facebook forward DAU projection that reaches the DAU target of 10,000:
th.plot_forward_DAU_stacked( forward_DAU = facebook_DAU,
forward_DAU_labels = list( facebook_DAU.index ),
forward_DAU_dates = list( facebook_DAU.columns ),
)
This should produce a graph that looks like this:
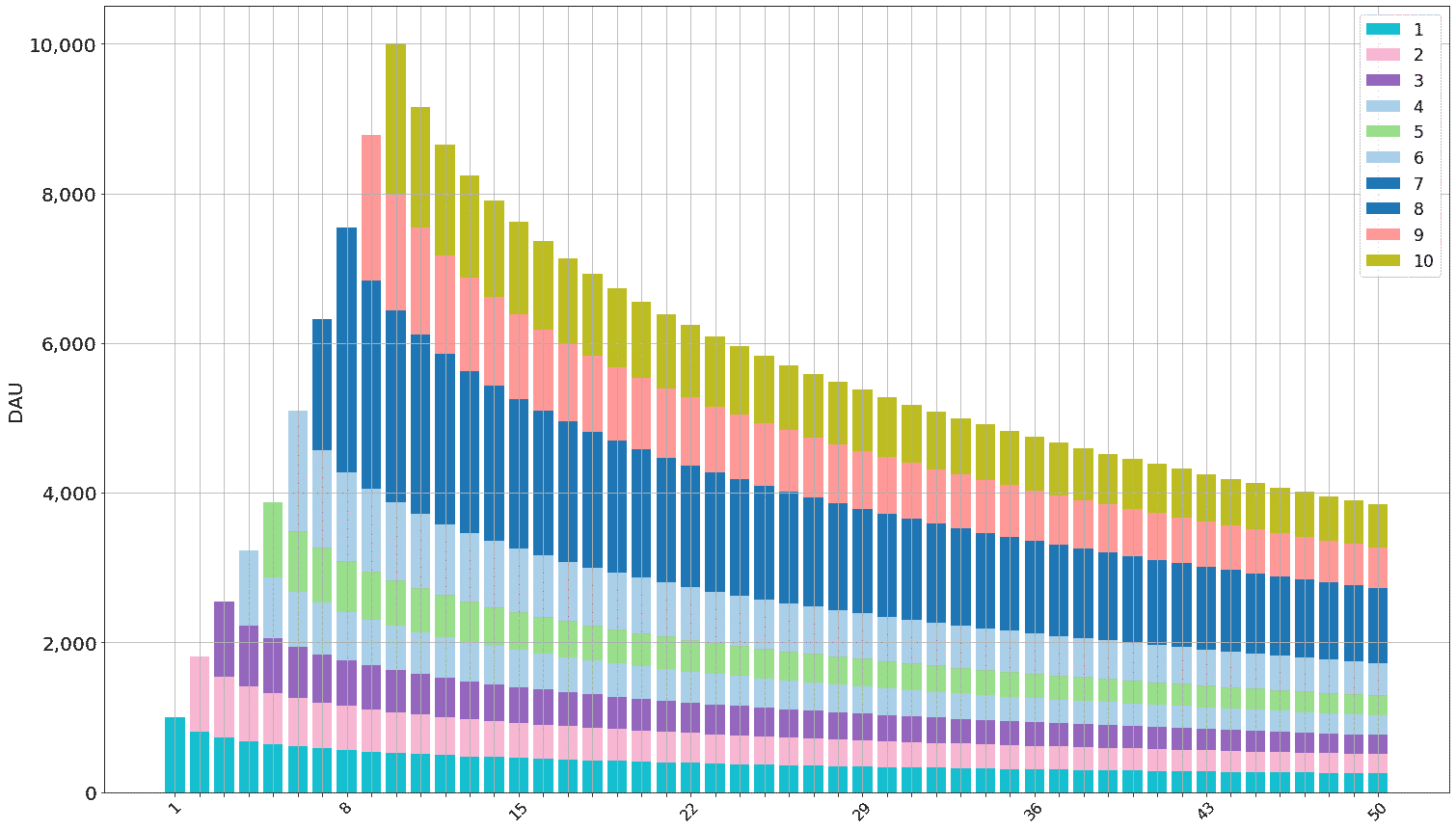
Note that anything can be provided in the forward_DAU_labels and forward_DAU_dates parameters. For instance, to give the X axis actual date values (starting from January 1, 2020) and to make the legend more readable, the following can be done:
from datetime import date, timedelta
th.plot_forward_DAU_stacked( forward_DAU = facebook_DAU,
forward_DAU_labels = [ 'Cohort ' + str( x ) for x in list( facebook_DAU.index ) ],
forward_DAU_dates = [ date(2020, 1, 1) + timedelta(days=int( x ) - 1 ) for x in list( facebook_DAU.columns ) ]
)
This should produce a graph that looks like this:
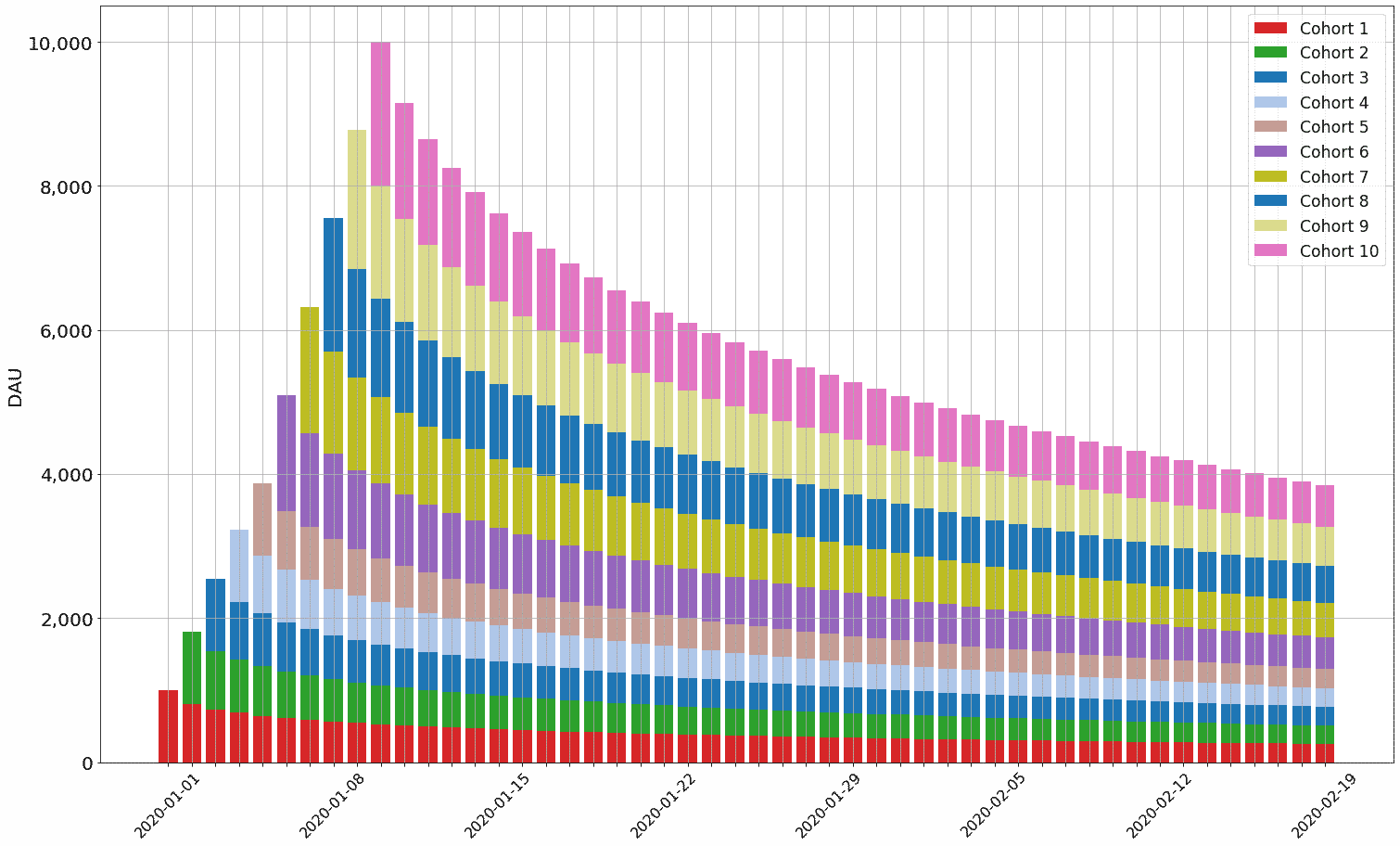
To create a second retention profile -- this time, for Google -- the create_profile profile can be used again. This time, the profile_max parameter will be supplied: when profile_max is provided, the retention profile is projected out to that day (when it is not provided, the retention profile is only projected out to the maximum value provided in the days parameter). Also, with the Google retention profile, a much larger dataset of days and retention values will be supplied, so the curve fit is done against many more (arbitrarily produced) data points:
import numpy as np
import random
x_data = [ 1, 14, 60 ]
y_data = [ 40, 22, 10 ]
new_x = []
for i, x in enumerate( x_data ):
this_x = x
for z in np.arange( 1, 100 ):
this_y = float( y_data[ i ] * ( 1 + ( random.randint( -20, 20 ) / 100 ) ) )
y_data.append( this_y )
new_x.append( this_x )
x_data.extend( new_x )
google = th.create_profile( days = x_data, retention_values = y_data, profile_max = 180 )
th.plot_retention( google )
The output of this should look something like this (the red dots are the actual values from retention_values):
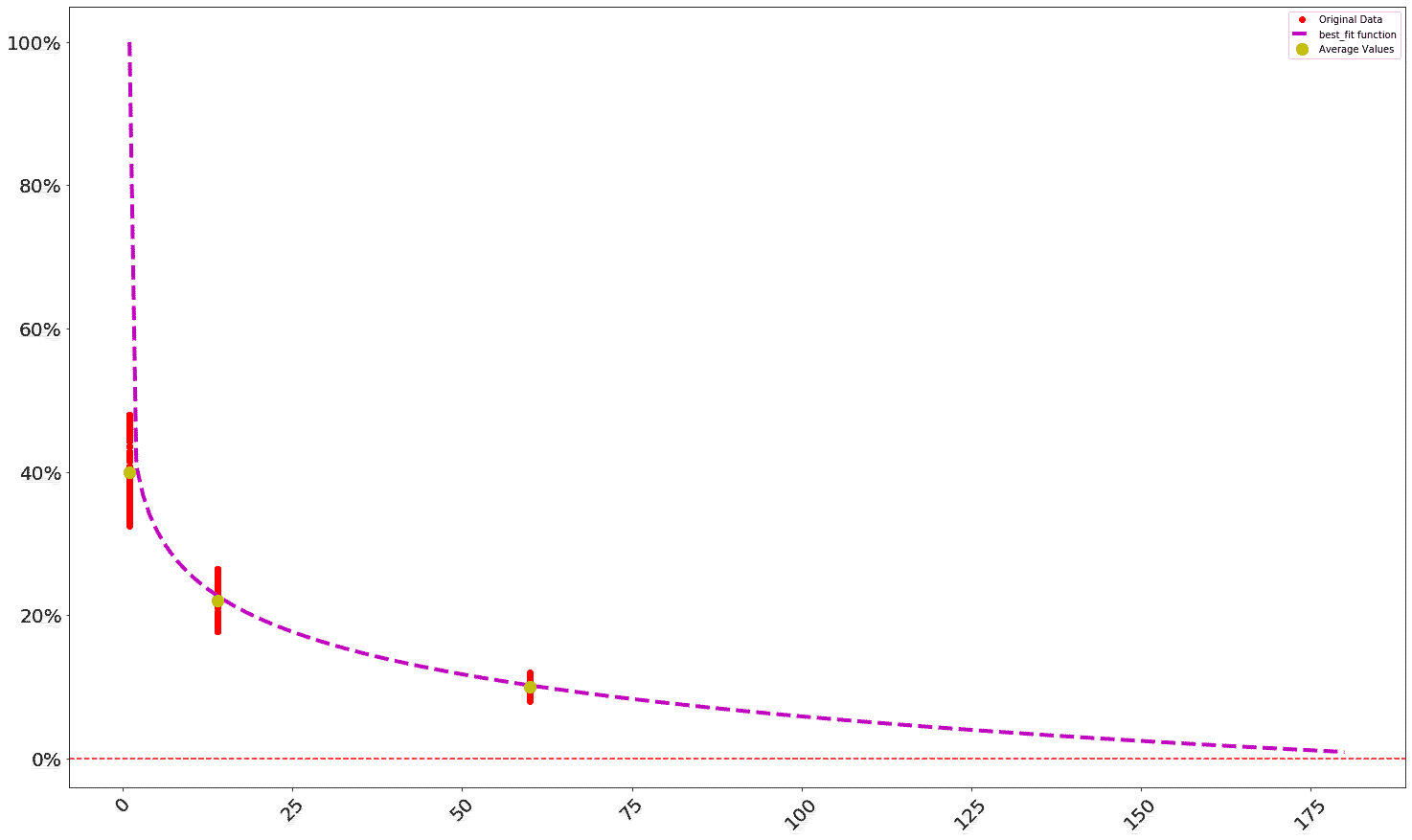
To build a forward DAU projection for Google, the following can be run. Note that the start_date is set to 10:
cohorts = [ 2000, 4000, 1200, 2200, 1700, 1300, 4200, 9200 ]
google_DAU = th.project_cohorted_DAU( profile = google, periods = 40, cohorts = cohorts,
DAU_target = 20000, DAU_target_timeline = 20, start_date = 10 )
from datetime import date, timedelta
th.plot_forward_DAU_stacked( forward_DAU = google_DAU,
forward_DAU_labels = [ 'Cohort ' + str( x ) for x in list( google_DAU.index ) ],
forward_DAU_dates = [ date(2020, 1, 1) + timedelta(days=int( x ) - 1 ) for x in list( google_DAU.columns ) ]
)
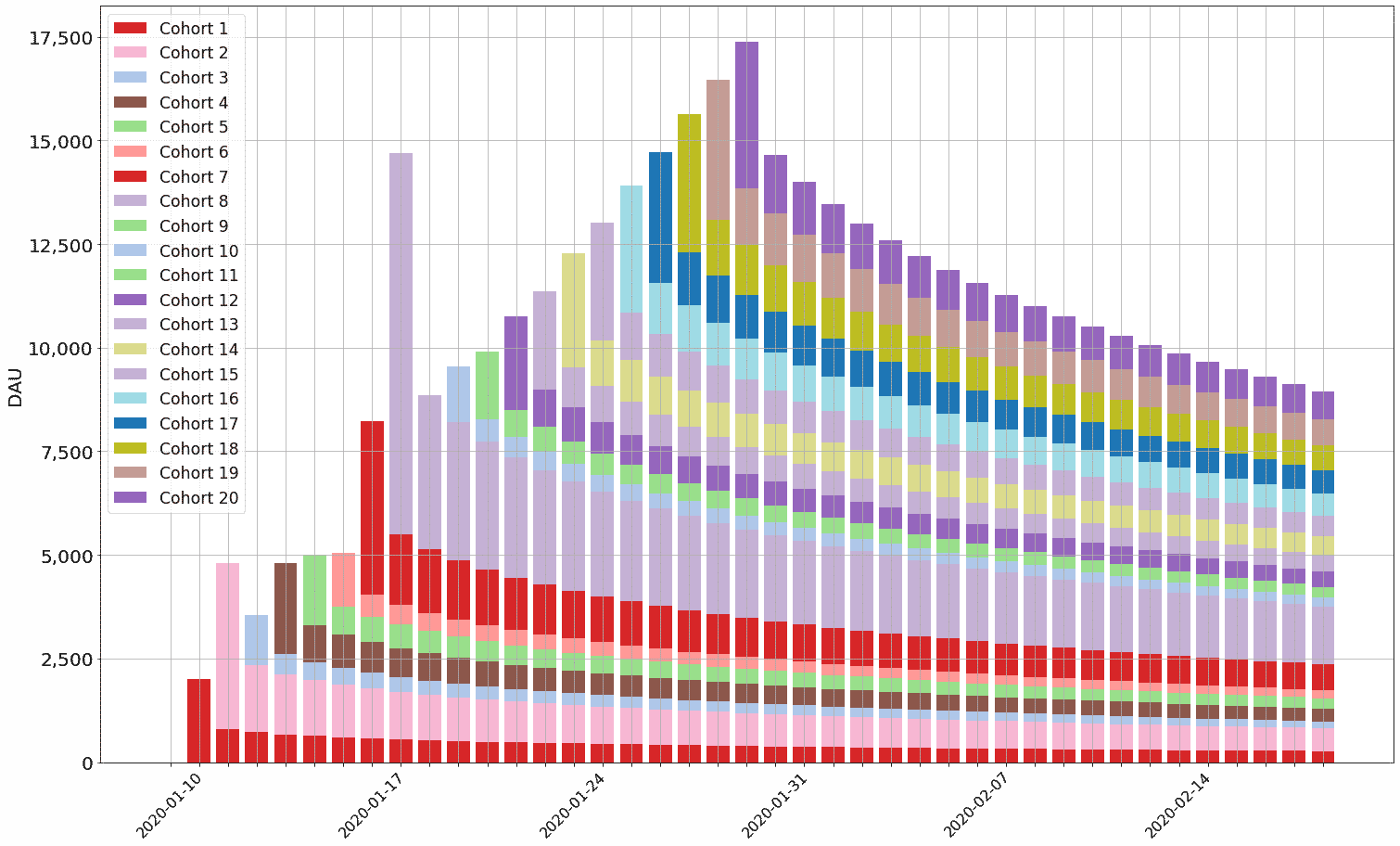
Note the lumpiness of the first few days of DAU -- this is a result of 1) the volatile number of DAU in the initial cohorts and 2) the relatively low Google retention ( 40% on Day 1). Also note the dates on the X axis: the chart starts on January 10th, 2020 since the start_date variable is set to 10.
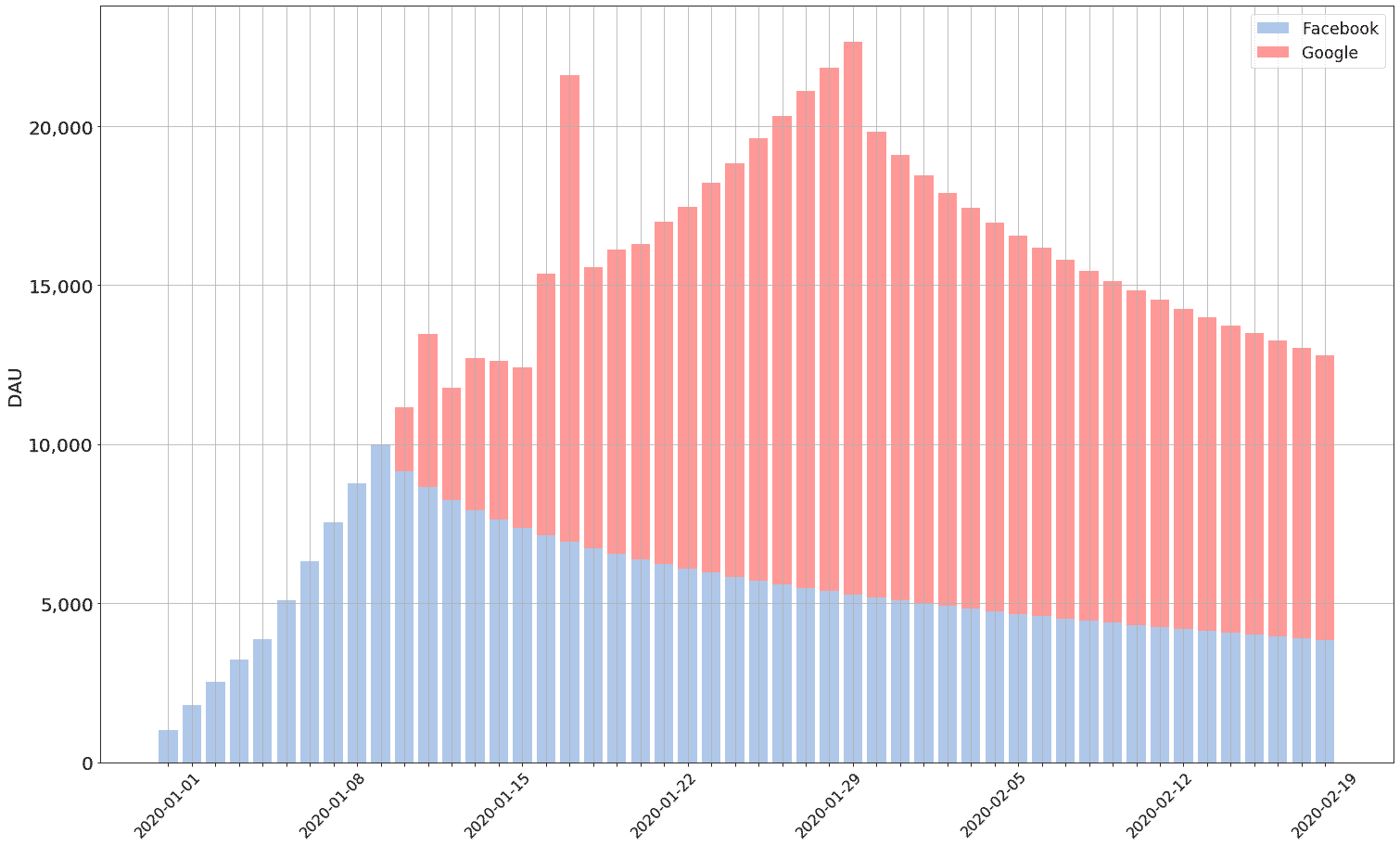
In order to get a fuller picture of product DAU, the Facebook and Google forward DAU projections can be combined with the combine_DAU function. The totals for each forward DAU projection should be used, otherwise the graph would be too busy to read:
google_total = th.DAU_total( google_DAU )
combined_DAU = th.combine_DAU( DAU_totals = [ facebook_total, google_total ], labels = [ "Facebook", "Google" ] )
th.plot_forward_DAU_stacked( forward_DAU = combined_DAU,
forward_DAU_labels = list( combined_DAU.index ),
forward_DAU_dates = [ date(2020, 1, 1) + timedelta(days=int( x ) - 1 ) for x in list( combined_DAU.columns ) ]
)
The output of the above should look like:
One important aspect of cohort analysis is age segmentation: breaking the user base out into segments based on user age. Theseus comes with two functions to do this: project_aged_DAU and project_exact_aged_DAU.
project_aged_DAU presents the DAU projection in terms of minimum user ages: it can display the number of users that are at least X days old on a given date.
project_exact_aged_DAU presents the DAU projection in terms of absolute user ages: it can display the number of users that are exactly X days old on a given date.
Both functions take five parameters:
profile: the retention profile being used for the projection;periods: the number of periods for which the forward DAU projection is being made;cohorts: the cohorts that are being projected forward;start_date: the start date of the projection;ages: a list of ages that the projection should be broken down for. Forproject_aged_DAU, the forward DAU projection will be broken out to show the number of users per day that are at least as old as every age in the list. Forproject_exact_aged_DAU, the forward DAU projection will be broken out to show the number of users per day that are exactly as old as every age in the list.
An example of project_aged_DAU:
x_data = [ 1, 14, 30, 90 ]
y_data = [ 25, 18, 12, 8 ]
#form options: 'log', 'exp', 'linear', 'quad', 'weibull', 'power'
snapchat = th.create_profile( days = x_data, retention_values = y_data, profile_max = 120 )
snapchat_aged_DAU = th.project_aged_DAU( snapchat, 20, [ 100, 200, 300, 400, 500 ],
start_date = 1, ages = [ 3, 7, 14 ] )
print( snapchat_aged_DAU )
This should produce output that looks like the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 \
age
3 0 0 24 71 143 236 352 343 336 327 320 312 305 296 290 282
7 0 0 0 0 0 0 22 65 130 214 320 312 305 296 290 282
14 0 0 0 0 0 0 0 0 0 0 0 0 0 18 55 108
17 18 19 20
age
3 275 268 260 254
7 275 268 260 254
14 180 268 260 254
Taking column 10 as an example: 869 users are at least 3 days old, 563 users are at least 7 days old, and 0 users are at least 14 days old.
An example of project_exact_aged_DAU:
snapchat_exact_aged_DAU = th.project_exact_aged_DAU( snapchat, 20, [ 100, 200, 300, 400, 500 ],
start_date = 1, ages = [ 3, 7, 14 ] )
print( snapchat_exact_aged_DAU )
This should produce output that looks like the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 \
age
3 0 0 24 48 73 97 121 0 0 0 0 0 0 0 0 0 0 0 0
7 0 0 0 0 0 0 22 44 66 88 110 0 0 0 0 0 0 0 0
14 0 0 0 0 0 0 0 0 0 0 0 0 0 18 37 55 74 93 0
20
age
3 0
7 0
14 0
Note that each "age" only has five values; this is because there are only five cohorts provided in the example (each cohort will be an exact age only once).
Also note that if 1 is passed in the ages list for project_exact_aged_DAU, it produces a list of DNU:
snapchat_exact_aged_DAU = th.project_exact_aged_DAU( snapchat, 20, [ 100, 200, 300, 400, 500 ],
start_date = 1, ages = [ 1 ] )
print( snapchat_exact_aged_DAU )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
age
1 100 200 300 400 500 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
One interesting use case for user base segments is calculating percentages of the overall user base that are at least X days old -- often, certain monetization moments are only available to users after some amount of time, so being able to break a user base out into age groups to know what percentage of the user base is capable of monetizing is helpful. This can be done with Theseus by creating a Total forward DAU projection and combining it with the aged projection:
snapchat_DAU = th.project_cohorted_DAU( profile = snapchat, periods = 20, cohorts = [ 100, 200, 300, 400, 500 ],
start_date = 1 )
snapchat_total = th.DAU_total( snapchat_DAU )
combined_DAU = th.combine_DAU( DAU_totals = [ snapchat_aged_DAU, snapchat_total ],
labels = [ [ "Age " + str( x ) for x in list( snapchat_aged_DAU.index ) ], "Total" ]
)
for x in list( snapchat_aged_DAU.index ):
combined_DAU.loc[ 'Age ' + str( x ) + ' Pct' ] = combined_DAU.apply( lambda z: ( z[ 'Age ' + str( x )] / z[ 'Total' ] ) )
print( combined_DAU )
This would output something that looks like:
1 2 3 4 5 6 \
profile
Age 3 0.0 0.0 24.000000 71.000000 143.000000 236.000000
Age 7 0.0 0.0 0.000000 0.000000 0.000000 0.000000
Age 14 0.0 0.0 0.000000 0.000000 0.000000 0.000000
Total 100.0 224.0 373.000000 545.000000 742.000000 360.000000
Age 3 Pct 0.0 0.0 0.064343 0.130275 0.192722 0.655556
Age 7 Pct 0.0 0.0 0.000000 0.000000 0.000000 0.000000
Age 14 Pct 0.0 0.0 0.000000 0.000000 0.000000 0.000000
7 8 9 10 11 12 13 \
profile
Age 3 352.0000 343.000000 336.000000 327.000000 320.0 312.0 305.0
Age 7 22.0000 65.000000 130.000000 214.000000 320.0 312.0 305.0
Age 14 0.0000 0.000000 0.000000 0.000000 0.0 0.0 0.0
Total 352.0000 343.000000 336.000000 327.000000 320.0 312.0 305.0
Age 3 Pct 1.0000 1.000000 1.000000 1.000000 1.0 1.0 1.0
Age 7 Pct 0.0625 0.189504 0.386905 0.654434 1.0 1.0 1.0
Age 14 Pct 0.0000 0.000000 0.000000 0.000000 0.0 0.0 0.0
14 15 16 17 18 19 \
profile
Age 3 296.000000 290.000000 282.000000 275.000000 268.0 260.0
Age 7 296.000000 290.000000 282.000000 275.000000 268.0 260.0
Age 14 18.000000 55.000000 108.000000 180.000000 268.0 260.0
Total 296.000000 290.000000 282.000000 275.000000 268.0 260.0
Age 3 Pct 1.000000 1.000000 1.000000 1.000000 1.0 1.0
Age 7 Pct 1.000000 1.000000 1.000000 1.000000 1.0 1.0
Age 14 Pct 0.060811 0.189655 0.382979 0.654545 1.0 1.0
20
profile
Age 3 254.0
Age 7 254.0
Age 14 254.0
Total 254.0
Age 3 Pct 1.0
Age 7 Pct 1.0
Age 14 Pct 1.0
In order to actually work with these projections, Theseus comes with two file output functions: to_excel and to_json.
to_excel can take three parameters:
df: the forward DAU projection dataframe being output;file_name: the name of the file that will be output (optional)sheet_name: the name of the sheet that the data will be written to (optional)
to_excel will save a .xlsx file in the directory from which the Theseus object is being executed.
to_json can take two parameters:
df: the forward DAU projection dataframe being output;file_name: the name of the file that will be output (optional)
to_json will save a .json file in the directory from which the Theseus object is being executed.
Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please make sure to update tests as appropriate.
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file theseus_growth-0.3.7.tar.gz.
File metadata
- Download URL: theseus_growth-0.3.7.tar.gz
- Upload date:
- Size: 29.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.5.1 CPython/3.11.4 Darwin/22.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cf26cf29c8eafa89b73da8004aae5b9eeed4d30d2cc25ec1a7cc1a431f89f430
|
|
| MD5 |
826b69f88e7d51d777858c38237193a8
|
|
| BLAKE2b-256 |
e1cae555a6eefb1ee0e12d95be2e9dc14198a2c39c8eeaad649a1a7532799d4c
|
File details
Details for the file theseus_growth-0.3.7-py3-none-any.whl.
File metadata
- Download URL: theseus_growth-0.3.7-py3-none-any.whl
- Upload date:
- Size: 22.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.5.1 CPython/3.11.4 Darwin/22.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1a409ccedef290117a12b7cacbc5afb5e66de300326e9552d750fac0e5a4e80b
|
|
| MD5 |
3375b459874e2a6eb46d176e6e4e0fb3
|
|
| BLAKE2b-256 |
27ca08b625a79983cb50f8fd4d65031737f04dca083f7fdfc19a98856b0ea324
|







