RAG evaluation metrics.

Project description

Tonic Validate is a platform for Retrieval Augmented Generation (RAG) development and experiment tracking. This repository, tonic_validate (formerly tvalmetrics) is the SDK component of Tonic Validate. It contains the code for calculating RAG metrics and optionally logging them to the Tonic Validate UI.
Check Out Our UI to Visualize Your Results
In addition to the SDK, we also have a free to use UI. While using the UI isn't required to use the SDK, it does allow you to easily visualize your results. To sign up, click here.
Telemetry
Tonic Validate collects minimal telemetry to help us figure out what users want and how they're using the product. We do not use any existing telemetry framework and instead created our own privacy focused setup. Only the following information is tracked
- What metrics were used for a run
- Number of questions in a run
- Number of questions in a benchmark
We do NOT track things such as the contents of the questions / answers, your scores, or any other sensitive information.
We also generate a random UUID to help us figure out how many users are using the product. This UUID is linked to your Validate account only to help track who is using the SDK and UI at once and to get user counts. If you want to see how we implemented telemetry, you can do so in the tonic_validate/utils/telemetry.py file
If you wish to opt out of telemetry, you only need to set the TONIC_VALIDATE_DO_NOT_TRACK environment variable to True.
Quickstart
-
Install the Tonic Validate SDK by running
pip install tonic-validatein your terminal.
-
Use the following code snippet to get started.
from tonic_validate import ValidateScorer, Benchmark # Function to simulate getting a response and context from your LLM # Replace this with your actual function call def get_llm_response(question): return { "llm_answer": "Paris", "llm_context_list": ["Paris is the capital of France."] } benchmark = Benchmark(questions=["What is the capital of France?"], answers=["Paris"]) # Score the responses for each question and answer pair scorer = ValidateScorer() run = scorer.score(benchmark, get_llm_response)
This code snippet, creates a benchmark with one question and reference answer and then scores the answer.
Tonic Validate Benchmarks
What Are Benchmarks?
To evaluate the RAG (Retrieval Augmented Generation) system's performance, we need a dataset of questions to prompt it with. This is what Benchmarks are for. Benchmarks are a collection of questions which optionally include reference answers. When calculating the performance, Tonic Validate's SDK runs through the list of the questions in the benchmark and asks the LLM each question. Then, Tonic Validate uses the resulting answer from the LLM to figure out the RAG system's performance.
Note: If you are using the
AnswerSimilarityMetricthen you also need to provide a reference answer to each question in the benchmark. The reference answer represents the ideal or correct response to the question. For example, consider the question, "What is the capital of France?" The corresponding reference answer should be "Paris." When using theAnswerSimilarityMetric, the actual answer provided by the LLM is compared against this reference answer to determine how close the LLM's response is to the ideal answer.
How to Use Benchmarks
To use benchmarks, you can pass in a list of questions to ask the LLM (and optionally a list of reference answers via answers).
from tonic_validate import ValidateScorer, Benchmark
# Create a list of questions (required) and answers (optional) for scoring the LLM's performance
benchmark = Benchmark(
questions=["What is the capital of France?", "What is the capital of Germany?"]
answers=["Paris", "Berlin"]
)
To use the benchmark, you can pass it to the score function along with a callback which takes the question and returns the RAG system's response
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, get_rag_response)
Manually Logging with Benchmarks
Alternatively, if you want to log the LLM responses manually without the callback, you can iterate over the benchmark and log the LLM's response.
from tonic_validate import ValidateScorer, LLMResponse
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Save the responses into an array for scoring
responses = []
for item in benchmark:
rag_response = get_rag_response(item.question)
llm_response = LLMResponse(
llm_answer=rag_response["llm_answer"],
llm_context_list=rag_response["llm_context_list"],
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)
Tonic Validate Metrics
Metrics are used to score your LLM's performance. To measure each metric, you will need to provide the required inputs for that metric. Below is a table of the different metrics and the inputs they require.
| Metric Name | Inputs | Formula | Score Range | What does it measure? |
|---|---|---|---|---|
| Answer similarity score | Question + Reference answer + LLM answer | Scored by LLM on a scale of 0 to 5 | 0 to 5 | How well the reference answer matches the LLM answer. |
| Retrieval precision | Question + Retrieved context | (Count of relevant retrieved context) / (Count of retrieved context) | 0 to 1 | Whether the context retrieved is relevant to answer the given question. |
| Augmentation precision | Question + Retrieved context + LLM answer | (Count of relevant retrieved context in LLM answer) / (Count of relevant retrieved context) | 0 to 1 | Whether the relevant context is in the LLM answer. |
| Augmentation accuracy | Retrieved context + LLM answer | (Count of retrieved context in LLM answer) / (Count of retrieved context) | 0 to 1 | Whether all the context is in the LLM answer. |
| Answer consistency or Answer consistency binary | Retrieved context + LLM answer | (Count of the main points in the answer that can be attributed to context) / (Count of main points in answer) | 0 to 1 | Whether there is information in the LLM answer that does not come from the context. |
Metric Inputs
Metric inputs in Tonic Validate are used to provide the metrics with the information they need to calculate performance. Below, we explain each input type and how to pass them into Tonic Validate's SDK.
Question
What is it: The question asked
How to use: You can provide the questions by passing them into the Benchmark via the questions argument.
from tonic_validate import Benchmark
benchmark = Benchmark(
questions=["What is the capital of France?", "What is the capital of Germany?"]
)
Reference Answer
What is it: A prewritten answer that serves as the ground truth for how the RAG application should answer the question.
How to use: You can provide the reference answers by passing it into the Benchmark via the answers argument. Each reference answer must correspond to a given question. So if the reference answer is for the third question in the questions list, then the reference answer must also be the third item in the answers list.
from tonic_validate import Benchmark
benchmark = Benchmark(
questions=["What is the capital of France?", "What is the capital of Germany?"]
answers=["Paris", "Berlin"]
)
LLM Answer
What is it: The answer the RAG application / LLM gives to the question.
How to use: You can provide the LLM answer via the callback you provide to the Validate scorer. The answer is the first item in the tuple response.
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)
If you are manually logging the answers without using the callback, then you can provide the LLM answer via llm_answer when creating the LLMResponse.
from tonic_validate import LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
# llm_answer is the answer that LLM gives
llm_response = LLMResponse(
llm_answer="Paris",
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)
Retrieved Context
What is it: The context that your RAG application retrieves when answering a given question. This context is what's put in the prompt by the RAG application to help the LLM answer the question.
How to use: You can provide the LLM's retrieved context list via the callback you provide to the Validate scorer. The answer is the second item in the tuple response. The retrieved context is always a list
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)
If you are manually logging the answers, then you can provide the LLM context via llm_context_list when creating the LLMResponse.
from tonic_validate import LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
# llm_answer is the answer that LLM gives
# llm_context_list is a list of the context that the LLM used to answer the question
llm_response = LLMResponse(
llm_answer="Paris",
llm_context_list=["Paris is the capital of France."],
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)
Scoring With Metrics
Important: Setting up OpenAI Key for Scoring
Before scoring, you must set up an OpenAI Key as the Tonic Validate metrics make LLM calls.
import os
os.environ["OPENAI_API_KEY"] = "put-your-openai-api-key-here"
If you already have the OPENAI_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
Using Azure
If you are using Azure, instead of setting the OPENAI_API_KEY environment variable, you instead need to set AZURE_OPENAI_KEY and AZURE_OPENAI_ENDPOINT. AZURE_OPENAI_ENDPOINT is the endpoint url for your Azure OpenAI deployment and AZURE_OPENAI_KEY is your API key.
import os
os.environ["AZURE_OPENAI_KEY"] = "put-your-azure-openai-api-key-here"
os.environ["AZURE_OPENAI_ENDPOINT"] = "put-your-azure-endpoint-here"
Setting up the Tonic Validate Scorer
To use metrics, instantiate an instance of them and provide them to the ValidateScorer like so
from tonic_validate import ValidateScorer
scorer = ValidateScorer()
Here is a list of all the possible metrics with their imports
| Metric Name | Import |
|---|---|
| Answer similarity score | from tonic_validate.metrics import AnswerSimilarityMetric |
| Retrieval precision | from tonic_validate.metrics import RetrievalPrecisionMetric |
| Augmentation precision | from tonic_validate.metrics import AugmentationPrecisionMetric |
| Augmentation accuracy | from tonic_validate.metrics import AugmentationAccuracyMetric |
| Answer consistency | from tonic_validate.metrics import AnswerConsistencyMetric |
| Answer consistency binary | from tonic_validate.metrics import AnswerConsistencyBinaryMetric |
The default model used for scoring metrics is GPT 4 Turbo. To change the OpenAI model, pass the OpenAI model name into the model argument for ValidateScorer. You can also pass in custom metrics via an array of metrics.
scorer = ValidateScorer([
AnswerConsistencyMetric(),
AugmentationAccuracyMetric()
], model_evaluator="gpt-3.5-turbo")
If an error occurs while scoring an item's metric, the score for that metric will be set to None. If you instead wish to have Tonic Validate throw an exception when there's an error scoring, then set fail_on_error to True in the constructor
scorer = ValidateScorer(fail_on_error=True)
Important: Using the scorer on Azure
If you are using Azure, you MUST set the model_evaluator argument to your deployment name like so
scorer = ValidateScorer(model_evaluator="your-deployment-name")
Running the Scorer
After you instantiate the ValidateScorer with your desired metrics, you can then score the metrics using the callback you defined earlier.
from tonic_validate import ValidateScorer, ValidateApi
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)
Running the Scorer with manual logging
If you don't want to use the callback, you can instead log your answers manually by iterating over the benchmark and then score the answers.
from tonic_validate import ValidateScorer, LLMResponse
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Save the responses into an array for scoring
responses = []
for item in benchmark:
rag_response = get_rag_response(item.question)
llm_response = LLMResponse(
llm_answer=rag_response["llm_answer"],
llm_context_list=rag_response["llm_context_list"],
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)
Viewing the Results
There are two ways to view the results of a run.
Option 1: Print Out the Results
You can manually print out the results via python like so
print("Overall Scores")
print(run.overall_scores)
print("------")
for item in run.run_data:
print("Question: ", item.reference_question)
print("Answer: ", item.reference_answer)
print("LLM Answer: ", item.llm_answer)
print("LLM Context: ", item.llm_context)
print("Scores: ", item.scores)
print("------")
which outputs the following
Overall Scores
{'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
Question: What is the capital of France?
Answer: Paris
LLM Answer: Paris
LLM Context: ['Paris is the capital of France.']
Scores: {'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
Question: What is the capital of Spain?
Answer: Madrid
LLM Answer: Paris
LLM Context: ['Paris is the capital of France.']
Scores: {'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
Option 2: Use the Tonic Validate UI (Recommended, Free to Use)
You can easily view your run results by uploading them to our free to use UI. The main advantage of this method is the Tonic Validate UI provides graphing for your results along with additional visualization features. To sign up for the UI, go to here.
Once you sign up for the UI, you will go through an onboarding to create an API Key and Project.
Copy both the API Key and Project ID from the onboarding and insert it into the following code
from tonic_validate import ValidateApi
validate_api = ValidateApi("your-api-key")
validate_api.upload_run("your-project-id", run)
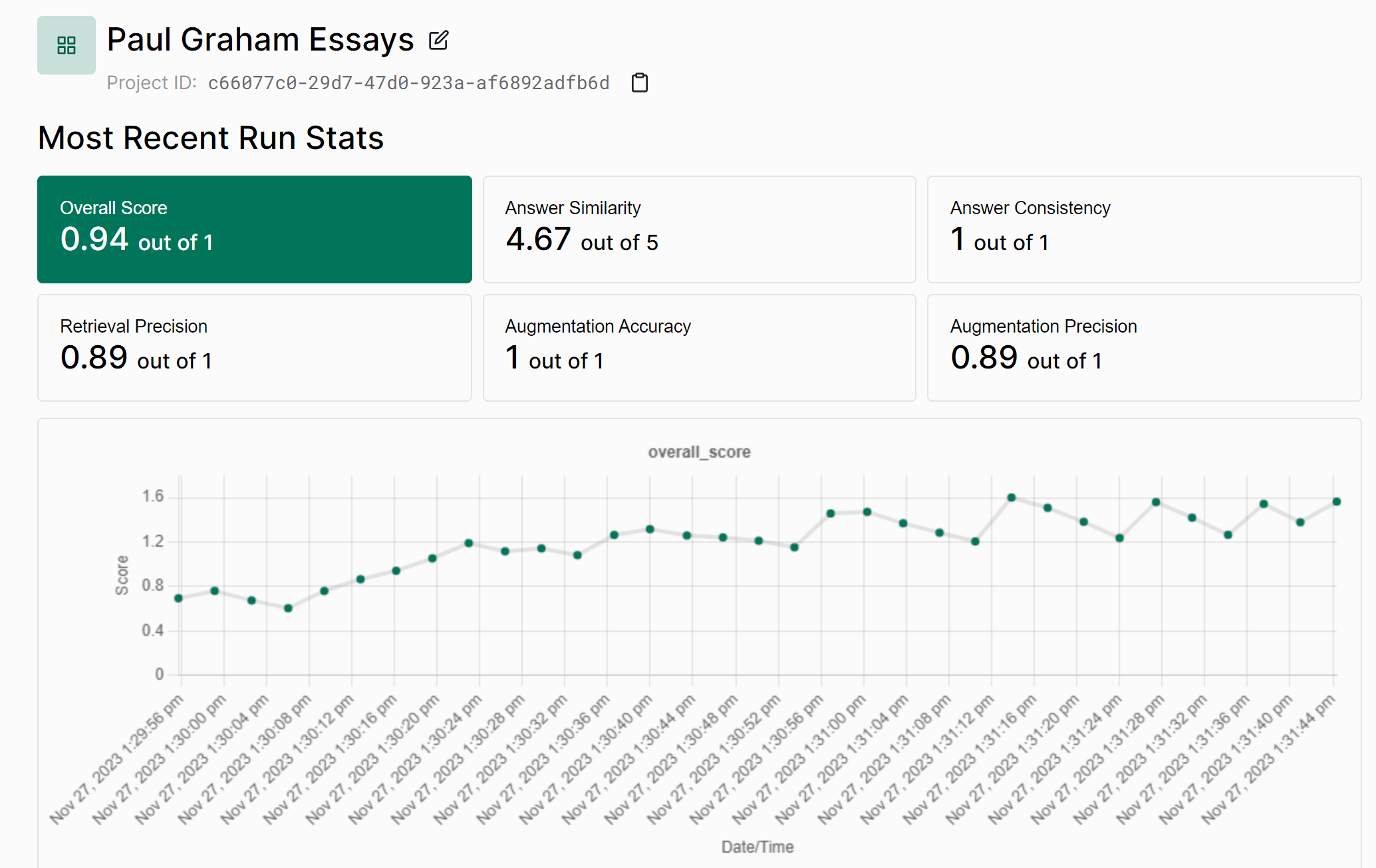
This will upload your run to the Tonic Validate UI where you can view the results. On the home page (as seen below) you can view the change in scores across runs over time.
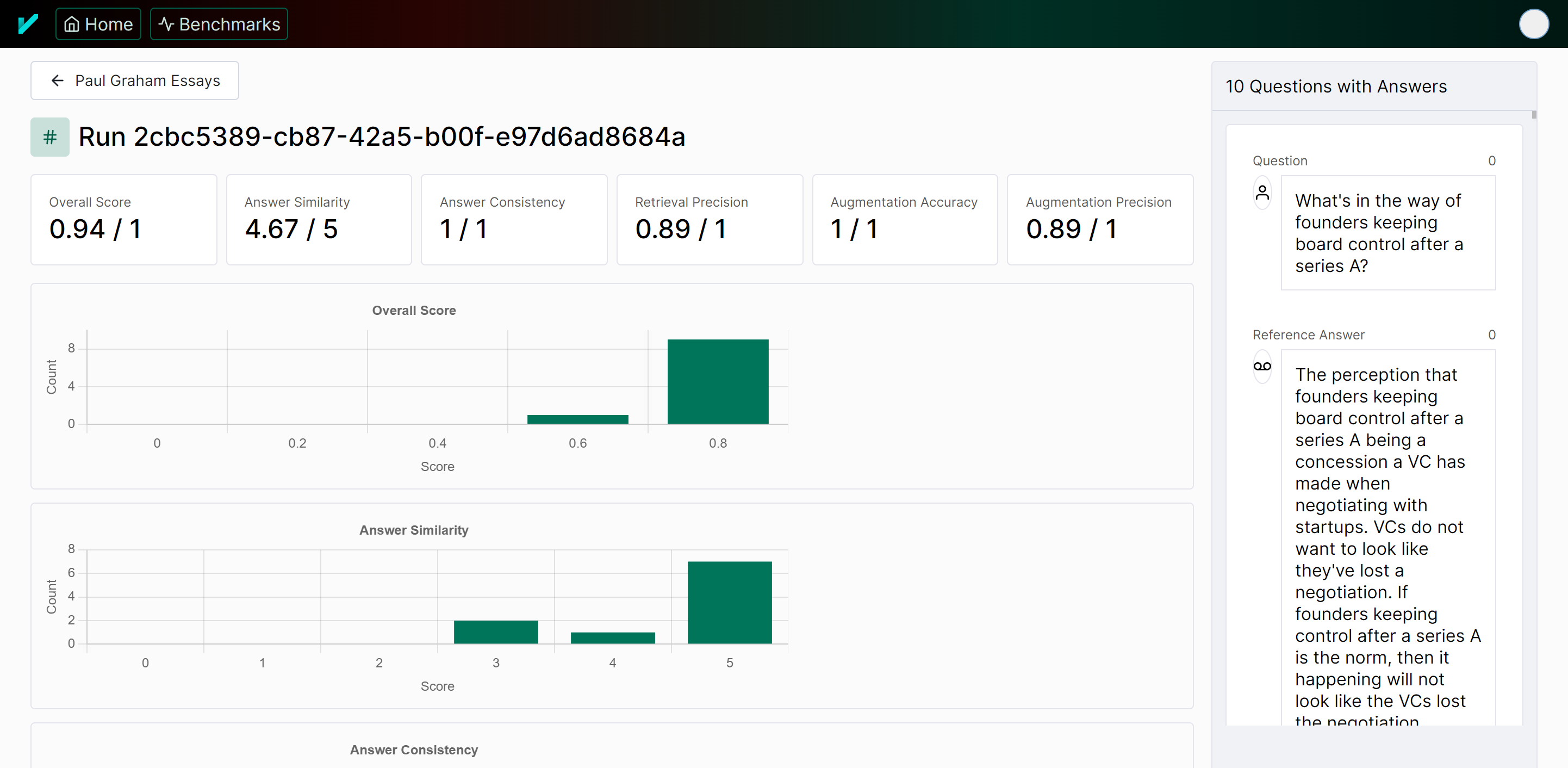
You can also view the results of an individual run in the UI as well.
FAQ
What models can I use an LLM evaluator?
We currently allow the family of chat completion models from Open AI.
This restriction makes it easy to follow the logic for the definition of the metrics in this package. It also ensures that this package does not depend on langchain, which also makes the logic of the package easier to follow.
We'd like to add more models as choices for the LLM evaluator without adding to the complexity of the package too much.
The default model used for scoring metrics is GPT 4 Turbo. To change the OpenAI model, pass the OpenAI model name into the model argument for ValidateScorer
scorer = ValidateScorer([
AnswerConsistencyMetric(),
AugmentationAccuracyMetric()
], model_evaluator="gpt-3.5-turbo")
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tonic_validate-3.1.0.tar.gz.
File metadata
- Download URL: tonic_validate-3.1.0.tar.gz
- Upload date:
- Size: 20.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
88fdaef41fa2bd3ddd9f762ce241f6ed0b5540ed86c626f4056b3c3395ead348
|
|
| MD5 |
17db28503831ff15e08f2f72c4ef4234
|
|
| BLAKE2b-256 |
eddfc875eba8c85cb56490c603cb841dbee350c22b3921e048df75dbed729777
|
File details
Details for the file tonic_validate-3.1.0-py3-none-any.whl.
File metadata
- Download URL: tonic_validate-3.1.0-py3-none-any.whl
- Upload date:
- Size: 24.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
810d6c38e5117e74f9376b836dcd32284ae52304f57b7265823fa898bc0e8a62
|
|
| MD5 |
8d43498273564ebe206392fc3f909a1a
|
|
| BLAKE2b-256 |
3941fe6b149cf65a72649d8f06fef4e17ffcd35ed085872a6d1d76c53d16de76
|







