A Python package to get useful information from documents using TopicRank Algorithm.

Project description
Important topics/phrases extraction using TopicRank algorithm.
Overview
TopicRank is an unsupervised method that aims to extract keyphrases from the most important topics of a document. Topics are defined as clusters of similar keyphrase candidates. This new method is an improvement of the TextRank method applied to keyphrase extraction (Mihalcea and Tarau,2004). In the TextRank method, a document is represented by a graph where words are vertices and edges represent co-occurrence relations. A graph-based ranking model derived from PageRank (Brin and Page, 1998) is then used to assign a significance score to each word. TopicRank represents a document as a complete graph where vertices are not words but topics. It defines a topic as a cluster of similar single and multi-word expressions.
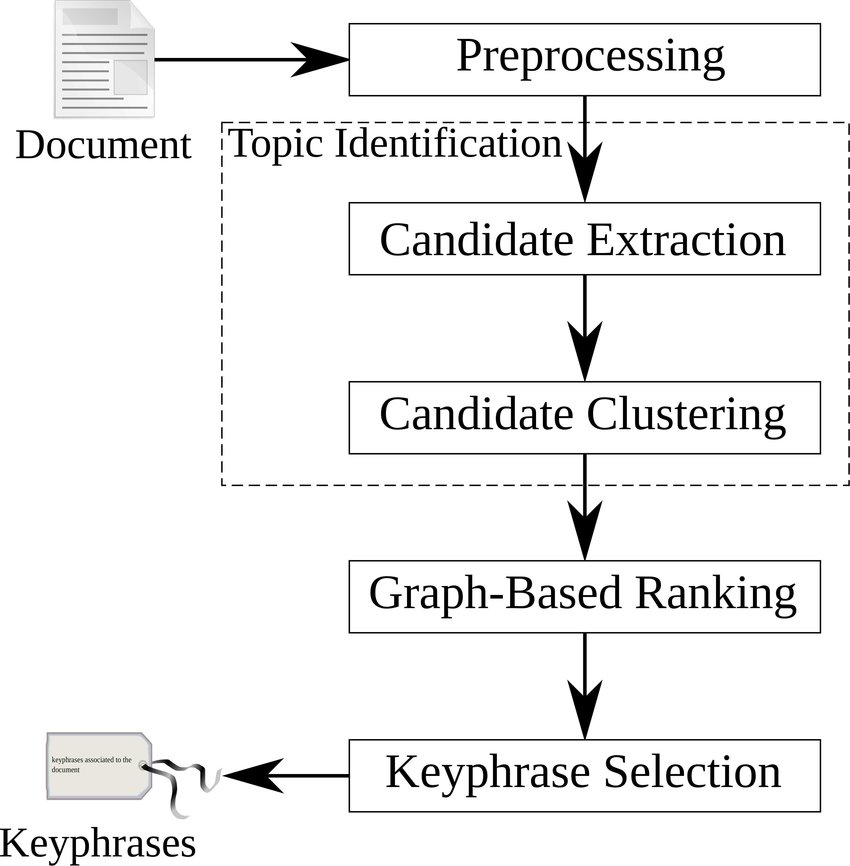
1. Topic Identification and Clustering:
This project follows Wan and Xiao (2008) and extract the longest sequences of nouns and adjectives from the document as keyphrase candidates. Other methods use syntactically filtered n-grams that are most likely to contain a larger number of candidates matching with reference keyphrases, but the n-gram restricted length is a problem. Indeed, n-grams do not always capture as much information as the longest noun phrases. Also, they are less likely to be grammatically correct.
To automatically group similar noun phrases as a single entity, this project uses Hirearchical Agglomerative Clustering algorithm. For this clustering algorithm, vectorized text has been passed to "Jaccard" corfficient for finding similarity between phrases.
2. Graph-Based Ranking:
TextRank(Graph-based ranking model) is used to assign significance score to each topic.To understand how textrank algorithm works please refer : https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
Getting Started
Using this library, you will be able to extract meaningful information from documents like:
- Top N phrases
- Url's
- Email Id's
- Phone numbers
- Important names
Installation
pip3 install topicrankpy
from topicrankpy import extractinformation as t
t.extract_all('path_of_document',no_of_phrases)
Output: For testing purpose, I have used my Resume.
{
'Top_Phrases_With_Ranking': [
('data engineering',
0.03882171811465683),
('machine learning',
0.0231421447805223),
('technologies',
0.01656229201773112),
('algorithms',
0.015179556679089493),
('python',
0.014202240623362651),
('android application',
0.013784183422746128),
('deep learning',
0.012663419387693997),
('cloud services',
0.012062811163957745),
('kafka',
0.011780856748625147),
('elasticsearch',
0.011594082728116736)
],
'Phone_Numbers': [
'4168328255'
],
'Email_address': [
'patelaayush678@gmail.com'
],
'Important Names': [
'Aayush Patel',
'AWS Certified Solutions Architect',
'Award Machine Learning Artificial Intelligence',
'Advance Data Science',
'Google Play Store',
'Chahal Academy',
'Apache Spark Hadoop',
'Kafka',
'Kafka Streams',
'Apache Cassandra',
'Flume',
'Amazon Kinesis',
'Amazon EMR',
'Elastic Map Reduce',
'Machine Learning Deep',
'Data Preprocessing',
'Keras',
'Open CV',
'Python',
'Amazon Web Services',
'Google Cloud Platform',
'System',
'Linux Windows',
'Gujarat',
'Python',
'Cloud',
'Teksun Lab Pvt',
'Ltd',
'Kinesis',
'Collect',
'Applied',
'Python',
'Data',
'Machine Learning Intern',
'Experts Hub',
'Keras',
'Sardar Vallabhbhai Patel Institute Technology',
'Android',
'Kinesis',
'Cognito',
'Desktop Application',
'Python',
'Apache Kafka',
'Apache Cassandra Elasticsearch',
'Twitter API',
'Elastic Load Transform',
'Kafka Connector Sink',
'Cassandra',
'Inspector',
'Ontario Fire Code',
'Build Log Analytics Solutions',
'Google Play Store',
'Trent University'
],
'URLS': [
'https://www.linkedin.com/in/aayushpatel678/',
'https://github.com/Aayushpatel007',
'https://www.youtube.com/watch?v=tvBZz7L5EBI'
]
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file topicrankpy-1.1.0.tar.gz.
File metadata
- Download URL: topicrankpy-1.1.0.tar.gz
- Upload date:
- Size: 20.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.1.0 requests-toolbelt/0.9.1 tqdm/4.40.2 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
891eff5e7c98e8aed026a58db04c0df7c554e75fcb18efba001ad71f2b4f962a
|
|
| MD5 |
af6236a41a987db86a179f62666f77af
|
|
| BLAKE2b-256 |
aa5198e4654c0f05aa25a63f54f8e13fa483b2f50635d4067b215428419890d6
|
File details
Details for the file topicrankpy-1.1.0-py3-none-any.whl.
File metadata
- Download URL: topicrankpy-1.1.0-py3-none-any.whl
- Upload date:
- Size: 21.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.1.0 requests-toolbelt/0.9.1 tqdm/4.40.2 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d91c183cc01d4fda597d786631998ea1d89f4ca8610240c568a3e2c234a72306
|
|
| MD5 |
5345ce63cd0705369a80483897ad6ce6
|
|
| BLAKE2b-256 |
a1d7c104d29f5c2f0a739673ca4306c7680d38b2df5e4381850d879283d36573
|







