Trell Database connectors, slack alerter and loggers


Project description

Trell Pip Package


Table of Contents
- Prerequisites
- Slack Alerter
- Log Formatter
- S3 Connector
- Profile Decorator
- MySQL Connector
- BigQuery Connector
- MongoDB Connector
1. Prerequisites
-
Installation (Any one)
pip install trell-ai-utils
pip install git+https://gitlab.com/trell/trell-ai-util.git
pip install git+https://gitlab.com/trell/trell-ai-util.git@<tag_no>
pip install git+https://gitlab.com/trell/trell-ai-util.git@<branch_name> -
Trell-ai-utils pip package can be utilized if any of the following conditions are met.
-
Trell-ai-utils pip package can be used in any Trell AWS EC2 instance with ds-general-ec2 IAM role attached.
-
Trell-ai-utils pip package can be used if AWS-CLI is locally configured.
- AWS CLI configuration steps :
sudo apt install awscli
aws_access_key_id = *********
aws_secret_access_key = *********
- AWS CLI configuration steps :
-

-
Trell-ai-utils pip package can be used without locally configuring AWS by following ways : -
- Manually configure from pip package utility functions :
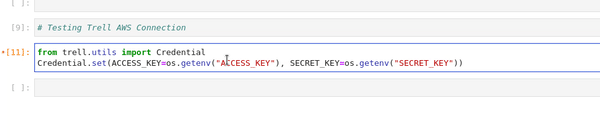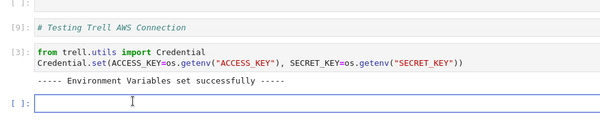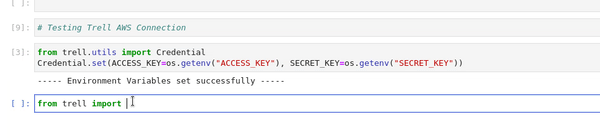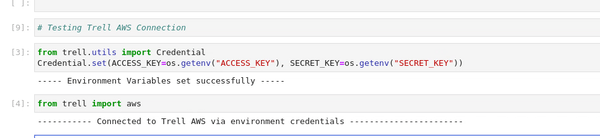
from trell.utils import Credential` Credential.set(ACCESS_KEY="*********", SECRET_KEY="*********")
- Or just export these two environment variables int the terminal via :
export ACCESS_KEY="*********"
export SECRET_KEY="*********"
2. Slack Alerter
Code Snippet Sample :
from trell.Alerter import Alerter
try:
"""Write your code"""
except:
"""Catch exceptions"""
Alerter.send_alert(message=message, url=url, userId=userId, send_error=True)
Alerter Documentation :
class Alerter:
"""Class for sending alerts and monitoring stats to a slack channel"""
def send_alert(message:str, url=url, userId:str=None, send_error:bool=False):
"""
This function send alert to a target channel tagging a user with a alert message and traceback error.
:param: str message : Message to be displayed in the channel
:param: str url : Webhook of target channel (if nothing is passed then #tesing channel will be alerted)
:param: str userId : Slack userId of user who needs to be tagged (format of userid = 'Z0172K2PD5K')
:param: bool send_error : This should be set True, if slack_alert is called while catching exception
returns:
"""
3. Log Formatter
Code Snippet Sample :
from trell.utils import LogFormatter
LogFormatter.apply()
Log Formatter Documentation
class LogFormatter(logging.Formatter):
"""Log Formatter class for trell ai usage"""
__date_format = '%d/%b/%Y:%H:%M:%S %Z'
@staticmethod
def apply(level=logging.INFO):
"""
Start logging in json format.
:return:
"""
4. S3 Connector
Code Snippet Sample :
from trell.S3 import S3
# Uplaoding data to S3
demo = {"Name": "Trell", "Age": 4}
S3.write_to_s3_bucket(python_data_object=demo,
bucket='data-science-datas',
sub_bucket='models/', file_name="demo.pickle")
# Doownlaoding data from S3
demo = S3.read_from_s3_bucket(bucket='data-science-datas',
sub_bucket='models/',
file_name="demo.pickle")
S3 Connector Documentation
class S3:
"""AWS S3 utility functions"""
@staticmethod
def read_from_s3_bucket(bucket='data-science-datas', sub_bucket='tests/', file_name='test.pkl'):
"""
read data stored in S3 bucket
:param string bucket: bucket name
:param string sub_bucket: sub-bucket name
:param string file_name: name of the file to be read
:return old_data : python object stored in the S3
"""
@staticmethod
def write_to_s3_bucket(python_data_object=None, bucket='data-science-datas', sub_bucket='tests/', file_name='test.pkl'):
"""
write python objects/variables etc into S3 bucket
:param string bucket: bucket name
:param string sub_bucket: sub-bucket name
:param string file_name: name of the file to be written
:return None
"""
@staticmethod
def upload_data_from_local_to_s3(model_file_name, bucket='', sub_bucket=''):
"""
write data stored in local machine into S3 bucket from
:param string bucket: bucket name
:param string sub_bucket: sub-bucket name
:param string file_name: name of the file to be written
:return None
"""
5. Profile Decorator
Code Snippet Sample :
from trell.profiler import profiler
@profiler(sort_by='cumulative', lines_to_print=10, strip_dirs=True)
def product_counter_v3():
return [1, 2, 3, 4, 5]
Profiler Documentaion
def profiler(output_file=None, sort_by='cumulative', lines_to_print=None, strip_dirs=False):
"""
A time profiler decorator
:param str output_file: Path of the output file. If only name of the file is given, it's saved in the current
directory. If it's None, the name of the decorated function is used.
:param str sort_by: SortKey enum or tuple/list of str/SortKey enum Sorting criteria for the Stats object. For a list
of valid string and SortKey refer to: https://docs.python.org/3/library/profile.html#pstats.Stats.sort_stats
:param int lines_to_print: Number of lines to print. Default (None) is for all the lines. This is useful in reducing
the size of the printout, especially that sorting by 'cumulative', the time consuming operations are printed toward
the top of the file.
:param bool strip_dirs: Whether to remove the leading path info from file names. This is also useful in reducing the
size of the printout
:return: Profile of the decorated function
"""
6. MySQL Connector
Code Snippet Sample :
# Query from Production MySQL trellDb database
from trell.MySQL import MySQL
query = "select languageId from trellDb.userLanguages where userId = 61668931"
df = MySQL.get_prod_data(query)
# Query from Custom MySQL Database
from trell.MySQL import MySQL
user = "***"
password = "***"
host = "***"
port = "***"
database = "***"
db_string = f"mysql+mysqlconnector://{user}:{password}@{host}:{port}/{database}"
query = "select * from table_name limit 10"
mysql = MySQL(db_string=db_string)
df = mysql.get_data(query = query)
MySQL Connector Documentaion
class MySQL:
"""MySQL database utility functions"""
def __init__(self, db_string):
"""
initialisation method for MySQL connector
:param string db_string: mysql database connection string
"""
def get_data(self, query):
"""
Fetch data from mysql as a dataframe.
:param string query: query for fetching data from table
:return pd.DataFrame data
"""
def execute_query(self, query):
"""
Execute a query in the mysql table
:param string query: query for execution in the table
:return None
"""
def dump_data(self, data, table_name, mode="append"):
"""
Execute a query in the mysql table
:param string query: query for execution in the table
:param string table_name: name of the the target table
:param string mode: it can be either replace or append
:return None
"""
@staticmethod
def get_prod_data_from_local(query):
"""
Fetch data from production mysql from local machine via SSH tunnelling (or local port forwarding).
:param string query: query for execution in the table
:return:
"""
@staticmethod
def get_prod_data(query):
"""
Fetch data from production mysql as a dataframe.
:param string query: query for fetching data from table
:return pd.DataFrame data
"""
@staticmethod
def execute_query_in_prod(query):
"""
Execute a query in the production mysql table
:param string query: query for execution in the table
:return:
"""
@staticmethod
def dump_into_prod(data, table_name, mode="append"):
"""
Push data into production mysql table
:param pd.DataFrame data: dataframe to be appended or replaced
:param string table_name: name of the the target table
:param string mode: it can be either replace or append
:return:
"""
7. BigQuery Connector
Code Snippet Sample :
# Fetching data from BigQuery
from trell.BigQuery import BigQuery
bq = BigQuery(read_big_query_project = "****",
service_account_file_path="***.json")
query = "select * from `trellatale.trellDbDump.userLanguages` limit 2"
# Use one of the following method
df = bq.fetch_data(query) # this uses bigQuery official api for pulling data
df = bq.get_data(query) # this uses pandas_gbq library for pulling data
# Dumping Dataframe in BigQuery
bq.dump_data(database="rahul_temp", table="demo", dataframe=df, mode="append")
# Executing any query in BigQuery
query = "INSERT rahul_temp.Demo (id, userId) VALUES(1,1),(1,1)"
BigQuery.execute_query(query)
# Streaming insert in BigQuery
row_to_insert = [{"id": 1, "userid": 1, "languageId": 58,
"mode":0,"active":1}]
BigQuery.insert_rows_in_bigquery(dataset="rahul_temp", table="Demo", rows_to_insert=row_to_insert)
BigQuery Connector Documentaion
class BigQuery:
"""BigQuery database utility functions"""
def __init__(self, read_big_query_project = config.READ_BIG_QUERY_PROJECT,
write_big_query_project = config.WRITE_BIG_QUERY_PROJECT,
service_account_file_path=config.BIG_QUERY_SERVICE_ACCOUNT_FILE_PATH):
"""
initialisation method for BigQuery Connector
:param str read_big_query_project : project used while reading from BigQuery
:param str write_big_query_project: project used while writing into BigQuery
:param str service_account_file_path: project specific BigQuery Credential
"""
def get_data(self, query=None, query_config=None, max_retries=0, time_interval=5):
"""
Fetches data from from BigQuery's PandasGBQ API
:param string query: query for fetching data from table
:param string query_cofig: config for parameterised query
:param string max_retries: maximum retries if data is not fetched
:param integer time_interval : time interval between retries
"""
def fetch_data(self, query=None, query_config=None, max_retries=0, time_interval=5):
"""
Fetches data from from BigQuery Official API
:param string query: query for fetching data from table
:param string job_cofig: config for parameterised query
:param string max_retries: maximum retries if data is not fetched
:param integer time_interval : time interval between retries
"""
def execute_query(self, query, query_config=None, timeout=900, max_retries=0, time_interval=5):
"""
Executes query from from BigQuery table
:param string query: query for execution
:param string query_cofig: config for parameterised query
:param integer timeout : maximum bigquery execution timeout
:param string max_retries: maximum retries if data is not fetched
:param integer time_interval : time interval between retries
"""
def dump_data(self, database=None, table=None, dataframe=None, mode="append"):
"""
Dumps data into from BigQuery
:param string database: target bigquery database
:param string table: target table name
:param pd.DataFrame dataframe: pandas dataframe for dumping into bigquery
:param string mode: it can be either append or replace
"""
def insert_rows_array(self, dataset=None, table=None, rows_to_insert=None):
"""
Streaming insert into from BigQuery
:param string dataset: target bigquery database
:param string table: target table name
:param list rows_to_insert: list of dictionaries where each dictionary is a row with keys as column names
"""
def insert_rows_in_bigquery(self, dataset=None, table=None, rows_to_insert=None):
"""
Streaming insert into from BigQuery
:param string dataset: target bigquery database
:param string table: target table name
:param list rows_to_insert: list of dictionaries where each dictionary is a row with keys as column names
"""
8. MongoDB Connector
Code Snippet Sample :
uri = "****"
db = "***"
collection = "****"
mongo = MongoAdapter(uri = uri, db = db)
#Reading with pull method
data = mongo.pull_data(collection=collection, list_dict=list_dict)
# Reading with fetch method
query = {'id': {'$in': [1,2]}}
data = mongo.fetch_data(collection, query=query, only_include_keys=["name"])
#Writing inot MongoDB
mongo.push_data(collection = collection, data = data)
#Updating value
id_dict = {"id":"2"}
set_dict = {"$set": {"name":"ram"}}
mongo.update_value(id_dict, set_dict,collection=collection, upsert=True)
# Deleting data
mongo.delete_data(collection=collection, overall=False, condition_dict= {"id":None})
MongoDB Connector Documentaion
class MongoDB:
"""
MongoDB utility functions.
"""
def __init__(self, db=None, uri=None):
"""
initialisation method for MongoDB connector
:param str db: database name
:param str uri: mongo uri string for establishing connection
"""
def push_data(self, data, collection, db=None):
"""
Function for inserting data into db
:param str db : database name
:param str collection : collection name
:param list/pd.DataFrame data : data to be inserted in the form of dataframe or list of dictionaries
:return:
"""
def pull_data(self, list_dict, collection, db=None):
"""
Function for inserting data into db
:param str db : database name
:param str collection : collection name
:param list list_dict : query for fetching data
:return: pd.DataFrame
"""
def update_value(self, id_dict, set_dict, collection, db=None, upsert=None):
"""
Function for updating data into db
:param str db : database name
:param str collection : collection name
:param dict id_dict : query for updation
:param dict set_dict : key and value dictionary to be updated
:param bool upsert : whether to upsert or just update
:return:
"""
def upsert_json(self, output_json, upsert_keys, collection, db=None):
"""
Function for inserting data into db
:param str db : database name
:param str collection : collection name
:param dict output_json : list of dictionaries where each dictionary is a row with keys as column names
:param list upsert_keys : keys to be upserted
:return:
"""
def delete_data(self,collection, db=None, overall=False, condition_dict=None):
"""
Function for inserting data into db
:param str db : database name
:param str collection : collection name
:param bool overall : delete whole collection if True
:param dict condition_dict : query for deletion
:return:
"""
def fetch_data(self, collection, db=None, query={}, only_include_keys=[]):
"""
function to fetch data from the given database and collection on given query
:param str db: db_name in mongo
:param str collection: collection name in mongo for database db
:param dict query: execution query statement; default is {} which means fetch all without any filters
:param list only_include_keys: list of keys to be included while fetching rows
:return: pd.DataFrame
"""
def fetch_data_sorted(self, collection, db=None, pipeline=[]):
"""
function to fetch data from the given database and collection on given query
:param str db: db_name in mongo
:param str collection: collection name in mongo for database db
:param list pipeline: pipeline required to aggregate
:return: pd.DataFrame
"""
9. Cold-Vector Index
Code Snippet Sample :
# Fetching data from BigQuery
from trell.Uservector import Uservector
# If null/not-available pass None
state = "maharastra"
tier = "1"
gender = "1"
age_group = "2"
languageId = "38"
obj = Uservector(state=state,tier=tier,gender=gender,age_group=age_group,languageId=languageId)
s = obj.cold_vector_title()
print(s) #9911238
User-vector Documentation :
class Uservector:
def __init__(self,state=None,tier=None,gender=None,age_group=None,languageId=None ):
'''return embeddings based on input data
:param string state: Name of the state
:param string tier: one of the following(tier1,tier2,tier3,no tier)
:param string gender: one of the following (1,2,3)
:param string age_group: one of the following (0,1,2,3,4)
:param string languageId: language
All inputs will be taken in string. In case you have missing values /null send None --> ""
'''
def cold_vector_title(self):
"""Returns index for a particular cold-user."""
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file trell_ai_utils-2.3.2.tar.gz.
File metadata
- Download URL: trell_ai_utils-2.3.2.tar.gz
- Upload date:
- Size: 28.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.26.0 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.62.2 importlib-metadata/4.11.1 keyring/18.0.1 rfc3986/2.0.0 colorama/0.4.3 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8b04e9e2cc6a7fcf62b8fda5d364a12a22cc4bd2e8d2ce4226407c5e563248c9
|
|
| MD5 |
d7eacbeb777fba97bc4a9a8e71bf3cb5
|
|
| BLAKE2b-256 |
33aa56e9de9348521dcd8c82629feb502235cc4511b750c3bcca83869804725d
|
File details
Details for the file trell_ai_utils-2.3.2-py3-none-any.whl.
File metadata
- Download URL: trell_ai_utils-2.3.2-py3-none-any.whl
- Upload date:
- Size: 28.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.26.0 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.62.2 importlib-metadata/4.11.1 keyring/18.0.1 rfc3986/2.0.0 colorama/0.4.3 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cbfb79cf0c460a18476767eec72ea9d0da658cbdbccbda72bf53adb0f7adb6db
|
|
| MD5 |
6e6cb3b4a72a04c387e17c7ac145eeeb
|
|
| BLAKE2b-256 |
ab16320ff4295787abceb728c093ae22e585e6b02498590e73d6a4ece0e65260
|







