neural network that segments and labels birdsong and other animal vocalizations

Project description



TweetyNet
Now published in eLife: https://elifesciences.org/articles/63853
Code to reproduce results from the article is in the directory ./article
What is tweetynet?
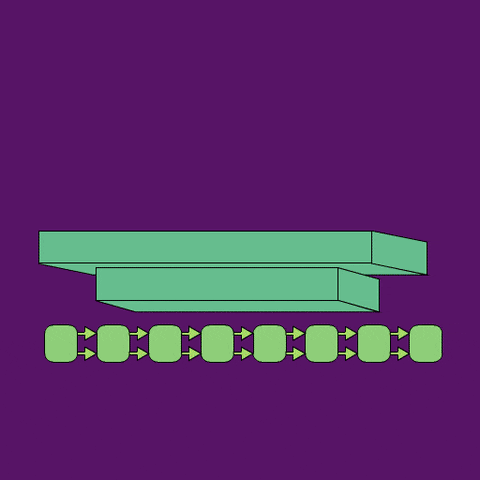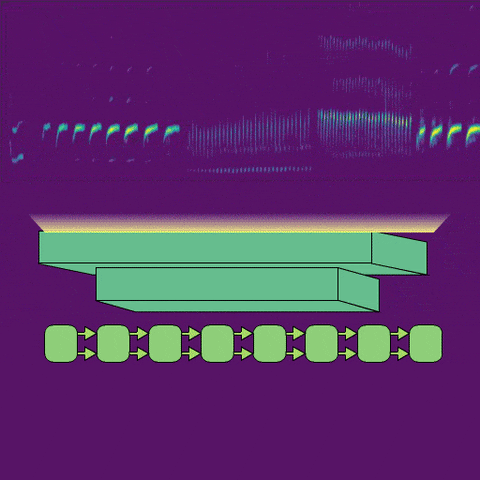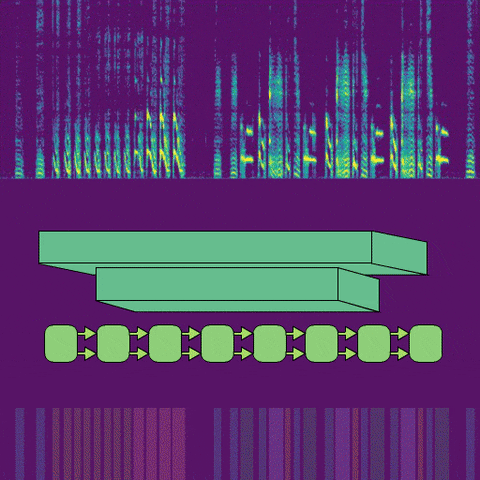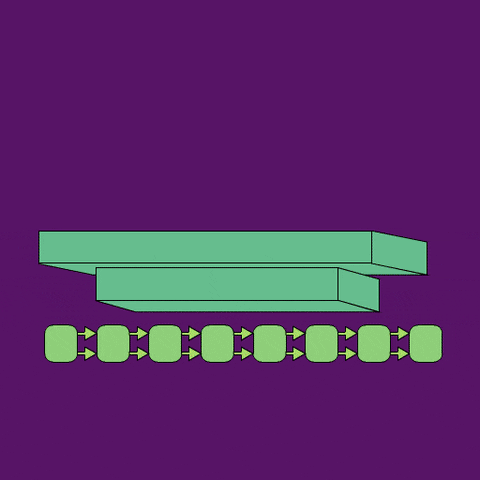
A neural network architecture (shown below) that automates annotation of birdsong and other vocalizations by segmenting spectrograms, and then labeling those segments.

This is an example of the kind of annotations that tweetynet learns to predict:

How is it used?
Installation
Short version (for details see below):
with pip
$ pip install tweetynet
with conda
on Mac and Linux
$ conda install tweetynet -c conda-forge
on Windows
On Windows, you need to add an additional channel, pytorch.
You can do this by repeating the -c option more than once.
$ conda install tweetynet -c conda-forge -c pytorch
$ # ^ notice additional channel!
Long version:
To facilitate training tweetynet models and using trained models
to predict annotation on new datasets,
we developed the vak library,
that is installed automatically with tweetynet.
If you need more information about installation, please see the vak documentation:
https://vak.readthedocs.io/en/latest/get_started/installation.html
Usage
To train models and use them to predict annotation
For a tutorial on using tweetynet with vak, please see the vak documentation:
https://vak.readthedocs.io/en/latest/get_started/autoannotate.html
To reproduce results from article
In the directory ./article
we provide code to reproduce the results in the article
"TweetyNet: A neural network that enables high-throughput, automated annotation of birdsong"
https://elifesciences.org/articles/63853
Please see the README in that directory for instructions on how to install and work with that code.
FAQs
Training data
To train models, you must supply training data in the form of audio files or
spectrogram files, and annotations.
The package can generate spectrograms from .wav or .cbin audio files.
It can also accept spectrograms in the form of Matlab .mat files or .npz files created by numpy.
vak uses a separate library to parse annotations, crowsetta,
which handles some common formats and can also be used to write custom parsers for other formats.
Please see the crowsetta documentation for more detail:
https://crowsetta.readthedocs.io/en/latest/#
Preparing training files
It is possible to train on any manually annotated data but there are some useful guidelines:
- Use as many examples as possible - The results will just be better. Specifically, this code will not label correctly syllables it did not encounter while training and will most probably generalize to the nearest sample or ignore the syllable.
- Use noise examples - This will make the code very good in ignoring noise.
- Examples of syllables on noise are important - It is a good practice to start with clean recordings. The code will not perform miracles and is most likely to fail if the audio is too corrupt or masked by noise. Still, training with examples of syllables on the background of cage noises will be beneficial.
For more details, please see the vak documentation.
Issues
If you run into problems, please use the issue tracker or contact the authors via email in the paper above.
Citation
If you use or adapt this code, please cite its DOI:
License
Released under BSD license.
Contributors ✨
Thanks goes to these wonderful people (emoji key):
 yardencsGitHub 💻 🐛 🔣 📖 🤔 💬 🔧 ⚠️ ✅ 📢 |
 David Nicholson 💻 🐛 🔣 📖 🤔 💬 🔧 ⚠️ ✅ 📢 |
 Zhehao Cheng 🐛 |
This project follows the all-contributors specification. Contributions of any kind welcome!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tweetynet-0.9.0.tar.gz.
File metadata
- Download URL: tweetynet-0.9.0.tar.gz
- Upload date:
- Size: 22.9 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.28.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9b7d74b4ac0e74100537dd9ab2b1e6bb85e6254e4340ffcf30f894fc4e1d13e6
|
|
| MD5 |
9130f49bebaf4872502677b6a7a61c24
|
|
| BLAKE2b-256 |
388dd9e69eca8c2fce52c53c1f601933480ebeb79cc3b29a99d287c1791a6916
|
File details
Details for the file tweetynet-0.9.0-py3-none-any.whl.
File metadata
- Download URL: tweetynet-0.9.0-py3-none-any.whl
- Upload date:
- Size: 9.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.28.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9f6de61de582780d78ea9d37d842d31b724f6a64ade0f92aad9735b90ac6a738
|
|
| MD5 |
df7aa1dd008f5227e1c5c220d67f28c9
|
|
| BLAKE2b-256 |
8f8b5063736816bac85b4834c2488b678b3ff8002bce649c600c372d199f4eb0
|







