No project description provided

Project description
UKBsearch
UKBsearch is a search tool to retreive term(or terms) from UKBiobank HTML files and tab files downloaded in the local drive.


Installation
- from pypi
pip install ukbsearch
- from github
pip install https://github.com/danielmsk/ukbsearch/raw/main/dist/ukbsearch-0.2.1-py3-none-any.whl
Dependency
This UKBsearch requires the following packages:
- rich
- pyreadr
- prettytable
- pandas
- pytabix
Options
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-s, --searchterm search. terms (ex: age smoking)
-s age
-s age smoking
-s 'smok*'
-s '*age' 'smok*'
-l, --logic logical operator for multiple terms [or(default), and]
-s '*age' 'smok*' -l and
-s age 'smok*' -l or
-o, --out title of output file
-o searchresult_20220322
-t, --outtype output type [console(default), csv, udi]
-t csv
-t console csv
-t udi
-t console udi
-p, --path directory path for data files (.html, .Rdata) (default: /data2/UKbiobank/ukb_phenotype)
-p /other/path/for/ukb/html/.
-u, --udilist FileID and UDI list for saving data from tcf files
-u ukb39003 3536-0.0 3536-1.0 3536-2.0
-d, --savedata save data from .Rdata [csv, rdata]
-d csv
-d rdata
-d csv rdata
-i, --index
index tab file and make tcf file (ex. ukb39003.tab)
Usage
Search result
ukbsearch -s 'ag*' 'smok*' -l and
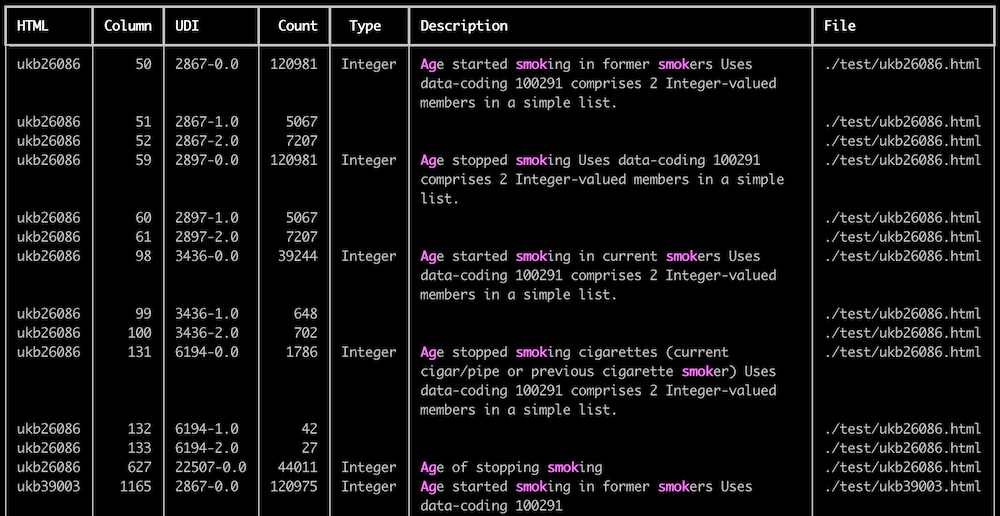
Search for single term
ukbsearch -s age
ukbsearch --searchterm age
ukbsearch -s 'ag*'
ukbsearch -s '*ge'
Search for multiple terms
- The logical operators (
andoror) are supported.
ukbsearch -s age smoking
ukbsearch -s age smoking -l or
ukbsearch -s age smoking -l and
ukbsearch -s 'ag*' 'smok*' -l and
Print only html and UDI
ukbsearch -s 'ag*' 'smok*' -l and -t udi
Save the search result as csv file
ukbsearch -s 'ag*' 'rep*' -l and -o test1 -t csv
(= ukbsearch --searchterm 'ag*' 'rep*' --logic and --out test1 --outtype csv)
ukbsearch -s 'ag*' 'rep*' -l and -o test1 -t console csv
ukbsearch -s 'ag*' 'rep*' -l and -o test1 -t console udi csv
Set a particular directory
- The default path is
/data2/UKbiobank/ukb_phenotype.
ukbsearch -s age -p /other/path/for/ukb/html/.
Index tab file
ukbsearch -i ukb26086.tab
This step generates .tab.tcf.gz, .tab.tcf.gz.tbi, and .tab.tcf.gz.idx. After generating tcf files, the tab file is no longer required to search.
Save data (.csv and .rdata) from .tcf.gz
ukbsearch -u ukb39003 3536-0.0 3536-1.0 3536-2.0 -d csv -o test3
(=ukbsearch --udilist ukb39003 3536-0.0 3536-1.0 3536-2.0 --savedata csv --out test3)
ukbsearch -u ukb39003 3536-0.0 3536-1.0 ukb26086 20161-0.0 21003-1.0 -d csv rdata -o test3
ukbsearch -s 'ag*' 'rep*' -l and -d csv -o test3
ukbsearch -s 'ag*' 'rep*' -l and -d rdata -o test3
Version History
- 0.2.2 (2022-04-05)
- change saving type for a single file
- remove csvi (inversed form) option.
- 0.2.1 (2022-03-25)
- add csvi (inversed form) option.
- debug unsaved values issue.
- 0.2.0 (2022-03-24)
- implementated tab file indexing based on tabix.
- 0.1.1 (2022-03-23)
- changed default path to
/data2/UKbiobank/ukb_phenotype
- changed default path to
- 0.1.0 (2022-03-21)
- first released.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ukbsearch-0.2.2.tar.gz.
File metadata
- Download URL: ukbsearch-0.2.2.tar.gz
- Upload date:
- Size: 13.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/49.6.0 requests-toolbelt/0.9.1 tqdm/4.50.0 CPython/3.8.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3521c59ea6f311590053fa009fd43f9339e8aeccefd6b9df5e99f91f7262cc28
|
|
| MD5 |
656f0e51de5bf5232bce3b6db5c633ed
|
|
| BLAKE2b-256 |
d266b2bbeda1d3930494c50625575fef47cdbc3ac9b5144ed9392ac7a6045caf
|
File details
Details for the file ukbsearch-0.2.2-py3-none-any.whl.
File metadata
- Download URL: ukbsearch-0.2.2-py3-none-any.whl
- Upload date:
- Size: 13.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/49.6.0 requests-toolbelt/0.9.1 tqdm/4.50.0 CPython/3.8.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
64a7c203e54efb31005c46528340d816e3cd2832806e062645678338e047d0a7
|
|
| MD5 |
6ede1278ce0de00f08df7e1969603005
|
|
| BLAKE2b-256 |
4dcf567e8aa2faeba7df758beca07574bc758a29f7f22de634d59e131dd678da
|







