Provide a universal solution for crawler platforms. Read more: https://github.com/ClericPy/uniparser.

Project description
uniparser






Provides a general low-code page parsing solution.
Backwards Compatibility Breaking Warning:
uniparserwill not install any default parsers after version v3.0.0. You can install some of them manually ('selectolax', 'jsonpath-rw-ext', 'objectpath', 'bs4', 'toml', 'pyyaml>=5.3', 'lxml', 'jmespath'). This warning will keep 2 versions.
Install
pip install uniparser -Uor
pip install uniparser[parsers]with default 3rd parsers
Why?
- Reduced the code quantity from plenty of similar crawlers & parsers. Don't Repeat Yourself.
- Make the parsing process of different parsers persistent.
- Separating the crawler code from main app code, no need to redeploy app when adding a new crawler.
- Provide a universal solution for crawler platforms.
- Summarize common string parsing tools on the market.
- The implementation of web views is to be plug-in and portable, which means it can be mounted on other web apps as a sub_app:
app.mount("/uniparser", uniparser_app)
- Here is the low-code web UI screenshot.
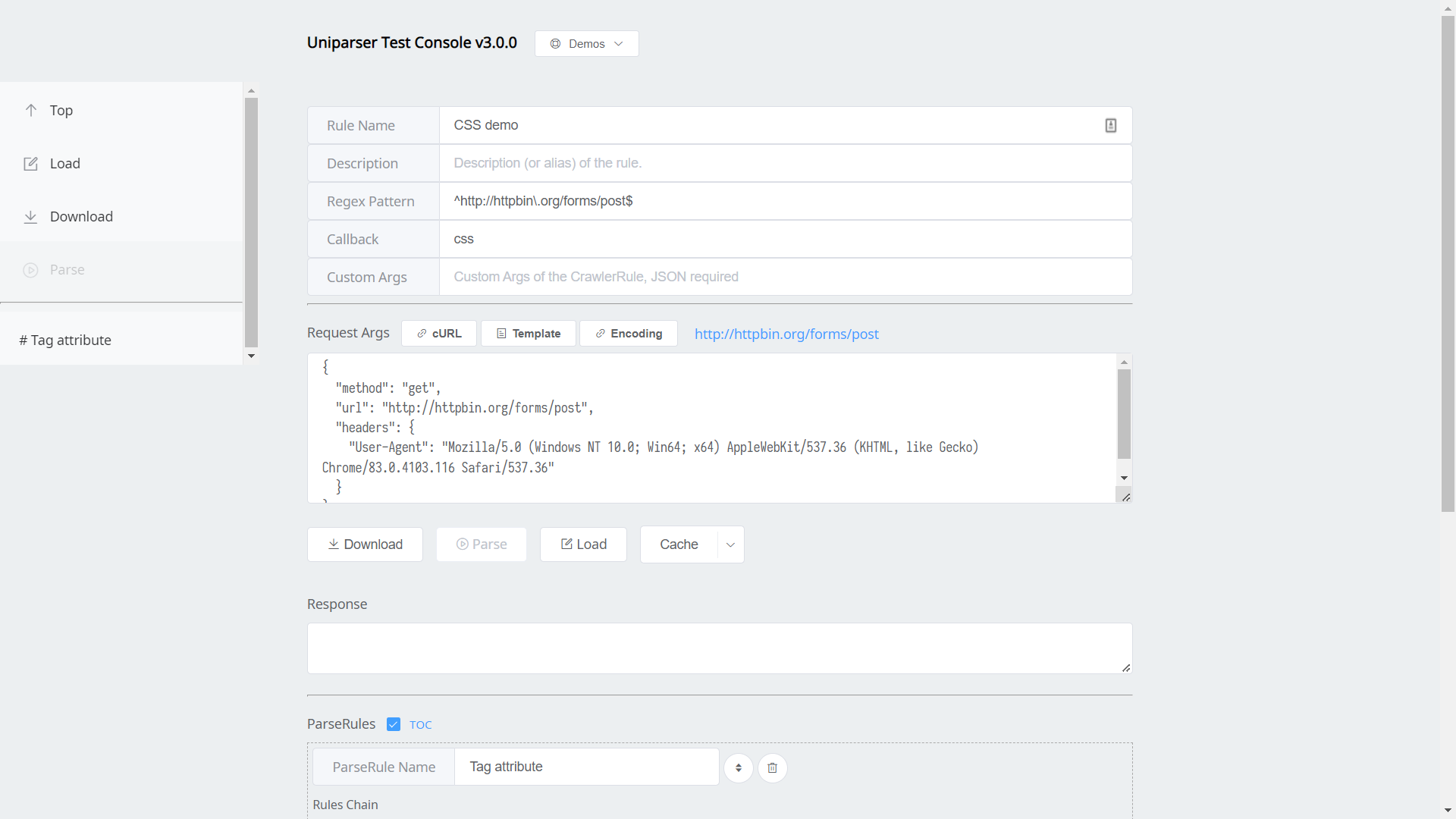
Feature List
-
Support most of popular parsers for HTML / XML / JSON / AnyString / Python object
-
parser list
1. css (HTML) 1. bs4 2. xml 1. lxml 3. regex 4. jsonpath 1. jsonpath-rw-ext 5. objectpath 1. objectpath 6. jmespath 1. jmespath 7. time 8. loader 1. json / yaml / toml 1. toml 2. pyyaml 9. udf 1. source code for exec & eval which named as **parse** 10. python 1. some common python methods, getitem, split, join... 11. *waiting for new ones...*
-
Request args persistence, support curl-string, single-url, dict, json.
-
A simple Web UI for generate & test CrawlerRule.
-
Serializable JSON rule class for saving the whole parsing process.
- Each ParseRule / CrawlerRule / HostRule subclass can be json.dumps to JSON for persistence.
- Therefore, they also can be loaded from JSON string.
- Nest relation of rule names will be treat as the result format. (Rule's result will be ignore if has childs.)
-
Rule Classes
- JsonSerializable is the base class for all the rules.
- dumps classmethod can dump self as a standard JSON string.
- loads classmethod can load self from a standard JSON string, which means the new object will has the methods as a rule.
- ParseRule is the lowest level for a parse mission, which contains how to parse a input_object. Sometimes it also has a list of ParseRule as child rules.
- Parse result is a dict that rule_name as key and result as value.
- CrawlerRule contains some ParseRules, which has 3 attributes besides the rule name:
- request_args tell the http-downloader how to send the request.
- parse_rules is a list of ParseRule, and the parsing result format is like {CrawlerRule_name: {ParseRule1['name']: ParseRule1_result, ParseRule2['name']: ParseRule2_result}}.
- regex tells how to find the crawler_rule with a given url.
- HostRule contains a dict like: {CrawlerRule['name']: CrawlerRule}, with the find method it can get the specified CrawlerRule with a given url.
- JSONRuleStorage is a simple storage way, which saved the HostRules in a JSON file. On the production environment this is not a good choice, maybe redis / mysql / mongodb can give a hand.
- JsonSerializable is the base class for all the rules.
-
Uniparser is the center console for the entire crawler process. It handled download middleware, parse middleware. Detail usage can be find at uniparser.crawler.Crawler, or have a loot at [Quick Start].
-
For custom settings, such as json loader, please update the uniparser.config.GlobalConfig.
Quick Start
Mission: Crawl python Meta-PEPs
Only less than 25 lines necessary code besides the rules(which can be saved outside and auto loaded).
HostRules will be saved at
$HOME/host_rules.jsonby default, not need to init every time.
CrawlerRule JSON & Expected Result
# These rules will be saved at `$HOME/host_rules.json`
crawler = Crawler(
storage=JSONRuleStorage.loads(
r'{"www.python.org": {"host": "www.python.org", "crawler_rules": {"main": {"name":"list","request_args":{"method":"get","url":"https://www.python.org/dev/peps/","headers":{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}},"parse_rules":[{"name":"__request__","chain_rules":[["css","#index-by-category #meta-peps-peps-about-peps-or-processes td.num>a","@href"],["re","^/","@https://www.python.org/"],["python","getitem","[:3]"]],"childs":""}],"regex":"^https://www.python.org/dev/peps/$","encoding":""}, "subs": {"name":"detail","request_args":{"method":"get","url":"https://www.python.org/dev/peps/pep-0001/","headers":{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}},"parse_rules":[{"name":"title","chain_rules":[["css","h1.page-title","$text"],["python","getitem","[0]"]],"childs":""}],"regex":"^https://www.python.org/dev/peps/pep-\\d+$","encoding":""}}}}'
))
expected_result = {
'list': {
'__request__': [
'https://www.python.org/dev/peps/pep-0001',
'https://www.python.org/dev/peps/pep-0004',
'https://www.python.org/dev/peps/pep-0005'
],
'__result__': [{
'detail': {
'title': 'PEP 1 -- PEP Purpose and Guidelines'
}
}, {
'detail': {
'title': 'PEP 4 -- Deprecation of Standard Modules'
}
}, {
'detail': {
'title': 'PEP 5 -- Guidelines for Language Evolution'
}
}]
}
}
The Whole Source Code
from uniparser import Crawler, JSONRuleStorage
import asyncio
crawler = Crawler(
storage=JSONRuleStorage.loads(
r'{"www.python.org": {"host": "www.python.org", "crawler_rules": {"main": {"name":"list","request_args":{"method":"get","url":"https://www.python.org/dev/peps/","headers":{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}},"parse_rules":[{"name":"__request__","chain_rules":[["css","#index-by-category #meta-peps-peps-about-peps-or-processes td.num>a","@href"],["re","^/","@https://www.python.org/"],["python","getitem","[:3]"]],"childs":""}],"regex":"^https://www.python.org/dev/peps/$","encoding":""}, "subs": {"name":"detail","request_args":{"method":"get","url":"https://www.python.org/dev/peps/pep-0001/","headers":{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}},"parse_rules":[{"name":"title","chain_rules":[["css","h1.page-title","$text"],["python","getitem","[0]"]],"childs":""}],"regex":"^https://www.python.org/dev/peps/pep-\\d+$","encoding":""}}}}'
))
expected_result = {
'list': {
'__request__': [
'https://www.python.org/dev/peps/pep-0001',
'https://www.python.org/dev/peps/pep-0004',
'https://www.python.org/dev/peps/pep-0005'
],
'__result__': [{
'detail': {
'title': 'PEP 1 -- PEP Purpose and Guidelines'
}
}, {
'detail': {
'title': 'PEP 4 -- Deprecation of Standard Modules'
}
}, {
'detail': {
'title': 'PEP 5 -- Guidelines for Language Evolution'
}
}]
}
}
def test_sync_crawler():
result = crawler.crawl('https://www.python.org/dev/peps/')
print('sync result:', result)
assert result == expected_result
def test_async_crawler():
async def _test():
result = await crawler.acrawl('https://www.python.org/dev/peps/')
print('sync result:', result)
assert result == expected_result
asyncio.run(_test())
test_sync_crawler()
test_async_crawler()
Uniparser Rule Test Console (Web UI)
- pip install bottle uniparser
- python -m uniparser 8080
- open browser => http://127.0.0.1:8080/
- Download URL
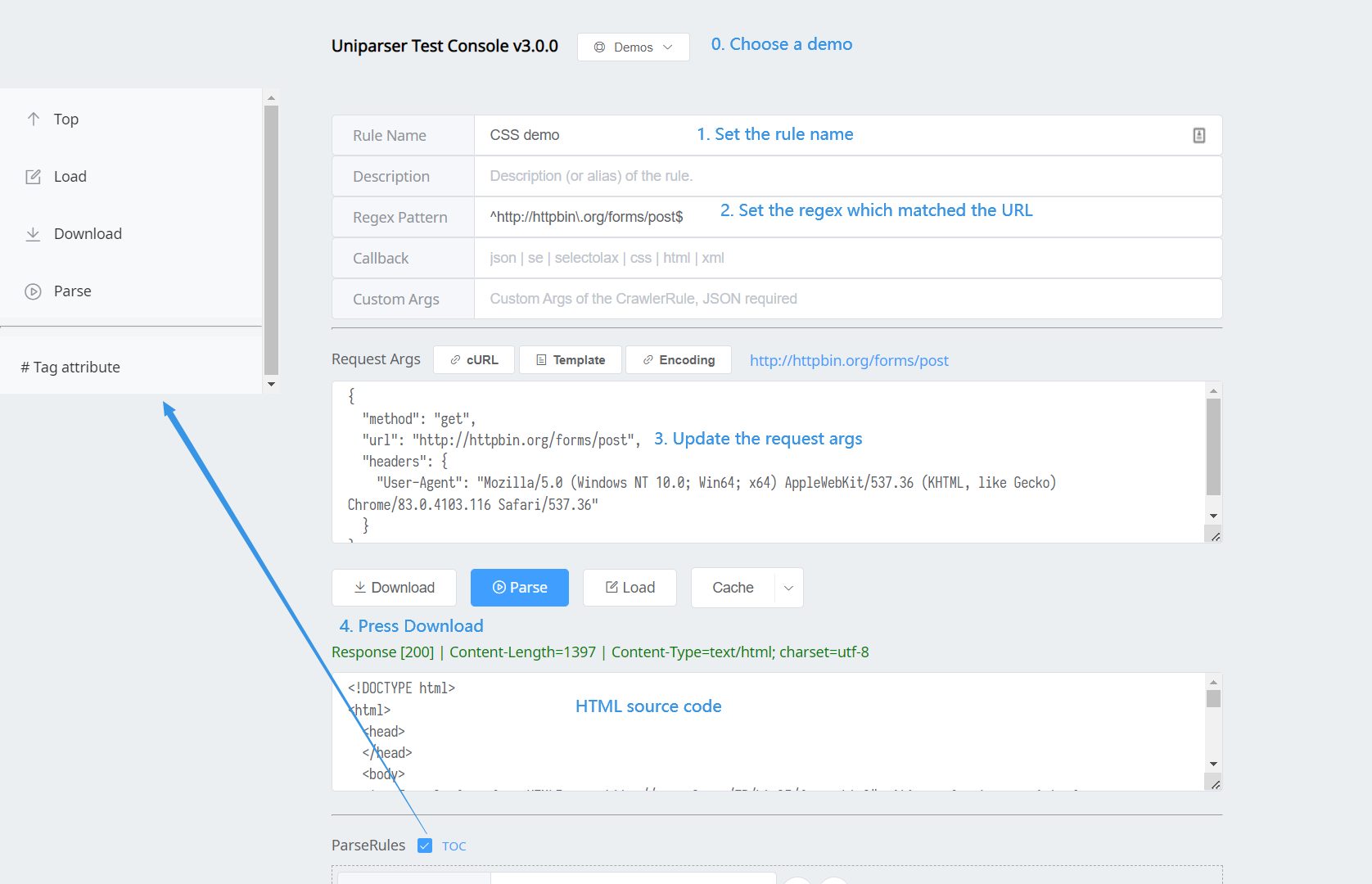
- Parse HTML
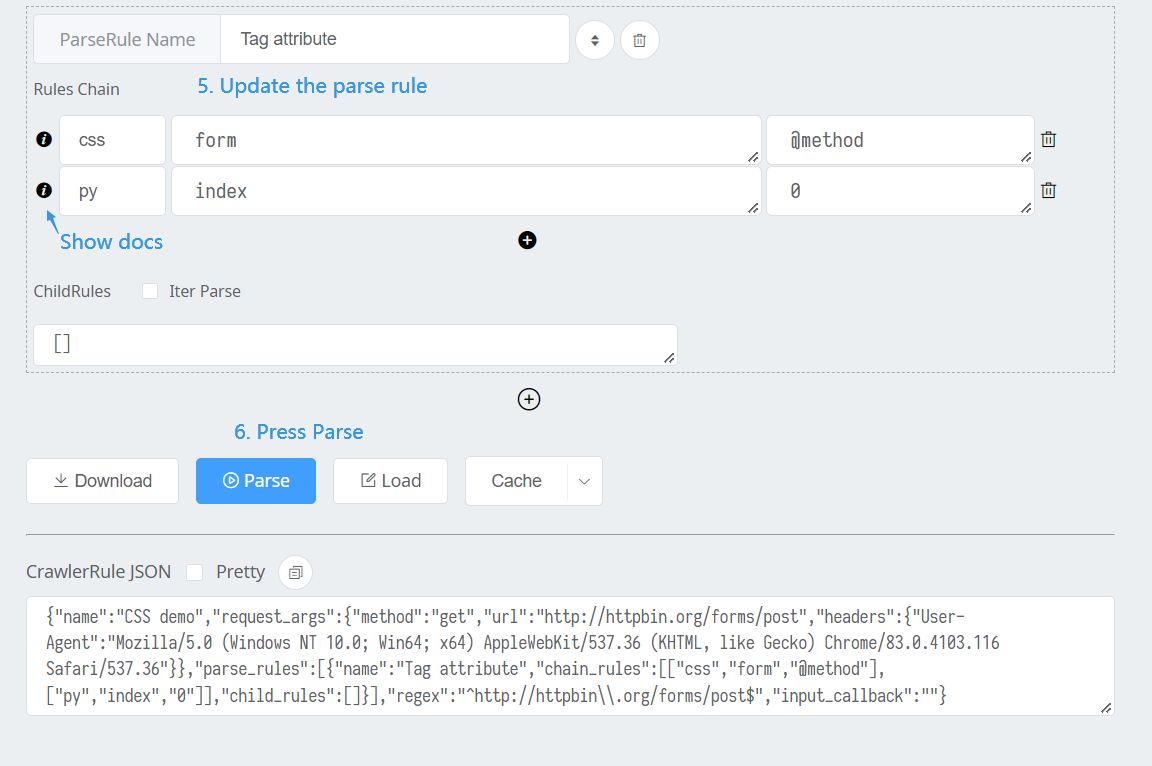
Show result as JSON
{"CSS demo":{"Tag attribute":"post"}}
As we can see, CrawlerRule's name is the root key, and ParseRule's name as the others.
Async environment usage: Fastapi
import uvicorn
from uniparser.fastapi_ui import app
if __name__ == "__main__":
uvicorn.run(app, port=8080)
# http://127.0.0.1:8080
or Fastapi subapp usage
import uvicorn
from fastapi import FastAPI
from uniparser.fastapi_ui import app as sub_app
app = FastAPI()
app.mount('/uniparser', sub_app)
if __name__ == "__main__":
uvicorn.run(app, port=8080)
# http://127.0.0.1:8080/uniparser/
More Usage
Some Demos: Click the dropdown buttons on top of the Web UI
Test Code: test_parsers.py
Advanced Usage: Create crawler rule for watchdogs
Generate parsers doc
from uniparser import Uniparser
for i in Uniparser().parsers:
print(f'## {i.__class__.__name__} ({i.name})\n\n```\n{i.doc}\n```')
Benchmark
Compare parsers and choose a faster one
css: 2558 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '@href']
css: 2491 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$text']
css: 2385 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$innerHTML']
css: 2495 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$html']
css: 2296 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$outerHTML']
css: 2182 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$string']
css: 2130 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$self']
=================================================================================
css1: 2525 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '@href']
css1: 2402 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$text']
css1: 2321 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$innerHTML']
css1: 2256 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$html']
css1: 2122 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$outerHTML']
css1: 2142 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$string']
css1: 2483 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$self']
=================================================================================
selectolax: 15187 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '@href']
selectolax: 19164 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$text']
selectolax: 19699 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$html']
selectolax: 20659 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$outerHTML']
selectolax: 20369 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$self']
=================================================================================
selectolax1: 17572 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '@href']
selectolax1: 19096 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$text']
selectolax1: 17997 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$html']
selectolax1: 18100 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$outerHTML']
selectolax1: 19137 calls / sec, ['<a class="url" href="/">title</a>', 'a.url', '$self']
=================================================================================
xml: 3171 calls / sec, ['<dc:creator><![CDATA[author]]></dc:creator>', 'creator', '$text']
=================================================================================
re: 220240 calls / sec, ['a a b b c c', 'a|c', '@b']
re: 334206 calls / sec, ['a a b b c c', 'a', '']
re: 199572 calls / sec, ['a a b b c c', 'a (a b)', '$0']
re: 203122 calls / sec, ['a a b b c c', 'a (a b)', '$1']
re: 256544 calls / sec, ['a a b b c c', 'b', '-']
=================================================================================
jsonpath: 28 calls / sec, [{'a': {'b': {'c': 1}}}, '$..c', '']
=================================================================================
objectpath: 42331 calls / sec, [{'a': {'b': {'c': 1}}}, '$..c', '']
=================================================================================
jmespath: 95449 calls / sec, [{'a': {'b': {'c': 1}}}, 'a.b.c', '']
=================================================================================
udf: 58236 calls / sec, ['a b c d', 'input_object[::-1]', '']
udf: 64846 calls / sec, ['a b c d', 'context["key"]', {'key': 'value'}]
udf: 55169 calls / sec, ['a b c d', 'md5(input_object)', '']
udf: 45388 calls / sec, ['["string"]', 'json_loads(input_object)', '']
udf: 50741 calls / sec, ['["string"]', 'json_loads(obj)', '']
udf: 48974 calls / sec, [['string'], 'json_dumps(input_object)', '']
udf: 41670 calls / sec, ['a b c d', 'parse = lambda input_object: input_object', '']
udf: 31930 calls / sec, ['a b c d', 'def parse(input_object): context["key"]="new";return context', {'key': 'new'}]
=================================================================================
python: 383293 calls / sec, [[1, 2, 3], 'getitem', '[-1]']
python: 350290 calls / sec, [[1, 2, 3], 'getitem', '[:2]']
python: 325668 calls / sec, ['abc', 'getitem', '[::-1]']
python: 634737 calls / sec, [{'a': '1'}, 'getitem', 'a']
python: 654257 calls / sec, [{'a': '1'}, 'get', 'a']
python: 642111 calls / sec, ['a b\tc \n \td', 'split', '']
python: 674048 calls / sec, [['a', 'b', 'c', 'd'], 'join', '']
python: 478239 calls / sec, [['aaa', ['b'], ['c', 'd']], 'chain', '']
python: 191430 calls / sec, ['python', 'template', '1 $input_object 2']
python: 556022 calls / sec, [[1], 'index', '0']
python: 474540 calls / sec, ['python', 'index', '-1']
python: 619489 calls / sec, [{'a': '1'}, 'index', 'a']
python: 457317 calls / sec, ['adcb', 'sort', '']
python: 494608 calls / sec, [[1, 3, 2, 4], 'sort', 'desc']
python: 581480 calls / sec, ['aabbcc', 'strip', 'a']
python: 419745 calls / sec, ['aabbcc', 'strip', 'ac']
python: 615518 calls / sec, [' \t a ', 'strip', '']
python: 632536 calls / sec, ['a', 'default', 'b']
python: 655448 calls / sec, ['', 'default', 'b']
python: 654189 calls / sec, [' ', 'default', 'b']
python: 373153 calls / sec, ['a', 'base64_encode', '']
python: 339589 calls / sec, ['YQ==', 'base64_decode', '']
python: 495246 calls / sec, ['a', '0', 'b']
python: 358796 calls / sec, ['', '0', 'b']
python: 356988 calls / sec, [None, '0', 'b']
python: 532092 calls / sec, [{0: 'a'}, '0', 'a']
=================================================================================
loader: 159737 calls / sec, ['{"a": "b"}', 'json', '']
loader: 38540 calls / sec, ['a = "a"', 'toml', '']
loader: 3972 calls / sec, ['animal: pets', 'yaml', '']
loader: 461297 calls / sec, ['a', 'b64encode', '']
loader: 412507 calls / sec, ['YQ==', 'b64decode', '']
=================================================================================
time: 39241 calls / sec, ['2020-02-03 20:29:45', 'encode', '']
time: 83251 calls / sec, ['1580732985.1873155', 'decode', '']
time: 48469 calls / sec, ['2020-02-03T20:29:45', 'encode', '%Y-%m-%dT%H:%M:%S']
time: 74481 calls / sec, ['1580732985.1873155', 'decode', '%b %d %Y %H:%M:%S']
Tasks
- Release to pypi.org
- Upload dist with Web UI
- Add github actions for testing package
- Web UI for testing rules
- Complete the doc in detail
- Compare each parser's performance
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file uniparser-3.0.3-py3-none-any.whl.
File metadata
- Download URL: uniparser-3.0.3-py3-none-any.whl
- Upload date:
- Size: 47.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6081f29f1fd06c17f0de8414bbd775a66676d4451e602d567af71b7b6b2ca9db
|
|
| MD5 |
1da2d3577bca8d8be27f38e2b53e853a
|
|
| BLAKE2b-256 |
8b7ccffe9bf76408d0a0e514a3dfd2e4266685628a1928f436ee31ae76c51323
|







