Library to parse and write Universal Ink Model data files.

Project description
Universal Ink Library










Universal Ink Library is a pure Python package for working with Universal Ink Models (UIM). The UIM defines a language-neutral and platform-neutral data model for representing and manipulating digital ink data captured using an electronic pen or stylus, or using touch input.
The main aspects of the UIM are:
- Interoperability of ink-based data models by defining a standardized interface with other systems
- Biometric data storage mechanism
- Spline data storage mechanism
- Rendering configurations storage mechanism
- Ability to compose spline/raw-input based logical trees, which are contained within the ink model
- Portability, by enabling conversion to common industry standards
- Extensibility, by enabling the description of ink data related semantic meta-data
- Standardized serialization mechanism
This reference document defines a RIFF container and Protocol Buffers schema for serialization of ink models as well as a standard mechanism to describe relationships between different parts of the ink model, and/or between parts of the ink model and external entities.
The specified serialization schema is based on the following standards:
- Resource Interchange File Format (RIFF) - A generic file container format for storing data in tagged chunks
- Protocol Buffers v3 - A language-neutral, platform-neutral extensible mechanism for serializing structured data
- Resource Description Framework (RDF) - A standard model for data interchange on the Web
- OWL 2 Web Ontology Language (OWL2) - An ontology language for the Semantic Web with formally defined meaning
Data Model
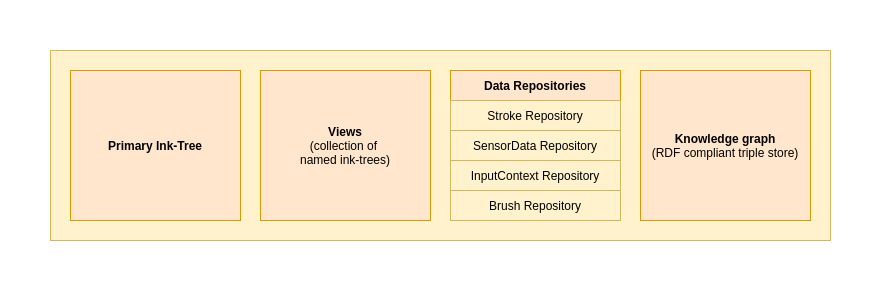
The Universal Ink Model has five fundamental categories:
- Input data: A collection of data repositories, holding raw sensor input, input device/provider configurations, sensor channel configurations, etc. Each data repository keeps certain data-sets isolated and is responsible for specific type(s) of data
- Ink data: The visual appearance of the digital ink, presented as ink geometry with rendering configurations
- Meta-data: Related meta-data about the environment, input devices, etc.
- Ink Trees / Views: A collection of logical trees, representing structures of hierarchically organized paths or raw input data-frames
- Semantic triple store: An RDF compliant triple store, holding semantic information, such as text structure, handwriting recognition results, and semantic entities
The diagram below illustrates the different logical parts of the ink model.
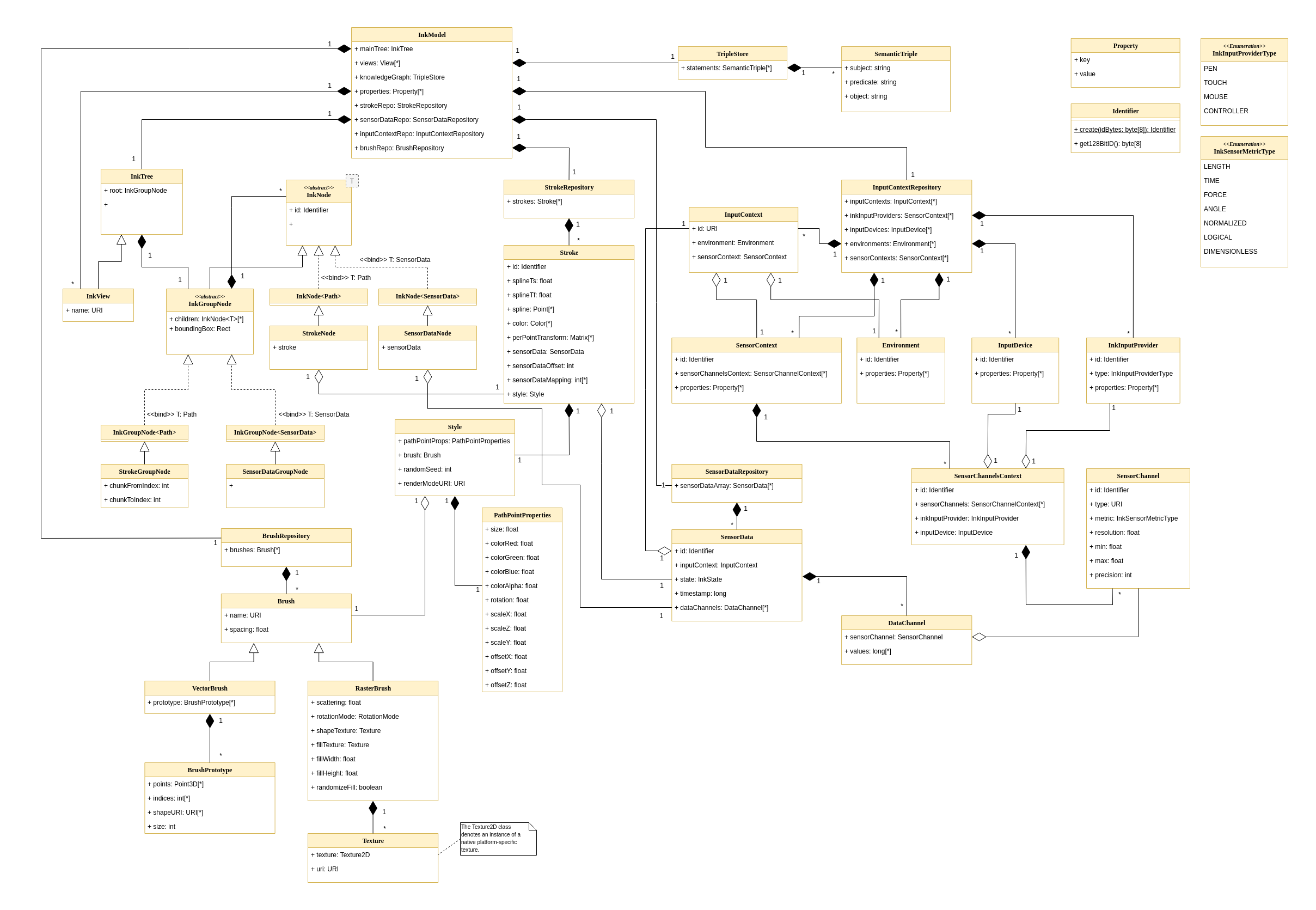
This UML diagram illustrates the complete Ink Model in terms of logical models and class dependencies.
The Universal Ink Model provides the flexibility required for a variety of applications, since the display of pen data is only one aspect. For example, the same data can be used for data mining or even signature comparison, while the ink display can be on a range of platforms potentially requiring different scaling and presentation.
Input data
In reality, pen data is captured from a pen device as a set of positional points:
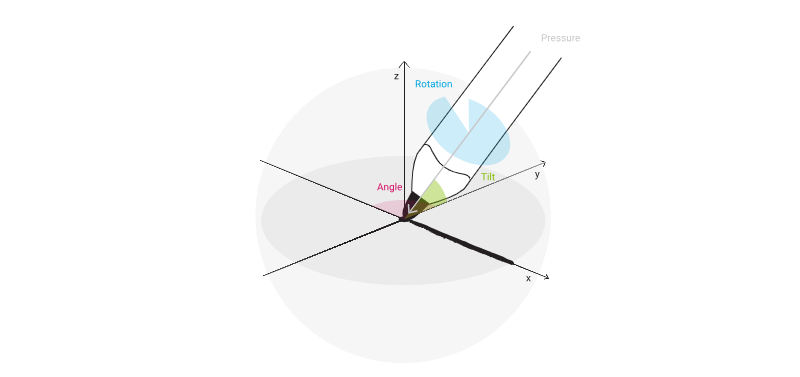
Depending on the type of hardware, in addition to the x/y positional coordinates, the points can contain further information such as pen tip force and angle. Collectively, this information is referred to as sensor data and the Universal Ink Model provides a means of storing all the available data. For example, with some types of hardware, pen hover coordinates can be captured while the pen is not in contact with the surface. The information is saved in the Universal Ink Model and can be used when required.
Ink data
Ink data is the result of the ink geometry pipeline of the WILL SDK for ink. Pen strokes are identified as continuous sets of pen coordinates captured while the pen is in contact with the surface. For example, writing the letter ‘w', as illustrated below. The process converts each pen stroke into a mathematical representation, which can then be used to render the shape on a display. Steps in the so-called Ink Geometry pipeline are illustrated below where each step is configured by an application to generate the desired output:

As a result, the data points are smoothed and shaped to produce the desired representation. For example, simulating the appearance of a felt-tip ink pen. Raster and vector rendering is supported with a selection of rendering brush types.
The results are saved as Ink data, containing ink geometry and rendering information.
Meta-data
Meta-data is added as data about the pen data. The Universal Ink Model allows for administrative information such as author name, location, pen data source, etc. Further meta-data is computed by analysis of the pen data. An example of digital ink is annotated below:
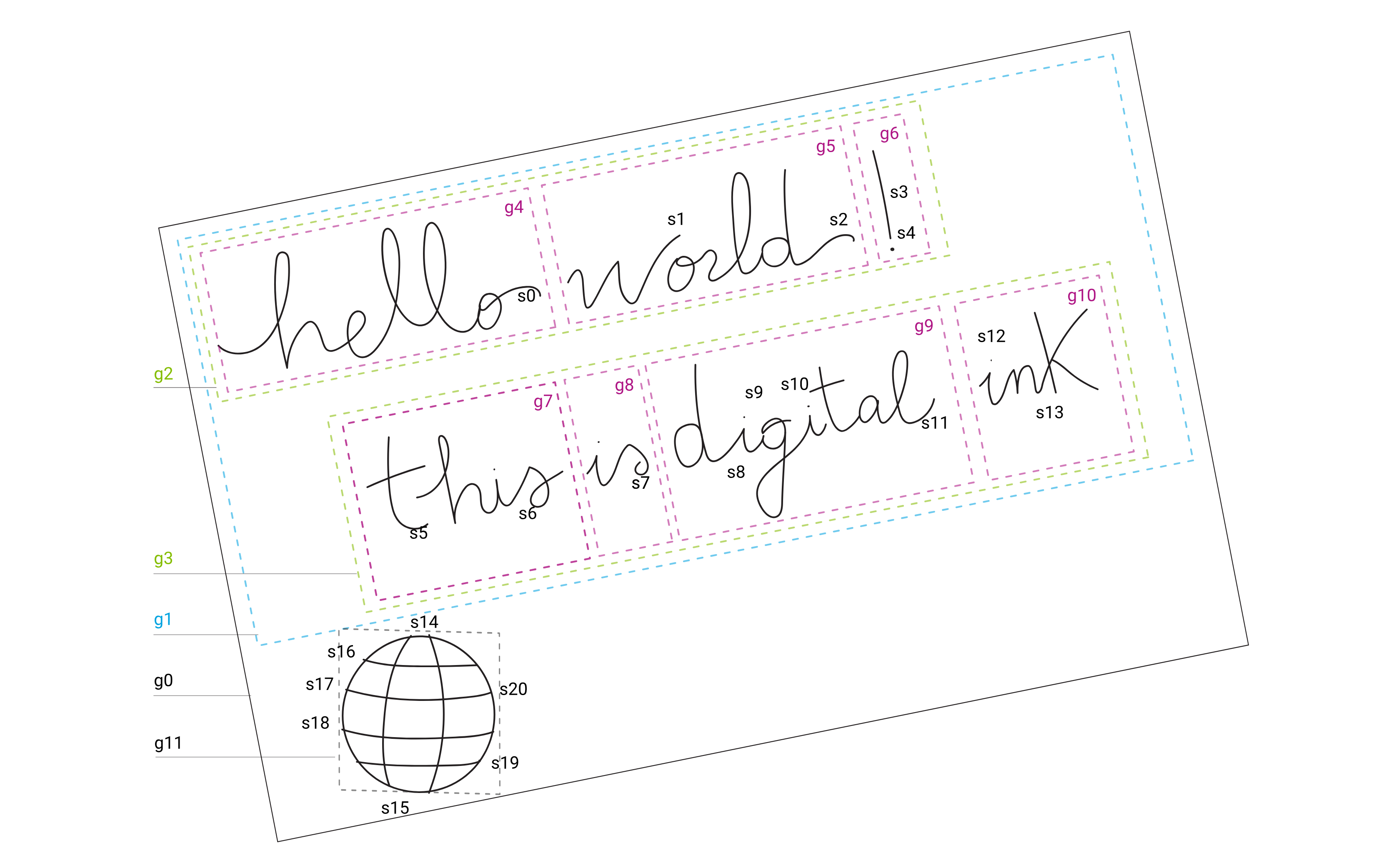
The labels identify pen strokes s1, s2, s3, etc. In addition, groups of strokes are identified as g1, g2, g3, etc. Pen strokes are passed to a handwriting recognition engine, and the results are stored as additional meta-data, generally referred to as semantic data. The semantic data is stored with reference to the groups, categorized as single characters, individual words, lines of text, and so on.
Semantic Data
The Ink Model Specification provides a standard mechanism to describe relationships between different parts of the ink model, and/or between parts of the ink model and external entities. The Ink Model keeps an instance of a RDF or WODL-compliant triple store, called Knowledge Graph in the scope of this document. This triple store holds a list of semantic triples to encode relationships between subject, predicate and object as defined in the RDF specification.
Using the knowledge graph nodes of the ink trees, contained within the ink model, could be annotated with additional metadata in order to describe different aspects of the ink model, for instance - text segmentation view, named entity recognition view, etc.
Wacom Ontology Definition Language (WODL)
At a fundamental level, digital ink can be used producing content, such as text, math, diagrams, sketches etc.
The Wacom Ontology Description Language (WODL) provides a standardized, JSON-based way of annotating ink with a specialized schema definition.
The specification of WODL language is available here. Some of the most common schema definitions are:
- (Segmentation Schema)[https://developer-docs.wacom.com/docs/specifications/schemas/segmentation/]
- (Math Structures Schema)[https://developer-docs.wacom.com/docs/specifications/schemas/math-structures/]
- (Named Entity Recognition Schema)[https://developer-docs.wacom.com/docs/specifications/schemas/ner/]
Installation
Our Universal Ink Library can be installed using pip.
$ pip install universal-ink-library
Quick Start
File handling
Loading UIM
The UIMParser is be used to load a serialized Universal Ink Model in version 3.0.0 or 3.1.0 and you receive the memory model InkModel which can be used for extracting the relevant data.
from uim.codec.parser.uim import UIMParser
from uim.model.ink import InkModel
parser: UIMParser = UIMParser()
# ---------------------------------------------------------------------------------
# Parse a UIM file version 3.0.0
# ---------------------------------------------------------------------------------
ink_model_1: InkModel = UIMParser().parse('../ink/uim_3.0.0/1) Value of Ink 1.uim')
# ---------------------------------------------------------------------------------
# Parse a UIM file version 3.1.0
# ---------------------------------------------------------------------------------
ink_model_2: InkModel = UIMParser().parse('../ink/uim_3.1.0/1) Value of Ink 1.uim')
Saving of UIM
Saving the InkModel as a Universal Ink Model file.
from uim.codec.writer.encoder.encoder_3_1_0 import UIMEncoder310
from uim.model.ink import InkModel
ink_model: InkModel = InkModel()
...
# Save the model, this will overwrite an existing file
with open('3_1_0.uim', 'wb') as uim:
# unicode(data) auto-decodes data to unicode if str
uim.write(UIMEncoder310().encode(ink_model))
Find the sample, here
InkModel
Iterate over semantics
If the InkModel is enriched with semantics from handwriting recognition and named entity recognition, or named entity linking.
The semantics an be access with a helper function uim_extract_text_and_semantics_from or by iterating the views, like shown in uim_extract_text_and_semantics_from function:
from pathlib import Path
from uim.codec.parser.uim import UIMParser
from uim.model.helpers.text_extractor import uim_extract_text_and_semantics_from
from uim.model.ink import InkModel
from uim.model.semantics.schema import CommonViews
if __name__ == '__main__':
parser: UIMParser = UIMParser()
ink_model: InkModel = parser.parse(Path(__file__).parent / '..' / 'ink' / 'uim_3.1.0' /
'2) Digital Ink is processable 1 (3.1 delta).uim')
if ink_model.has_knowledge_graph() and ink_model.has_tree(CommonViews.HWR_VIEW.value):
# The sample
words, entities, text = uim_extract_text_and_semantics_from(ink_model, hwr_view=CommonViews.HWR_VIEW.value)
print('=' * 100)
print(' Recognised text: ')
print(text)
print('=' * 100)
print(' Words:')
print('=' * 100)
for word_idx, word in enumerate(words):
print(f' Word #{word_idx + 1}:')
print(f' Text: {word["text"]}')
print(f' Alternatives: {word["alternatives"]}')
print(f' Bounding box: x:={word["bounding_box"]["x"]}, y:={word["bounding_box"]["y"]}, '
f'width:={word["bounding_box"]["width"]}, height:={word["bounding_box"]["height"]}')
print('')
print('=' * 100)
print(' Entities:')
print('=' * 100)
entity_idx: int = 1
for entity_uri, entity_mappings in entities.items():
print(f' Entity #{entity_idx}: URI: {entity_uri}')
print("-" * 100)
print(f" Label: {entity_mappings[0]['label']}")
print(' Ink Stroke IDs:')
for word_idx, entity in enumerate(entity_mappings):
print(f" #{word_idx + 1}: Word match: {entity['path_id']}")
print('=' * 100)
entity_idx += 1
Find the sample, here
A more generic approach to extract schema elements is the helper function uim_schema_semantics_from.
This function extracts schema elements from the ink model, like math structures, text, tables, etc..
An example for extracting math structures is shown below:
{
'node_uri': UUID('16918b3f-b192-466e-83a3-54835ddfff11'),
'parent_uri': UUID('16918b3f-b192-466e-83a3-54835ddfff11'),
'path_id': [
UUID('16918b3f-b192-466e-83a3-54835ddfff11')
],
'bounding_box': {
'x': 175.71, 'y': 150.65,
'width': 15.91, 'height': 27.018
},
'type': 'will:math-structures/0.1/Symbol',
'attributes': [
('symbolType', 'Numerical'), ('representation', 'e')
]
}
With the extracted schema elements, you can build a tree structure, like shown in the following example:
from pathlib import Path
from typing import List, Dict, Any, Tuple
from uim.codec.parser.uim import UIMParser
from uim.model.helpers.schema_content_extractor import uim_schema_semantics_from
from uim.model.ink import InkModel
from uim.model.semantics.schema import CommonViews
def build_tree(node_list: List[Dict[str, Any]]):
"""
Build a tree structure from the node list.
Parameters
----------
node_list: `List[Dict[str, Any]]`
List of nodes
"""
# Step 1: Create dictionaries for nodes and parent-child relationships
children_dict: Dict[str, Any] = {}
for node in node_list:
parent_uri: str = node['parent_uri']
if parent_uri is not None:
if parent_uri not in children_dict:
children_dict[parent_uri] = []
children_dict[parent_uri].append(node)
# Step 2: Define a recursive function to print the tree
def print_tree(node_display: Dict[str, Any], indent: int = 0):
info: str = ""
attributes: List[Tuple[str, Any]] = node_display.get('attributes', [])
if "path_id" in node_display:
info = f"(#strokes:={len(node_display['path_id'])})"
elif "bounding_box" in node_display:
info = (f"(x:={node_display['bounding_box']['x']}, y:={node_display['bounding_box']['y']}, "
f"width:={node_display['bounding_box']['width']}, "
f"height:={node_display['bounding_box']['height']})")
print('|' + '-' * indent + f" [type:={node_display['type']}] - {info}")
if len(attributes) > 0:
print('|' + ' ' * (indent + 4) + "| -[Attributes:]")
for key, value in attributes:
print('|' + ' ' * (indent + 8) + f"\t|-- {key}:={value}")
if node_display['node_uri'] in children_dict:
for child in children_dict[node_display['node_uri']]:
print_tree(child, indent + 4)
# Step 3: Find the root node (where parent_uri is None) and start printing the tree
for node in node_list:
if node['parent_uri'] is None:
print_tree(node)
if __name__ == '__main__':
parser: UIMParser = UIMParser()
# Parse UIM v3.0.0
ink_model: InkModel = parser.parse(Path(__file__).parent / '..' / 'ink' / 'schemas' / 'math-structures.uim')
math_structures: List[Dict[str, Any]] = uim_schema_semantics_from(ink_model,
semantic_view=CommonViews.HWR_VIEW.value)
# Print the tree structure
build_tree(math_structures)
Find the sample, here
Accessing input and ink data
In order to access ink input configuration data, sensor data, or stroke data from InkModel, you can use the following functions:
from pathlib import Path
from typing import Dict
from uuid import UUID
from uim.codec.parser.uim import UIMParser
from uim.model.ink import InkModel
from uim.model.inkinput.inputdata import InkInputType, InputContext, SensorContext, InputDevice
from uim.model.inkinput.sensordata import SensorData
if __name__ == '__main__':
parser: UIMParser = UIMParser()
# This file contains ink from different providers: PEN, TOUCH, MOUSE
ink_model: InkModel = parser.parse(Path(__file__).parent / '..' / 'ink' / 'uim_3.1.0' /
'6) Different Input Providers.uim')
mapping_type: Dict[UUID, InkInputType] = {}
if ink_model.has_ink_structure():
print('InkInputProviders:')
print('-------------------')
# Iterate Ink input providers
for ink_input_provider in ink_model.input_configuration.ink_input_providers:
print(f' InkInputProvider. ID: {ink_input_provider.id} | type: {ink_input_provider.type}')
mapping_type[ink_input_provider.id] = ink_input_provider.type
print()
print('Strokes:')
print('--------')
# Iterate over strokes
for stroke in ink_model.strokes:
print(f'|- Stroke (id:={stroke.id} | points count: {stroke.points_count})')
if stroke.style and stroke.style.path_point_properties:
print(f'| |- Style (render mode:={stroke.style.render_mode_uri} | color:=('
f'red: {stroke.style.path_point_properties.red}, '
f'green: {stroke.style.path_point_properties.green}, '
f'blue: {stroke.style.path_point_properties.green}, '
f'alpha: {stroke.style.path_point_properties.alpha}))')
# Stroke is produced by sensor data being processed by the ink geometry pipeline
sd: SensorData = ink_model.sensor_data.sensor_data_by_id(stroke.sensor_data_id)
# Get InputContext for the sensor data
input_context: InputContext = ink_model.input_configuration.get_input_context(sd.input_context_id)
# Retrieve SensorContext
sensor_context: SensorContext = ink_model.input_configuration\
.get_sensor_context(input_context.sensor_context_id)
for scc in sensor_context.sensor_channels_contexts:
# Sensor channel context is referencing input device
input_device: InputDevice = ink_model.input_configuration.get_input_device(scc.input_device_id)
print(f'| |- Input device (id:={input_device.id} | type:=({mapping_type[scc.input_provider_id]})')
# Iterate over sensor channels
for c in scc.channels:
print(f'| | |- Sensor channel (id:={c.id} | name: {c.type.name} '
f'| values: {sd.get_data_by_id(c.id).values}')
print('|')
Find the sample, here
Creating an Ink Model
Creating an InkModel from the scratch.
The csv file contains sensor data for strokes.
The script loads the sensor data from the CSV file and creates strokes from the sensor data.
idx,SPLINE_X,SPLINE_Y,SENSOR_TIMESTAMP,SENSOR_PRESSURE,SENSOR_ALTITUDE,SENSOR_AZIMUTH
0,277.1012268066406,183.11183166503906,1722443386312.649,0.07,0.6,0.72
0,277.1012268066406,183.1713409423828,1722443386312.653,0.11000000000000001,0.6,0.72
...
import csv
import uuid
from collections import defaultdict
from pathlib import Path
from typing import List, Dict
from uim.codec.parser.base import SupportedFormats
from uim.codec.writer.encoder.encoder_3_1_0 import UIMEncoder310
from uim.model.base import UUIDIdentifier
from uim.model.helpers.serialize import json_encode
from uim.model.ink import InkModel, InkTree, ViewTree
from uim.model.inkdata.brush import VectorBrush, BrushPolygon, BrushPolygonUri
from uim.model.inkdata.strokes import Spline, Style, Stroke, LayoutMask
from uim.model.inkinput.inputdata import Environment, InkInputProvider, InkInputType, InputDevice, SensorChannel, \
InkSensorType, InkSensorMetricType, SensorChannelsContext, SensorContext, InputContext, unit2unit, Unit
from uim.model.inkinput.sensordata import SensorData, InkState
from uim.model.semantics import schema
from uim.model.semantics.node import StrokeGroupNode, StrokeNode, URIBuilder
from uim.utils.matrix import Matrix4x4
def create_sensor_data(data_collection: Dict[str, List[float]],
input_context_id: uuid.UUID, channels: List[SensorChannel]) -> SensorData:
"""
Create sensor data from a data collection.
Parameters
----------
data_collection: Dict[str, List[float]]
input_context_id
channels
Returns
-------
SensorData
Instance of SensorData
"""
sd: SensorData = SensorData(UUIDIdentifier.id_generator(), input_context_id=input_context_id, state=InkState.PLANE)
sd.add_data(channels[0], [unit2unit(Unit.DIP, Unit.M, v) for v in data_collection['SPLINE_X']])
sd.add_data(channels[1], [unit2unit(Unit.DIP, Unit.M, v) for v in data_collection['SPLINE_Y']])
sd.add_timestamp_data(channels[2], data_collection['SENSOR_TIMESTAMP'])
sd.add_data(channels[3], data_collection['SENSOR_PRESSURE'])
sd.add_data(channels[4], data_collection['SENSOR_AZIMUTH'])
sd.add_data(channels[5], data_collection['SENSOR_ALTITUDE'])
return sd
def load_sensor_data(csv_path: Path, input_context_id: uuid.UUID, channels: List[SensorChannel]) -> List[SensorData]:
"""
Load sensor data from a CSV file.
Parameters
----------
csv_path: Path
Path to the CSV file
input_context_id: uuid.UUID
Input context ID
channels: List[SensorChannel]
List of sensor channels
Returns
-------
List[SensorData]
List of sensor data
"""
sensor_data_values: List[SensorData] = []
data_collection: Dict[str, List[float]] = defaultdict(list)
with csv_path.open('r') as f:
reader = csv.reader(f)
header: List[str] = next(reader)
if header != ['idx', 'SPLINE_X', 'SPLINE_Y',
'SENSOR_TIMESTAMP', 'SENSOR_PRESSURE', 'SENSOR_ALTITUDE', 'SENSOR_AZIMUTH']:
raise ValueError("Invalid CSV file format")
last_idx: int = 0
for row in reader:
row_idx: int = int(row[0])
if row_idx != last_idx:
sensor_data_values.append(create_sensor_data(data_collection, input_context_id, channels))
data_collection.clear()
for idx, value in enumerate(row[1:], start=1):
data_collection[header[idx]].append(float(value))
last_idx = row_idx
if len(data_collection) > 0:
sensor_data_values.append(create_sensor_data(data_collection, input_context_id, channels))
return sensor_data_values
def create_strokes(sensor_data_items: List[SensorData], style_stroke: Style, x_id: uuid.UUID, y_id: uuid.UUID) \
-> List[Stroke]:
"""
Create strokes from sensor data.
Parameters
----------
sensor_data_items: List[SensorData]
List of sensor data
style_stroke: Style
Style of the stroke
x_id: uuid.UUID
Reference id of x sensor channel
y_id: uuid.UUID
Reference id of y sensor channel
Returns
-------
List[Stroke]
List of strokes
"""
stroke_items: List[Stroke] = []
for sensor_data_i in sensor_data_items:
path: List[float] = []
# The spline path contains x, y values
mask: int = LayoutMask.X.value | LayoutMask.Y.value
for x, y in zip(sensor_data_i.get_data_by_id(x_id).values, sensor_data_i.get_data_by_id(y_id).values):
path.append(unit2unit(Unit.M, Unit.DIP, x))
path.append(unit2unit(Unit.M, Unit.DIP, y))
spline: Spline = Spline(layout_mask=mask, data=path)
# Create a stroke from spline
s_i: Stroke = Stroke(sid=UUIDIdentifier.id_generator(), spline=spline, style=style_stroke)
stroke_items.append(s_i)
return stroke_items
if __name__ == '__main__':
# Creates an ink model from the scratch.
ink_model: InkModel = InkModel(version=SupportedFormats.UIM_VERSION_3_1_0.value)
# Setting a unit scale factor
ink_model.unit_scale_factor = 1.5
# Using a 4x4 matrix for scaling
ink_model.transform = Matrix4x4.create_scale(1.5)
# Properties are added as key-value pairs
ink_model.properties.append(("Author", "Markus"))
ink_model.properties.append(("Locale", "en_US"))
# Create an environment
env: Environment = Environment()
# This should describe the environment in which the ink was captured
env.properties.append(("wacom.ink.sdk.lang", "js"))
env.properties.append(("wacom.ink.sdk.version", "2.0.0"))
env.properties.append(("runtime.type", "WEB"))
env.properties.append(("user.agent.brands", "Chromium 126, Google Chrome 126"))
env.properties.append(("user.agent.platform", "macOS"))
env.properties.append(("user.agent.mobile", "false"))
env.properties.append(("app.id", "sample_create_model_vector"))
env.properties.append(("app.version", "1.0.0"))
ink_model.input_configuration.environments.append(env)
# Ink input provider can be pen, mouse or touch.
provider: InkInputProvider = InkInputProvider(input_type=InkInputType.PEN)
ink_model.input_configuration.ink_input_providers.append(provider)
# Input device is the sensor (pen tablet, screen, etc.)
input_device: InputDevice = InputDevice()
input_device.properties.append(("dev.manufacturer", "Wacom"))
input_device.properties.append(("dev.model", "Wacom One"))
input_device.properties.append(("dev.product.code", "DTC-133"))
input_device.properties.append(("dev.graphics.resolution", "1920x1080"))
ink_model.input_configuration.devices.append(input_device)
# Create a group of sensor channels
sensor_channels: list = [
SensorChannel(channel_type=InkSensorType.X, metric=InkSensorMetricType.LENGTH, resolution=1.0,
ink_input_provider_id=provider.id, input_device_id=input_device.id),
SensorChannel(channel_type=InkSensorType.Y, metric=InkSensorMetricType.LENGTH, resolution=1.0,
ink_input_provider_id=provider.id, input_device_id=input_device.id),
SensorChannel(channel_type=InkSensorType.TIMESTAMP, metric=InkSensorMetricType.TIME, resolution=1000.0,
precision=0,
ink_input_provider_id=provider.id, input_device_id=input_device.id),
SensorChannel(channel_type=InkSensorType.PRESSURE, metric=InkSensorMetricType.NORMALIZED, resolution=1.0,
channel_min=0., channel_max=1.0,
ink_input_provider_id=provider.id, input_device_id=input_device.id),
SensorChannel(channel_type=InkSensorType.ALTITUDE, metric=InkSensorMetricType.ANGLE, resolution=1.0,
channel_min=0., channel_max=1.5707963705062866,
ink_input_provider_id=provider.id, input_device_id=input_device.id),
SensorChannel(channel_type=InkSensorType.AZIMUTH, metric=InkSensorMetricType.ANGLE, resolution=1.0,
channel_min=-3.1415927410125732, channel_max=3.1415927410125732,
ink_input_provider_id=provider.id, input_device_id=input_device.id)
]
# Create a sensor channels context
scc_wacom_one: SensorChannelsContext = SensorChannelsContext(channels=sensor_channels,
ink_input_provider_id=provider.id,
input_device_id=input_device.id,
latency=0,
sampling_rate_hint=240)
# Add sensor channel contexts
sensor_context: SensorContext = SensorContext()
sensor_context.add_sensor_channels_context(scc_wacom_one)
ink_model.input_configuration.sensor_contexts.append(sensor_context)
# Create the input context using the Environment and the Sensor Context
input_context: InputContext = InputContext(environment_id=env.id, sensor_context_id=sensor_context.id)
ink_model.input_configuration.input_contexts.append(input_context)
# Create sensor data
# The CSV file contains sensor data for strokes
# idx,SPLINE_X,SPLINE_Y,SENSOR_TIMESTAMP,SENSOR_PRESSURE,SENSOR_ALTITUDE,SENSOR_AZIMUTH
sensor_data = load_sensor_data(Path(__file__).parent / '..' / 'ink' / 'sensor_data' / 'ink.csv', input_context.id,
sensor_channels)
# Add sensor data to the model
for sensor_data_i in sensor_data:
ink_model.sensor_data.add(sensor_data_i)
# We need to define a brush polygon
points: list = [(10, 10), (0, 10), (0, 0), (10, 0)]
brush_polygons: list = [BrushPolygon(min_scale=0., points=points)]
# Create the brush object using polygons
vector_brush_0: VectorBrush = VectorBrush(
"app://qa-test-app/vector-brush/MyTriangleBrush",
brush_polygons)
# Add it to the model
ink_model.brushes.add_vector_brush(vector_brush_0)
# Add a brush specified with shape Uris
poly_uris: list = [
BrushPolygonUri("will://brush/3.0/shape/Circle?precision=20&radius=1", 0.),
BrushPolygonUri("will://brush/3.0/shape/Ellipse?precision=20&radiusX=1&radiusY=0.5", 4.0)
]
# Define a second brush
vector_brush_1: VectorBrush = VectorBrush(
"app://qa-test-app/vector-brush/MyEllipticBrush",
poly_uris)
# Add it to the model
ink_model.brushes.add_vector_brush(vector_brush_1)
# Specify the layout of the stroke data, in this case the stroke will have variable X, Y and Size properties.
layout_mask: int = LayoutMask.X.value | LayoutMask.Y.value | LayoutMask.SIZE.value
# Create some style
style: Style = Style(brush_uri=vector_brush_1.name)
# Set the color of the strokes
style.path_point_properties.red = 0.1
style.path_point_properties.green = 0.2
style.path_point_properties.blue = 0.4
style.path_point_properties.alpha = 1.0
# Create the strokes
strokes = create_strokes(sensor_data, style, sensor_channels[0].id, sensor_channels[1].id)
# First you need a root group to contain the strokes
root: StrokeGroupNode = StrokeGroupNode(UUIDIdentifier.id_generator())
# Assign the group as the root of the main ink tree
ink_model.ink_tree = InkTree()
ink_model.ink_tree.root = root
# Adding the strokes to the root group
for stroke in strokes:
root.add(StrokeNode(stroke))
# Adding view for handwriting recognition results
hwr_tree: ViewTree = ViewTree(schema.CommonViews.HWR_VIEW.value)
# Add view right after creation, to avoid warnings that tree is not yet attached
ink_model.add_view(hwr_tree)
# Create a root node for the HWR view
hwr_root: StrokeGroupNode = StrokeGroupNode(UUIDIdentifier.id_generator())
hwr_tree.root = hwr_root
ink_model.knowledge_graph.append(schema.SemanticTriple(hwr_root.uri, schema.IS, schema.SegmentationSchema.ROOT))
ink_model.knowledge_graph.append(schema.SemanticTriple(hwr_root.uri, schema.SegmentationSchema.REPRESENTS_VIEW,
schema.CommonViews.HWR_VIEW.value))
# Here you can add the same strokes as in the main tree, but you can organize them in a different way
# (put them in different groups)
# You are not supposed to add strokes that are not already in the main tree.
text_region: StrokeGroupNode = StrokeGroupNode(UUIDIdentifier.id_generator())
hwr_root.add(text_region)
ink_model.knowledge_graph.append(schema.SemanticTriple(text_region.uri, schema.IS,
schema.SegmentationSchema.TEXT_REGION))
# The text_line root denotes the text line
text_line: StrokeGroupNode = StrokeGroupNode(UUIDIdentifier.id_generator())
text_region.add(text_line)
ink_model.knowledge_graph.append(schema.SemanticTriple(text_line.uri, schema.IS,
schema.SegmentationSchema.TEXT_LINE))
# The word node denotes a word
word: StrokeGroupNode = StrokeGroupNode(UUIDIdentifier.id_generator())
text_line.add(word)
ink_model.knowledge_graph.append(schema.SemanticTriple(word.uri, schema.IS, schema.SegmentationSchema.WORD))
ink_model.knowledge_graph.append(schema.SemanticTriple(word.uri, schema.SegmentationSchema.HAS_CONTENT, "ink"))
ink_model.knowledge_graph.append(schema.SemanticTriple(word.uri, schema.SegmentationSchema.HAS_LANGUAGE, "en_US"))
# Add the strokes to the word
for stroke_i in strokes:
word.add(StrokeNode(stroke_i))
# We need a URI builder
uri_builder: URIBuilder = URIBuilder()
# Create a named entity
named_entity_uri: str = uri_builder.build_named_entity_uri(UUIDIdentifier.id_generator())
ink_model.knowledge_graph.append(schema.SemanticTriple(word.uri,
schema.NamedEntityRecognitionSchema.PART_OF_NAMED_ENTITY,
named_entity_uri))
# Add knowledge for the named entity
ink_model.knowledge_graph.append(schema.SemanticTriple(named_entity_uri, "hasPart-0", word.uri))
ink_model.knowledge_graph.append(schema.SemanticTriple(named_entity_uri,
schema.NamedEntityRecognitionSchema.HAS_LABEL, "Ink"))
ink_model.knowledge_graph.append(schema.SemanticTriple(named_entity_uri,
schema.NamedEntityRecognitionSchema.HAS_LANGUAGE, "en_US"))
ink_model.knowledge_graph.append(schema.SemanticTriple(named_entity_uri,
schema.NamedEntityRecognitionSchema.HAS_CONFIDENCE, "0.95"))
ink_model.knowledge_graph.append(schema.SemanticTriple(named_entity_uri,
schema.NamedEntityRecognitionSchema.HAS_ARTICLE_URL,
'https://en.wikipedia.org/wiki/Ink'))
ink_model.knowledge_graph.append(schema.SemanticTriple(named_entity_uri,
schema.NamedEntityRecognitionSchema.HAS_UNIQUE_ID, 'Q127418'))
# Save the model, this will overwrite an existing file
with open('3_1_0_vector.uim', 'wb') as uim:
# unicode(data) auto-decodes data to unicode if str
uim.write(UIMEncoder310().encode(ink_model))
# Convert the model to JSON
with open('ink.json', 'w') as f:
# json_encode is a helper function to convert the model to JSON
f.write(json_encode(ink_model))
Find the sample, here
Converting Ink Model
To JSON
The InkModel can be converted to JSON format using the json_encode helper function.
This is useful for debugging purposes or for storing the model in a human-readable format.
Deserialization is not supported.
from pathlib import Path
from uim.codec.parser.uim import UIMParser
from uim.model.helpers.serialize import json_encode
from uim.model.ink import InkModel
if __name__ == '__main__':
parser: UIMParser = UIMParser()
ink_model: InkModel = parser.parse(Path(__file__).parent / '..' / 'ink' / 'special' / 'ink.uim')
# Convert the model to JSON
with open('ink.json', 'w') as f:
# json_encode is a helper function to convert the model to JSON
f.write(json_encode(ink_model))
Find the sample, here
Sensor data to CSV
The sensor data can be exported to a CSV file.
from pathlib import Path
from typing import List
from uim.codec.parser.uim import UIMParser
from uim.model.helpers.serialize import serialize_sensor_data_csv
from uim.model.ink import InkModel
from uim.model.inkdata.strokes import InkStrokeAttributeType
if __name__ == '__main__':
parser: UIMParser = UIMParser()
# This file contains ink from different providers: PEN, TOUCH, MOUSE
ink_model: InkModel = parser.parse(Path(__file__).parent / '..' / 'ink' / 'special' / 'ink.uim')
# Decide which attributes to serialize
layout: List[InkStrokeAttributeType] = [
InkStrokeAttributeType.SPLINE_X, InkStrokeAttributeType.SPLINE_Y, InkStrokeAttributeType.SENSOR_TIMESTAMP,
InkStrokeAttributeType.SENSOR_PRESSURE, InkStrokeAttributeType.SENSOR_ALTITUDE,
InkStrokeAttributeType.SENSOR_AZIMUTH
]
# Serialize the model to CSV
serialize_sensor_data_csv(ink_model, Path('sensor_data.csv'), layout=layout)
Find the sample, here
Extracting statistics
The StatisticsAnalyzer can be used to extract statistics from the InkModel.
The statistics are extracted from the ink data, sensor data, and input configuration.
from pathlib import Path
from typing import Dict, Any
from uim.codec.parser.uim import UIMParser
from uim.model.ink import InkModel
from uim.utils.statistics import StatisticsAnalyzer
def print_model_stats(key: str, value: Any, indent: str = ""):
"""
Print the model statistics.
Parameters
----------
key: str
Key string
value: Any
Value
indent: str
Indentation
"""
if isinstance(value, float):
print(f'{indent}{key}: {value:.2f}')
elif isinstance(value, int):
print(f'{indent}{key}: {value:d}')
elif isinstance(value, str):
print(f'{indent}{key}: {value}')
elif isinstance(value, Dict):
print(f'{indent}{key}:')
for key_str_2, next_value in value.items():
print_model_stats(key_str_2, next_value, indent + " ")
if __name__ == '__main__':
parser: UIMParser = UIMParser()
ink_model: InkModel = parser.parse(Path(__file__).parent / '..' / 'ink' / 'uim_3.1.0'/
'2) Digital Ink is processable 1 (3.1 delta).uim')
model_analyser: StatisticsAnalyzer = StatisticsAnalyzer()
stats: Dict[str, Any] = model_analyser.analyze(ink_model)
for key_str, value_str in stats.items():
print_model_stats(key_str, value_str)
Find the sample, here
Convert InkML to UIM
In the following examples, we will demonstrate how to convert an InkML file from well-known datasets to UIM.
IAM On-Line Handwriting Database
The implementation supports the IAM On-Line Handwriting Database as a sample dataset for testing the conversion of InkML to UIM. Its annotations can be converted to Wacom Ontology Definition Language (WODL) segmentation schema, by configuring the InkMLParser as follows:
from pathlib import Path
from typing import Dict, Any, List
from uim.codec.writer.encoder.encoder_3_1_0 import UIMEncoder310
from uim.model.helpers.schema_content_extractor import uim_schema_semantics_from
from uim.model.ink import InkModel
from uim.model.semantics.schema import SegmentationSchema, IS
from uim.utils.print import print_tree
from uim.codec.parser.inkml import InkMLParser
if __name__ == '__main__':
parser: InkMLParser = InkMLParser()
parser.set_typedef_pred(IS)
parser.register_type('type', 'Document', SegmentationSchema.ROOT)
parser.register_type('type', 'Formula', SegmentationSchema.MATH_BLOCK)
parser.register_type('type', 'Arrow', SegmentationSchema.CONNECTOR)
parser.register_type('type', 'Table', SegmentationSchema.TABLE)
parser.register_type('type', 'Structure', SegmentationSchema.BORDER)
parser.register_type('type', 'Diagram', SegmentationSchema.DIAGRAM)
parser.register_type('type', 'Drawing', SegmentationSchema.DRAWING)
parser.register_type('type', 'Correction', SegmentationSchema.CORRECTION)
parser.register_type('type', 'Symbol', '<T>')
parser.register_type('type', 'Marking', SegmentationSchema.MARKING)
parser.register_type('type', 'Marking_Bracket', SegmentationSchema.MARKING,
subtypes=[(SegmentationSchema.HAS_MARKING_TYPE, 'other')])
parser.register_type('type', 'Marking_Encircling', SegmentationSchema.MARKING,
subtypes=[(SegmentationSchema.HAS_MARKING_TYPE, 'encircling')])
parser.register_type('type', 'Marking_Angle', SegmentationSchema.MARKING,
subtypes=[(SegmentationSchema.HAS_MARKING_TYPE, 'other')])
parser.register_type('type', 'Marking_Underline', SegmentationSchema.MARKING,
subtypes=[(SegmentationSchema.HAS_MARKING_TYPE,
"underlining")])
parser.register_type('type', 'Marking_Sideline', SegmentationSchema.MARKING,
subtypes=[(SegmentationSchema.HAS_MARKING_TYPE, 'other')])
parser.register_type('type', 'Marking_Connection', SegmentationSchema.CONNECTOR)
parser.register_type('type', 'Textblock', SegmentationSchema.TEXT_REGION)
parser.register_type('type', 'Textline', SegmentationSchema.TEXT_LINE)
parser.register_type('type', 'Word', SegmentationSchema.WORD)
parser.register_type('type', 'Garbage', SegmentationSchema.GARBAGE)
parser.register_type('type', 'List', SegmentationSchema.LIST)
parser.register_value('transcription', SegmentationSchema.HAS_CONTENT)
parser.cropping_ink = False
parser.cropping_offset = 10
ink_model: InkModel = parser.parse(Path(__file__).parent / '..' / 'ink' / 'inkml' / 'iamondb.inkml')
structures: List[Dict[str, Any]] = uim_schema_semantics_from(ink_model, "custom")
print_tree(structures)
with Path("iamondb.uim").open("wb") as file:
file.write(UIMEncoder310().encode(ink_model))
The implementation is provided as a sample and may require additional configuration and testing to work with other datasets.
With the register_type method, the parser can be configured to map the annotation types to the segmentation schema defined in the WODL.
The register_value method can be used to map the annotation values to the content of the segmentation schema.
Note, that this mapping may fully comply with the WODL schema, but it is a sample implementation and may require additional configuration or post-processing.
The sample document from the IAM On-Line Handwriting Database can't be uploaded to the repository due to the license restrictions.
Kondate
The implementation supports the Kondate dataset as a sample dataset for testing the conversion of InkML to UIM.
import uuid
from pathlib import Path
from uim.codec.writer.encoder.encoder_3_1_0 import UIMEncoder310
from uim.model.ink import InkModel
from uim.model.inkdata.brush import BrushPolygonUri, VectorBrush
from uim.model.semantics.schema import SegmentationSchema, CommonViews
from uim.codec.parser.inkml import InkMLParser
if __name__ == '__main__':
parser: InkMLParser = InkMLParser()
# Add a brush specified with shape Uris
bpu_1: BrushPolygonUri = BrushPolygonUri("will://brush/3.0/shape/Circle?precision=20&radius=1", min_scale=0.)
bpu_2: BrushPolygonUri = BrushPolygonUri("will://brush/3.0/shape/Circle?precision=20&radius=0.5", min_scale=4.)
poly_uris: list = [
bpu_1, bpu_2
]
vector_brush_1: VectorBrush = VectorBrush(
"app://qa-test-app/vector-brush/MyEllipticBrush",
poly_uris)
parser.register_brush(brush_uri='default', brush=vector_brush_1)
parser.use_brush = 'default'
device_id: str = uuid.uuid4().hex
parser.update_default_context(sample_rate=80, serial_number=device_id, manufacturer="Test Manufacturer",
model="Test Model")
parser.content_view = CommonViews.HWR_VIEW.value
parser.cropping_ink = True
parser.default_annotation_type = SegmentationSchema.UNLABELED
parser.default_xy_resolution = 10
parser.default_position_precision = 3
parser.default_value_resolution = 42
# Kondate database is not using namespace
parser.default_namespace = ''
ink_model: InkModel = parser.parse(Path(__file__).parent / '..' / 'ink' / 'inkml' / 'kondate.inkml')
with Path("kondate.uim").open("wb") as file:
file.write(UIMEncoder310().encode(ink_model))
The sample document from the Kondate dataset can't be uploaded to the repository due to the license restrictions.
IOT Paper Format
The format encodes the ink as InkML, but additionally it encodes a template image as base64.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<paper xmlns:inkml="http://www.w3.org/2003/InkML"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2003/InkML">
<resource>
<templateImage Content-Type="image/bmp">
<!-- Base64 encoded template -->
</templateImage>
</resource>
<inkml:ink>
<!-- Ink content encoded as InkML -->
</inkml:ink>
</paper>
This sample implementation provides a way to convert the IOT Paper Format to UIM and extract the template image.
from pathlib import Path
from typing import List
from uim.codec.parser.iotpaper import IOTPaperParser
from uim.codec.writer.encoder.encoder_3_1_0 import UIMEncoder310
from uim.model.helpers.serialize import json_encode, serialize_raw_sensor_data_csv
from uim.model.ink import InkModel
from uim.model.inkinput.inputdata import InkSensorType, Unit
if __name__ == '__main__':
paper_file: Path = Path(__file__).parent / '..' / '..' / 'ink' / 'iot' / 'HelloInk.paper'
parser: IOTPaperParser = IOTPaperParser()
parser.cropping_ink = False
parser.cropping_offset = 10
ink_model: InkModel = parser.parse(paper_file)
img: bytes = parser.parse_template(paper_file)
with Path("iot.uim").open("wb") as file:
file.write(UIMEncoder310().encode(ink_model))
with Path("template.bmp").open("wb") as file:
file.write(img)
layout: List[InkSensorType] = [
InkSensorType.TIMESTAMP, InkSensorType.X, InkSensorType.Y, InkSensorType.Z,
InkSensorType.PRESSURE, InkSensorType.ALTITUDE,
InkSensorType.AZIMUTH
]
# In the Universal Ink Model, the sensor data is in SI units:
# - timestamp: seconds
# - x, y, z: meters
# - pressure: N
serialize_raw_sensor_data_csv(ink_model, Path('sensor_data.csv'), layout)
# If you want to convert the data to different units, you can use the following code:
serialize_raw_sensor_data_csv(ink_model, Path('sensor_data_unit.csv'), layout,
{
InkSensorType.X: Unit.MM, # Convert meters to millimeters
InkSensorType.Y: Unit.MM, # Convert meters to millimeters
InkSensorType.Z: Unit.MM, # Convert meters to millimeters
InkSensorType.TIMESTAMP: Unit.MS # Convert seconds to milliseconds
})
# Convert the model to JSON
with open('ink.json', 'w') as f:
# json_encode is a helper function to convert the model to JSON
f.write(json_encode(ink_model))
NOTICE
This implementation is a sample implementation and does not cover all possible cases of InkML files. There is no guarantee that the implementation will work for all InkML files. Additional testing and validation may be required to ensure the correctness of the implementation. Finally, the implementation is provided as-is and without any warranty or support.
Web Demos
The following web demos can be used to produce Universal Ink Model files:
- WILL SDK for ink - Demo - producing UIM 3.1.0 files.
Documentation
You can find more detailed technical documentation, here. API documentation is available here.
Usage
The library is used for machine learning experiments based on digital ink using the Universal Ink Model.
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file universal_ink_library-2.1.1.tar.gz.
File metadata
- Download URL: universal_ink_library-2.1.1.tar.gz
- Upload date:
- Size: 5.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.21
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5fd3e327583abdb04d08828cfc1e56cd7314c544a70e98e1c740d61f80ed70f0
|
|
| MD5 |
92855882c419866e40ffe8c37e03d5dc
|
|
| BLAKE2b-256 |
04841685bf1af89a619bc9742424a85605633dd941d102a2e4b6e10067f612ce
|
File details
Details for the file universal_ink_library-2.1.1-py3-none-any.whl.
File metadata
- Download URL: universal_ink_library-2.1.1-py3-none-any.whl
- Upload date:
- Size: 200.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.21
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
93d816a56459c7bc9b31c7ced1bb836963fa0c853b6e0b21986f1781ff4a9462
|
|
| MD5 |
a1ca9508ec9a61002d776a82a7787a9b
|
|
| BLAKE2b-256 |
76c1c510190653c9f23b4ba0f35ad55bd28b2136a07a13682a7e31ed61adcf98
|







