A neural network framework for researchers studying acoustic communication

Project description

A neural network framework for researchers studying acoustic communication





vak is a Python framework for neural network models,
designed for researchers studying acoustic communication:
how and why animals communicate with sound.
Many people will be familiar with work in this area on
animal vocalizations such as birdsong, bat calls, and even human speech.
Neural network models have provided a powerful new tool for researchers in this area,
as in many other fields.
The library has two main goals:
- Make it easier for researchers studying acoustic communication to apply neural network algorithms to their data
- Provide a common framework that will facilitate benchmarking neural network algorithms on tasks related to acoustic communication
Currently, the main use is an automatic annotation of vocalizations and other animal sounds. By annotation, we mean something like the example of annotated birdsong shown below:
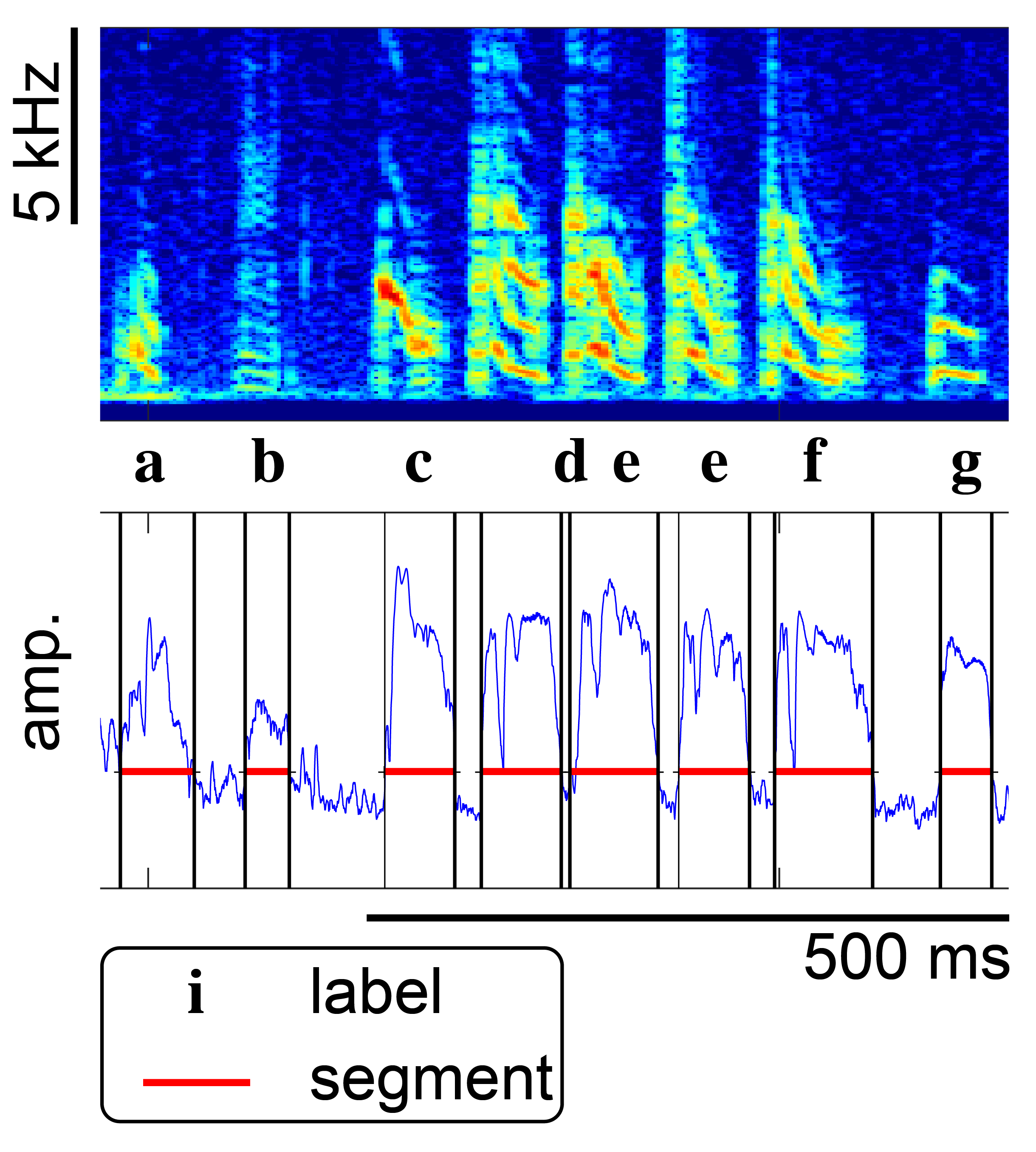
You give vak training data in the form of audio or spectrogram files with annotations,
and then vak helps you train neural network models
and use the trained models to predict annotations for new files.
We developed vak to benchmark a neural network model we call tweetynet.
Please see the eLife article here: https://elifesciences.org/articles/63853
To learn more about the goals and design of vak, please see this talk from the SciPy 2023 conference, and the associated Proceedings paper here.
For more background on animal acoustic communication and deep learning, and how these intersect with related fields like computational ethology and neuroscience, please see the "About" section below.
Installation
Short version:
with pip
$ pip install vak
with conda
$ conda install vak -c pytorch -c conda-forge
$ # ^ notice additional channel!
Notice that for conda you specify two channels,
and that the pytorch channel should come first,
so it takes priority when installing the dependencies pytorch and torchvision.
For more details, please see:
https://vak.readthedocs.io/en/latest/get_started/installation.html
We test vak on Ubuntu and MacOS. We have run on Windows and
know of other users successfully running vak on that operating system,
but installation on Windows may require some troubleshooting.
A good place to start is by searching the issues.
Usage
Tutorial
Currently the easiest way to work with vak is through the command line.
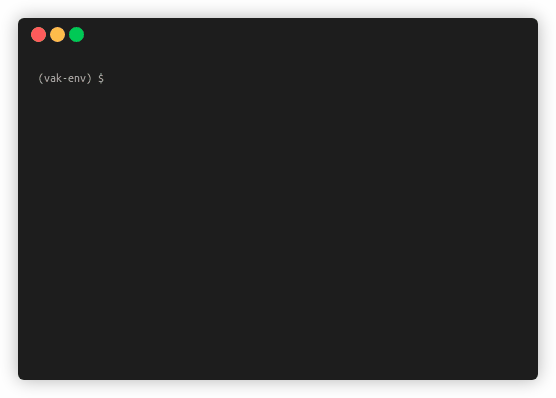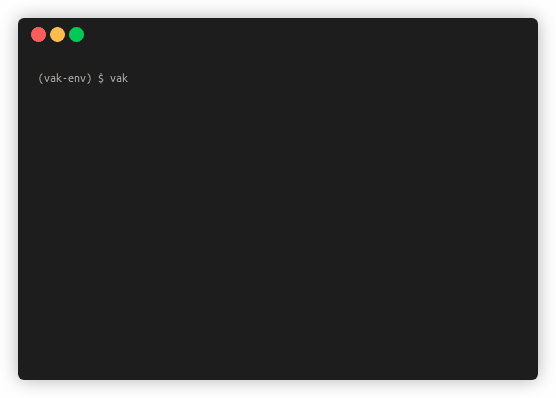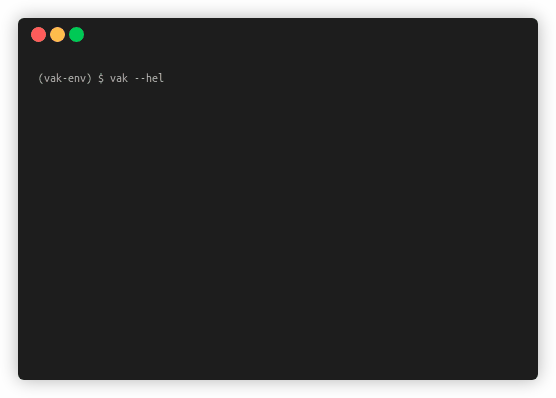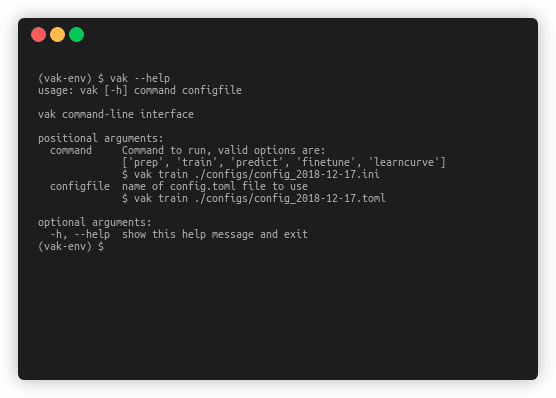
You run it with configuration files, using one of a handful of commands.
For more details, please see the "autoannotate" tutorial here:
https://vak.readthedocs.io/en/latest/get_started/autoannotate.html
How can I use my data with vak?
Please see the How-To Guides in the documentation here:
https://vak.readthedocs.io/en/latest/howto/index.html
Support / Contributing
For help, please begin by checking out the Frequently Asked Questions:
https://vak.readthedocs.io/en/latest/faq.html.
To ask a question about vak, discuss its development,
or share how you are using it,
please start a new "Q&A" topic on the VocalPy forum
with the vak tag:
https://forum.vocalpy.org/
To report a bug, or to request a feature,
please use the issue tracker on GitHub:
https://github.com/vocalpy/vak/issues
For a guide on how you can contribute to vak, please see:
https://vak.readthedocs.io/en/latest/development/index.html
Citation
If you use vak for a publication, please cite both the Proceedings paper and the software.
Proceedings paper (BiBTex)
@inproceedings{nicholson2023vak,
title={vak: a neural network framework for researchers studying animal acoustic communication},
author={Nicholson, David and Cohen, Yarden},
booktitle={Python in Science Conference},
pages={59--67},
year={2023}
}
Software
License
is here.
About
Are humans unique among animals?
We speak languages, but is speech somehow like other animal behaviors, such as birdsong?
Questions like these are answered by studying how animals communicate with sound.
This research requires cutting edge computational methods and big team science across a wide range of disciplines,
including ecology, ethology, bioacoustics, psychology, neuroscience, linguistics, and genomics 123.
As in many other domains, this research is being revolutionized by deep learning algorithms 123.
Deep neural network models enable answering questions that were previously impossible to address,
in part because these models automate analysis of very large datasets.
Within the study of animal acoustic communication, multiple models have been proposed for similar tasks,
often implemented as research code with different libraries, such as Keras and Pytorch.
This situation has created a real need for a framework that allows researchers to easily benchmark models
and apply trained models to their own data. To address this need, we developed vak.
We originally developed vak to benchmark a neural network model, TweetyNet 45,
that automates annotation of birdsong by segmenting spectrograms.
TweetyNet and vak have been used in both neuroscience 678 and bioacoustics 9.
For additional background and papers that have used vak,
please see: https://vak.readthedocs.io/en/latest/reference/about.html
"Why this name, vak?"
It has only three letters, so it is quick to type, and it wasn't taken on pypi yet. Also I guess it has something to do with speech. "vak" rhymes with "squawk" and "talk".
Does your library have any poems?
Contributors ✨
Thanks goes to these wonderful people (emoji key):





























This project follows the all-contributors specification. Contributions of any kind welcome!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vak-1.1.0.tar.gz.
File metadata
- Download URL: vak-1.1.0.tar.gz
- Upload date:
- Size: 1.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.32.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3d84176384c4825c0cd8186df4968b77e06d986efd217cea95c7481f93720fad
|
|
| MD5 |
38bf48accddf3499f54a600447c3c188
|
|
| BLAKE2b-256 |
0891c036d295be75691ab5dec3e770fd3937ceb85817111a0a7c76666997e161
|
File details
Details for the file vak-1.1.0-py3-none-any.whl.
File metadata
- Download URL: vak-1.1.0-py3-none-any.whl
- Upload date:
- Size: 258.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.32.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bd46776d2338a8868bd4496e6fabf55163d0618619c3619832fb0397e547ccdd
|
|
| MD5 |
87c8e5725a37214f0f935546bb94075a
|
|
| BLAKE2b-256 |
eef3147d38f50941c337329995b3b3439ac94377e958fab5e3cdf71c490a6e69
|







