Use Value Difference Metric to find distance between categorical features

Project description
vdm3
Value difference metric was introduced in 1986 to provide an appropriate distance function for symbolic attributes. It is based on the idea that the goal of finding the distance is to find the right class by looking at the following conditional probabilities.
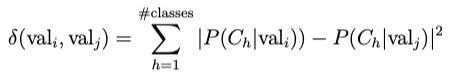
Then the distance is calculated by the k-norm, for instance k=2 will be the Euclidean norm:
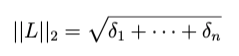
Install
pip install vdm3
Parameters:
ValueDifferenceMetric(X=X, y=y, continuous=None)
- X: ndarray, DataFrame, Series
- y: tuple, list, ndarray, Series
- continuous: tuple, list, ndarray, Series - the column index of continuous variables, if default, will assume all the columns are categorical
Attributes
cond_proba - the learned conditional probabilities
Method
get_distance(self, ins_1, ins_2, norm=2) - calculate the combined distance (categorical & continuous columns if any) between ins_1 and ins_2, with norm n. By default, n=2
Usage
Consider the following example:
>>> X = pd.DataFrame({'color':['White','Red','Black','Red','Red','White'], 'mpg':[23,28,32,42,40,20]})
>>> y = np.array(['van','sport','sport','sedan','sedan','van'])
Initiate the example by:
>>> case = ValueDifferenceMetric(X=X, y=y, continuous=[1])
>>> case.fit()
Get the vdm distance of two points by:
>>> one = np.array(['White',23])
>>> two = np.array(['Red',28])
>>> case.get_distance(ins_1=one, ins_2=two)
5.153208277913436
Return 0 if two points are the same:
>>> case.get_distance(ins_1=one, ins_2=one)
0.0
Work with other open-source packages
We can also use this package as a distance metric to work with other open-source packages, for instance scikit-learn.
In the next section, we will demonstrate a basic modeling example to embed vdm3 into scikit-learn nearest neighbors.
>>> from sklearn.datasets import load_boston
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.preprocessing import StandardScaler
We will load the Boston dataset, which contains 2 categorical features and 11 continuous features. The dependent variable is a continuous variable, in order to work with value difference metric, we will transform this problem from a regression problem to a classification problem by categorizing the dependent variable by the quantiles (0.25, 0.5, 0.75), i.e. the dependent variable will now be categorized to 1, 2, 3, and 4. Although, you may only do this process to calculate the VDM distance, and keep the overall problem as the original regression problem, to simply demonstrate the usage of this package, we will leave it as is.
# load data
>>> boston = load_boston(return_X_y=False)
# separate the data into X and y
>>> X = boston['data']
>>> y = boston['target']
# transform the y from continuous to categorical
>>> quantile = np.quantile(y, [0.25,0.5,0.75])
>>> def num_to_cat(quantile, input_):
""" use quantil to categorize continuous data
"""
if input_ <= quantile[0]:
return 0
elif input_ <= quantile[1]:
return 1
elif input_ <= quantile[2]:
return 2
else:
return 3
# the categorized y
>>> y_cat = [num_to_cat(quantile, i) for i in y]
We will then split the data into train and test set for a simple demonstration.
>>> X_train, X_test, y_train, y_test = train_test_split(X, y_cat, test_size=0.1)
Next, we will separate the categorical columns to normalized the continuous columns.
# index numbers for categorical and continuous columns
>>> cat_idx = [3,8]
>>> cont_idx = [i for i in range(X.shape[-1]) if i not in cat_idx]
# scale the continuous columns
>>> scaler = StandardScaler().fit(X_train[:,cont_idx])
>>> X_train_cont = scaler.transform(X_train[:,cont_idx])
>>> X_test_cont = scaler.transform(X_test[:,cont_idx])
# concatenate both types of data for model fitting
>>> X_train_n = np.concatenate([X_train_cont, X_train[:,cat_idx]], 1)
>>> X_test_n = np.concatenate([X_test_cont, X_test[:,cat_idx]], 1)
After processing the data, we will first need to initiate our VDM object.
# specific the continuous columns index
>>> vdm = ValueDifferenceMetric(X_train_n, y_train, continuous=[0,1,2,3,4,5,6,7,8,9,10])
>>> vdm.fit()
Our vdm method self.get_distance() will be used as a user defined distance function for scikit-learn neaerest neighbors.
Note that, since our data format issue, we cannot use some efficient solving algorithms, such as k-d-tree or ball tree. We will need to specify our algorithm to brute for a brute-force search.
>>> knn = KNeighborsClassifier(n_neighbors=3, metric=vdm.get_distance, algorithm='brute')
>>> knn.fit(X_train_n, y_train)
KNeighborsClassifier(algorithm='brute', leaf_size=30,
metric=<bound method ValueDifferenceMetric.get_distance of <__main__.ValueDifferenceMetric object at 0x11fb38198>>,
metric_params=None, n_jobs=None, n_neighbors=2, p=2,
weights='uniform')
>>> print(knn.score(X_test, y_test))
0.7843137254901961
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file vdm3-0.0.1.tar.gz.
File metadata
- Download URL: vdm3-0.0.1.tar.gz
- Upload date:
- Size: 5.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.2.0 requests-toolbelt/0.9.1 tqdm/4.35.0 CPython/3.7.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7feb1a297008fcfac0e43b2af5a34cc37b5a822ac349054e65ee034e7f6249c0
|
|
| MD5 |
76a844ac080dab2a2fef14773460ebfb
|
|
| BLAKE2b-256 |
0e24107664970d5d8894aa3ec94628ee56e9690eac507d558bb2ba49978eb401
|







