Tool for creating document features

Project description
Vectors of Locally Aggregated Concepts (VLAC)



Purpose
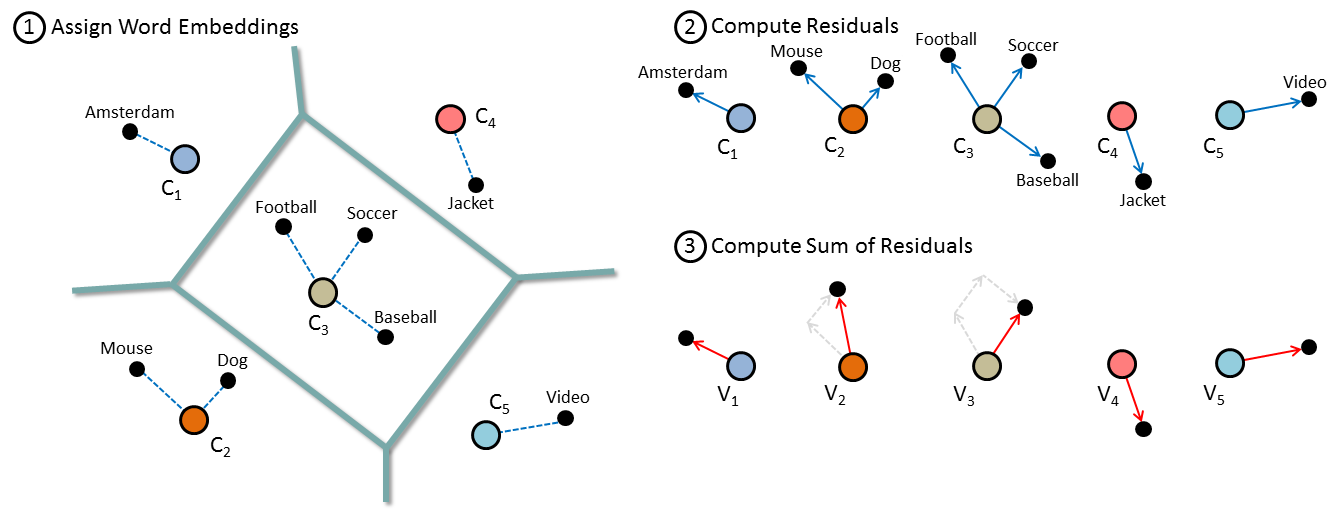
As illustrated in the Figure below, VLAC clusters word embeddings to create k concepts. Due to the high dimensionality of word embeddings (i.e., 300) spherical k-means is used to perform the clustering as applying euclidean distance will result in little difference in the distances between samples. The method works as follows. Let wi be a word embedding of size D assigned to cluster center ck. Then, for each word in a document, VLAC computes the element-wise sum of residuals of each word embedding to its assigned cluster center. This results in k feature vectors, one for each concept, and all of size D. All feature vectors are then concatenated, power normalized, and finally, l2 normalization is applied. For example, if 10 concepts were to be created out of word embeddings of size 300 then the resulting document vector would contain 10 x 300 values.
Usage
Tested in python 3.5.4.
# Train model and transform collection of documents
vlac_model = VLAC(documents=train_docs, model=model, oov=False)
vlac_features, kmeans = vlac_model.fit_transform(num_concepts=30)
# Create features new documents
vlac_model = VLAC(documents=train_docs, model=model, oov=False)
test_features = vlac_model.transform(kmeans=kmeans)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vlac-0.1.2.5.tar.gz.
File metadata
- Download URL: vlac-0.1.2.5.tar.gz
- Upload date:
- Size: 3.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/3.7.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5390d4f8b554e10eddb45a41ea774711bf5f6c1c21fb58206571a6a2cf933161
|
|
| MD5 |
f7b5c203c523f1671918635208259f0c
|
|
| BLAKE2b-256 |
fe94de8061646846aa96929685a0a499c44e4ec400079f9b11088f069e1e3567
|
File details
Details for the file vlac-0.1.2.5-py3-none-any.whl.
File metadata
- Download URL: vlac-0.1.2.5-py3-none-any.whl
- Upload date:
- Size: 7.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/3.7.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
949ba13018a9836f7bb73ce43c1bc7f75f2b7c55b3cb1222e4bbf3cf872fc995
|
|
| MD5 |
39bea7f235755cb81bac6250d0248bac
|
|
| BLAKE2b-256 |
68a5f0059f6c080eb18471b0bff13f828406d10b3a07c26bb93b578ee26f7561
|







