Watermill data stream organizing framework.

Project description
Watermill data stream organizing framework
Assume that you have numerous stream data producers and processors. If data streams are logically linked together you may want to organize processing of joined data stream. Watermill helps to get streams joined in a clear, lightweight way.
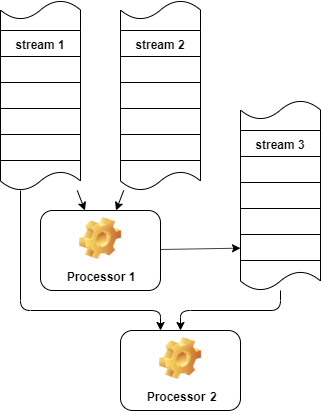
User guide
Briefly
Input data stream is configured using processing function signature.
def calculate_robot_speed(
prev_location: RobotLocation,
next_locations: Mapping[RobotLocation, List[RobotLocationNextStep]]
) -> RobotSpeed:
pass
First argument can have type of data stream element or list of stream elements.
Subsequent arguments are mapping of types of stream elements when using stream joins. In the example above we want to get all robot locations joined with joined locations of the next time step.
If there is no result data stream simply omit return value or explicitly specify NoReturn type.
If you want to return several results for every processing function call you can return generator. Note that you have to yield at least one valid element when returning generator.
Data themselves can be stored in any shared storage like Kafka, file system, databases.

Watermill doesn't introduce any dependency/coupling between services based on it. Every service or simply process can independently decide which actual data stream it wants to input and how to join data streams together. The only shared key of data streams is file name of file in FS, topic name for Kafka, etc.
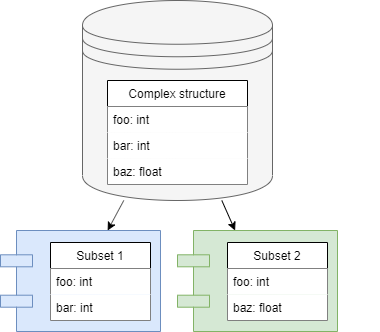
Smallest piece of data of which data streams consists is dictionary. To describe data stream elements in code python dataclasses are used.
Very often you have to get reference to external objects in the processing function. Dependency injection is used for that. It is enough to specify an argument with the type of the required object in the processing function and DI will provide this argument with reference to the object.
def store_robot_path(location: RobotLocation, db_connection: Connection) -> NoReturn:
pass
Message brokers are used to access to streams data in storages. Watermill package includes two commonly used brokers. JSON file broker and Kafka message broker. Both of them can use default serializers and deserializers. Moreover Watermill users can implement deserializers that receive only the required fields.
Stream joins
For the simplest case when there is only one data stream data processing function looks like
def is_inside_area(location: RobotLocation) -> InsideArea:
return InsideArea(
x=location.x,
y=locatin.y,
inside=check_inside_area(location.x, location.y)
)
But usually there are several input data streams that should be combined by some condition.
Here 2 data streams are joined and falls into the processing function as combined elements.
For example join condition can be audio_stream.frame_index = video_stream.frame_index.
In the code it looks like
def merge_audio_video(
audio_frame: AudioFrame,
video_frames: Mapping[AudioFrame, List[VideoFrame]]
) -> AudioVideoFrame:
pass
The first argument describes left data stream in the join and is called the master stream.
Iterating over the master stream returns every element just once. Elements from secondary streams can be skipped if join condition is not met.
Unlike SQL joins Watermill supports only inner joins. So if there are no matching data in secondary streams there will be no data at all for the processing. Furthermore, if there are no data at all in secondary streams the processing function will never be executed.
It may be easier to understand streams join if you thing about join tree with a master stream as the root node. To get next data for processing Watermill goes through the join tree and returns linked streams elements only when there is at least one element found for each join tree node. As can be seen from the processing function signature secondary streams can return more than one element.
Join tree can have no loops or duplicate nodes.
End of stream
Stream elements are processed until there are elements in every input stream.
This is quite simple to understand where the data stream for files in file system ends. But originally indefinite
data streams like Kafka or RabbitMQ should be provided with some End Of Stream mark explicitly.
KafkaMessageBroker supports special type of elements EndOfStream defined in message_brokers.message_broker module.
Data stream processing is immediately stopped as soon as EndOfStream message appears in any of joined data streams.
EndOfStream message is then automatically put to output stream to state that there will be no more data.
You can also manually return instance of EndOfStream dataclass from the processing function
to indicate that processing loop should be stopped. EndOfStream is allowed to be the last element of yielded by
processing function generator.
Join conditions
When joining streams join condition is evaluated for left and right elements.
Every element must consist of key. It can be ordinary field of expression based on one or more fields. Join conditions are defined as a parameter to Watermill constructor.
The following examples demonstrates how to join streams based on conditions with expressions.
@dataclass
class AudioFrame:
time_seconds: int
data: float
@dataclass
class VideoFrame:
time_ms: int
data: float
frame_index: int
first_frame_ts_seconds: int
...
mill = WaterMill(
...
process_func=merge_audio_video,
join_tree=join_streams(
AudioFrame,
JoinWith(
with_type=VideoFrame,
left_expression=get_field('time_seconds'),
right_expression=get_field('time_ms') // 1000
)
)
)
mill = WaterMill(
...
process_func=merge_audio_video,
join_tree=join_streams(
AudioFrame,
JoinWith(
with_type=VideoFrame,
left_expression=get_field('time_seconds'),
right_expression=
get_field('frame_index') * FRAME_DURATION_SECONDS +
get_fields('first_frame_ts_seconds')
)
)
)
Expressions calculation implementation is trivial and does not support operator precedence or parentheses.
Computed key value for every stream must increase monotonously. Based on this rule Watermill can detect streams divergence. For example at the start of data processing left (master) stream key less than right (secondary) stream key. In this case Watermill will skip right stream elements until stream elements synchronizes.
During data streams design you should keep in mind key comparison rules to correctly identify what the key will be for every data stream.
Special case for joining streams is when the stream appears in join tree several times, e.g. self-join of the stream. In this case separate class have to be defined for every join tree node of this stream type. Refer to kafka_join_streams example.
Windows
Sometimes you may want to get master stream elements combined into lists based on some condition before processing. For example collect one minute statistics and then process whole bunch of elements at once. Thus processing function will get list of elements every time. Below is the illustration of appropriate stream configuration.
def calculate_robot_speed(prev_location: List[RobotLocation]) -> RobotSpeed:
pass
...
mill = WaterMill(
...
process_func=calculate_robot_speed,
stream_cls = window(
cls=RobotLocation,
window_expression=get_field('time') // 30
)
)
Notice the additional List type hint in the processing function and call to window function that returns
special Window object. window_expression field of Window is key-based expression that distinguish elements
of adjacent windows.
In the same way windowing is configured:
def calculate_robot_speed(
prev_location: List[RobotLocation],
next_locations: Mapping[RobotLocation, List[RobotLocationNextStep]]
) -> RobotSpeed:
pass
...
mill = WaterMill(
...
process_func=calculate_robot_speed,
join_tree=join_streams(
window(
cls=RobotLocation,
window_expression=get_field('time') // 30
),
JoinWith(
with_type=RobotLocationNextStep,
left_expression=get_field('time') + 10,
right_expression=get_field('time')
),
)
)
Element-based window expressions may be not sufficient. E.g. processing function should receive list of all elements
arrived in every 20 seconds. Default configuration of Kafka message broker is blocking. It means that if there are
no new messages in the topic then window expression checking time elapsed will not be called at all.
To let Watermill periodic call of window expression poll_timeout of KafkaMesasgeBroker construction should be set
to appropriate value. Such data stream windowing has two limitations:
- there must be only one (master) stream;
- window expression must be able to deal with
Nonevalues which are passed to it on poll timeouts.
Message brokers
Watermill includes the following message brokers:
-
JsonFileMessageBroker
Reads whole input files into memory and provide Watermill with data elements. Writes output stream elements into file at the end of stream.
Files contents is JSON list of objects.
JsonFileMessageBrokerconfiguration is quite obvious:JsonFileMessageBroker({ GoodsItem: Path('/samples/goods.json') })
The only constructor argument is element type — file path mapping.
This broker should not be used if files are very big.
-
KafkaMessageBroker
This broker uses
kafka-pythoninternally to communicate with Kafka.Every data stream is topic. There is no limitation on topic naming due to explicit element type — topic name mapping:
KafkaMessageBroker( topic_names={ RobotLocation: 'robot-locations', RobotLocationNextStep: 'robot-locations', RobotSpeed: 'robot-speed', }, kafka_url='kafka:9092' )
When using
KafkaMessageBrokerdata stream positions are automatically saved. So whenever the processing service crashes and restarts it continues processing from the same data streams positions.KafkaMessageBrokercreates consumer for every join tree node with dedicated consumer group with name based on element class name. So positions for every data stream is saved (committed) individually.
Logging
Watermill utilizes common logging configuration pattern:
logger = getLogger(__name__)
So you can easily change Watermill logger parameters based on logger prefix 'watermill'.
Multiple Watermill instances
Watermill processing loops can be safely run in separate threads.
Note that Watermill was not designed to be thread-safe and should not be accessed from different threads.
Code examples
Basic usage examples can be found in repository: Examples
Watermill benefits
- tiny amount of user code necessary to organize data stream processing;
- rapid and safe streams join configuration and reconfiguration
- every Watermill-based service independently specifies its input, output streams
- explicit typed processing function interface
- stream data structure is defined by pure dataclasses
- Watermill loop does not keep streams data in memory
- end of streams are always explicit
- failsafe:
- Watermill brokers can be configured to raise EndOfStream by data timeout;
- Watermill-based service crashes and restarts do not cause data loss/duplication or state corruption when using Kafka message broker.
- rich join functionality allows to build self-joins where the data stream is joined with itself
- dependency injection allows to add side-effects to processing functions
- streams misalignment is automatically eliminates using join conditions
- straightforward message brokers interface encourage to implement own specific brokers
Caveats and limitations
- Lack of stream state saving transactionality when using Kafka message broker.
Watermill saves topics position every time after outputting processing result.
In the case of process crash between result and state save there will be generated result data duplicate.
It will be improved after
python-kafkaclient is support exactly-once guarantee Kafka API. - When using Watermill in python3.6 you have to add
dataclassespackage manually to project requirements. - Kafka topics have to be created manually.

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file watermill-3.6.7.tar.gz.
File metadata
- Download URL: watermill-3.6.7.tar.gz
- Upload date:
- Size: 23.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.24.0 setuptools/47.3.1 requests-toolbelt/0.9.1 tqdm/4.46.1 CPython/3.7.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2691d131e01c03d3dff874df8c2d3a6bc288cbb63295f9e81390f74705acce77
|
|
| MD5 |
9f33ce8f07e06382577a5c255fb1bcbc
|
|
| BLAKE2b-256 |
9e714fc3f210341016697bf89df9fea77170b71937be109f9e51ea2edba993b0
|
File details
Details for the file watermill-3.6.7-py3-none-any.whl.
File metadata
- Download URL: watermill-3.6.7-py3-none-any.whl
- Upload date:
- Size: 38.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.24.0 setuptools/47.3.1 requests-toolbelt/0.9.1 tqdm/4.46.1 CPython/3.7.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4205e0ea972397a41f55d2dbab42168b905b1f0a7d630beca82127844c41cbdd
|
|
| MD5 |
84dcc7480a4152abaca6adb47a64f408
|
|
| BLAKE2b-256 |
7ec4ae23d0ec875a2154e8c79bc41099747c25ef15e9d320870d09d2e0dc2cc3
|







