A tool to separate truncated text.

Project description
Word Slicer
Cut your unspaced (or 'too spaced') long texts.
Usage
import wordslicer
model = wordslicer.train('train_file')
text = open('input_file', 'r').read()
text = wordslicer.separate(model, text) # or wordslicer.join(model, text)
save('output_file', text)
Performance
For an input of:
- 161029 words to train
- 1000 lines to separate
The results:
- Text with 36889 words
- Time: real 0m1,368s
Example:
>>> wordslicer.separate(model, "Boromirhesitatedforasecond.'Yes,andno,'heansweredslowly.'Yes:Ifoundhimsomewayupthehill,andIspoketohim.IurgedhimtocometoMinasTirithandnottogoeast.Igrewangryandheleftme.Hevanished.Ihaveneverseensuchathinghappenbefore.thoughIhaveheardofitintales.HemusthaveputtheRingon.Icouldnotfindhimagain.Ithoughthewouldreturntoyou.'")
Boromir hesitated for a second. 'Yes, and no,' he answered slowly. 'Yes: I found him some way up the hill, and I spoke to him. I urged him to come to Minas Tirith and not to go east. I grew angry and he left me. He vanished. I have never seen such a thing happen before. though I have heard of it in tales. He must have put the Ring on. I could not find him again. I though the would return to you.'
How to Install
pip3 install wordslicer
Features
-
Train your model: with the training ability, this package works with every language.
-
Evaluate your model: check if your training text is good enough for your input text:
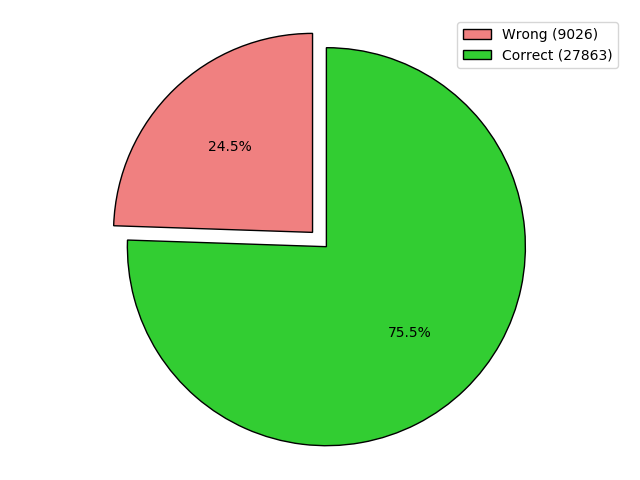
Credits
This project was inspired by Generic Human on http://stackoverflow.com/a/11642687/2449774 . Thank you!
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file wordslicer-0.1.0.tar.gz.
File metadata
- Download URL: wordslicer-0.1.0.tar.gz
- Upload date:
- Size: 3.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.1.0 requests-toolbelt/0.9.1 tqdm/4.41.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
15f361af0481143761646b1fdab12a32370a97ab44f34b4334d1a07ef6a850b0
|
|
| MD5 |
b08f1c52216fb5fb950a2f1d6b2fe879
|
|
| BLAKE2b-256 |
282ac9286dd407c1d487b0e0257b7e56962995a11e0188ed4861be05a3f8f8cc
|
File details
Details for the file wordslicer-0.1.0-py3-none-any.whl.
File metadata
- Download URL: wordslicer-0.1.0-py3-none-any.whl
- Upload date:
- Size: 4.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.1.0 requests-toolbelt/0.9.1 tqdm/4.41.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d3ca32bac7e82414ee793b7081fc99cf4d14fcfde49c05e4795aa0e47b61dd71
|
|
| MD5 |
62fcc0372a8ac7914b6a46fd76cb0b45
|
|
| BLAKE2b-256 |
6265f5d4244a68a7e1044324f7f41dc32af273d180a37bbb030f2476e89b81f1
|







